
请我喝杯咖啡☕
*备忘录:
有批量梯度下降(BGD)、小批量梯度下降(MBGD)和随机梯度下降(SGD),它们是如何从数据集中获取数据使用梯度下降的方法PyTorch 中的优化器,例如 Adam()、SGD()、RMSprop()、Adadelta()、Adagrad() 等。
*备忘录:
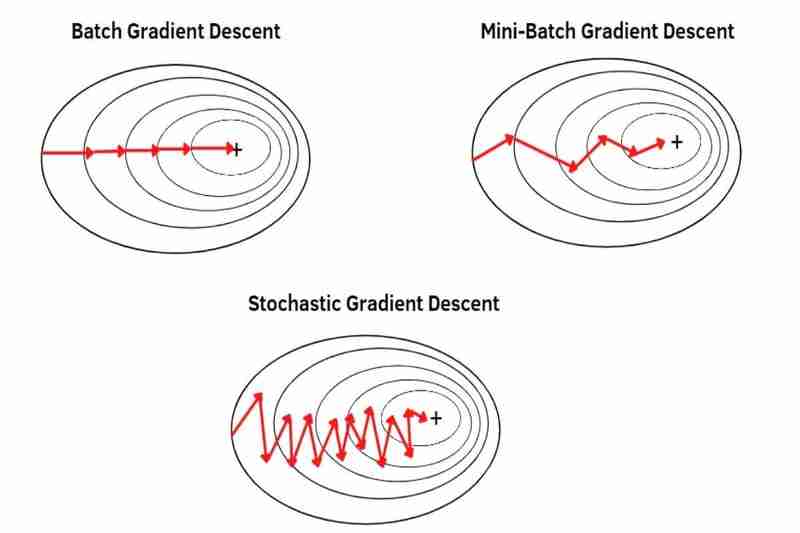
(1)批量梯度下降(BGD):
(2)小批量梯度下降(MBGD):
使用从整个数据集中分割出来的每个小批次的平均值,因此每个样本比 BDG 更突出(更强调)。 *将整个数据集分成更小的批次可以使每个样本越来越突出(越来越强调)。因此,收敛比 BGD 更不稳定(更波动),而且噪声(噪声数据)也比 BGD 弱,比 BGD 更容易导致过冲,并且即使没有陷入局部极小值,也会创建比 BGD 更不准确的模型,但MBGD 比 BGD 更容易逃脱局部最小值或鞍点,因为正如我之前所说,收敛比 BGD 更不稳定(更波动),MBGD 比 BGD 更不容易导致过度拟合,因为每个样本比 BGD 更突出(更强调),因为我之前说过。
的优点:
的缺点:
(3) 随机梯度下降(SGD):
使用整个数据集的每一个样本逐个样本而不是平均值,因此每个样本比 MBGD 更突出(更强调)。因此,收敛比 MBGD 更不稳定(更波动),并且噪声(噪声数据)也比 MBGD 弱,比 MBGD 更容易导致过冲,并且即使没有陷入局部极小值,也会创建比 MBGD 更不准确的模型,但SGD 比 MBGD 更容易逃脱局部最小值或鞍点,因为正如我之前所说,收敛比 MBGD 更不稳定(更波动),并且 SGD 比 MBGD 更不容易导致过度拟合,因为每个样本比 MBGD 更突出(更强调),因为我之前说过。
的优点:
的缺点:
以上就是批量、小批量和随机梯度下降的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告![ThinkPHP5快速开发企业站点[全程实录]](https://img.php.cn/upload/course/000/000/068/6253d918a3ce7278.png)


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号




 814
814























