
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

马里兰大学与微软研究院合作推出了一种新型多模态大语言模型Florence-VL,该模型利用生成式视觉编码器Florence-2,显著提升了对图像中细节信息的理解能力。 这项研究由马里兰大学博士生陈玖海领衔,Bin Xiao担任通讯作者,并由马里兰大学助理教授Tianyi Zhou以及微软研究院研究员Jianwei Yang, Haiping Wu, Jianfeng Gao共同完成。

资源链接:
Florence-VL的核心在于采用Florence-2作为视觉编码器。不同于传统的CLIP等模型仅提供单一全局图像表示,Florence-2通过生成式预训练,能够根据不同的任务提示生成多样化的视觉特征,从而更全面地理解图像细节,包括局部信息和像素级信息。 Florence-VL巧妙地利用多个任务提示(例如图像描述、OCR和物体定位),并融合不同深度层的特征,实现了更强大的视觉理解能力。
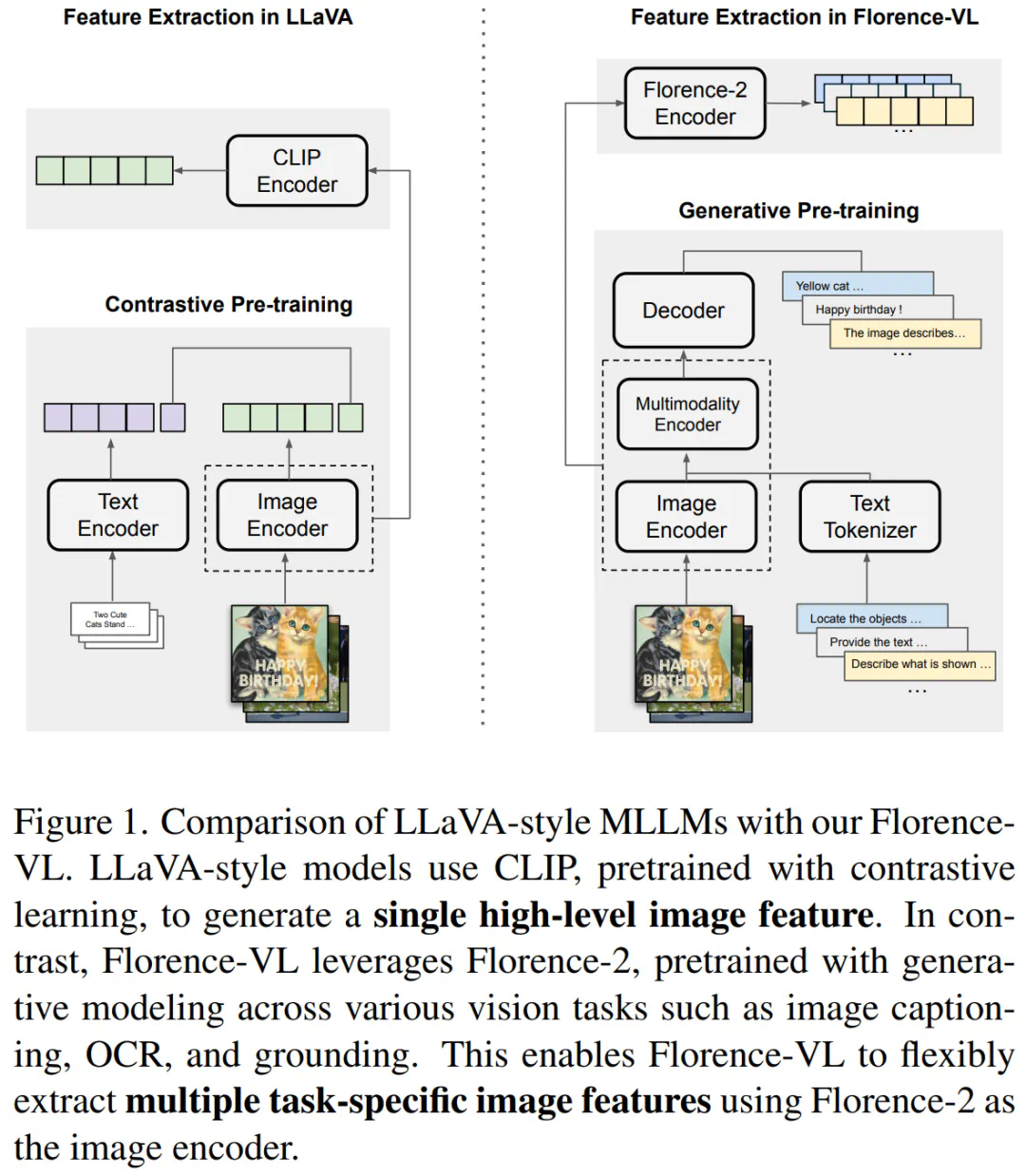
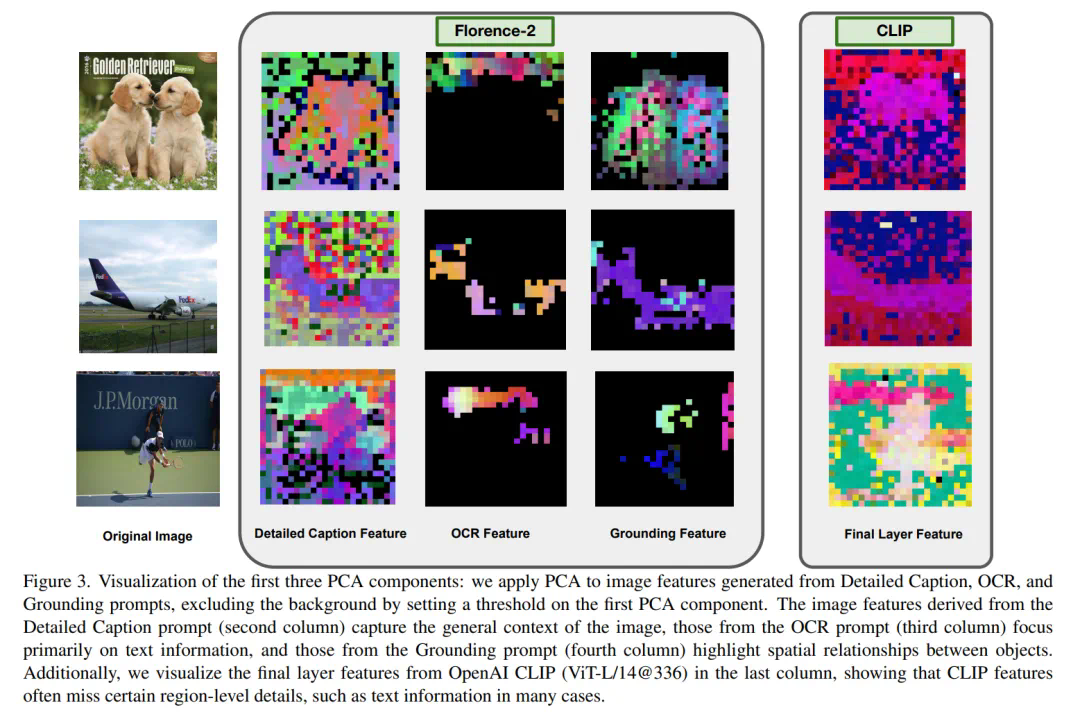
核心技术:深度-广度融合策略 (DBFusion)
Florence-VL的创新之处在于其深度-广度融合策略,它有效地结合了多任务提示和多层级特征,以获得更丰富的视觉表征:

实验结果与对比
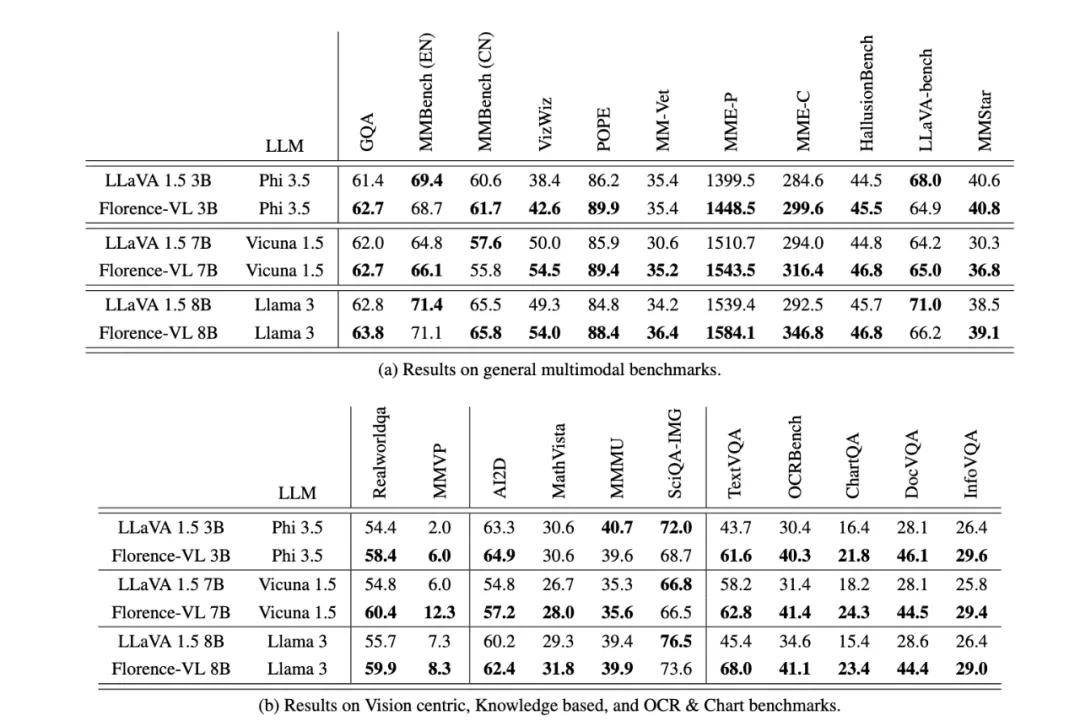
研究团队通过一系列实验,在多个多模态基准任务上评估了Florence-VL的性能,包括通用视觉问答、OCR、知识理解等。结果显示,Florence-VL在多个任务上超越了基于CLIP等传统视觉编码器的模型,尤其在文本提取任务上表现突出。消融实验也证明了Florence-2作为视觉编码器的优越性。
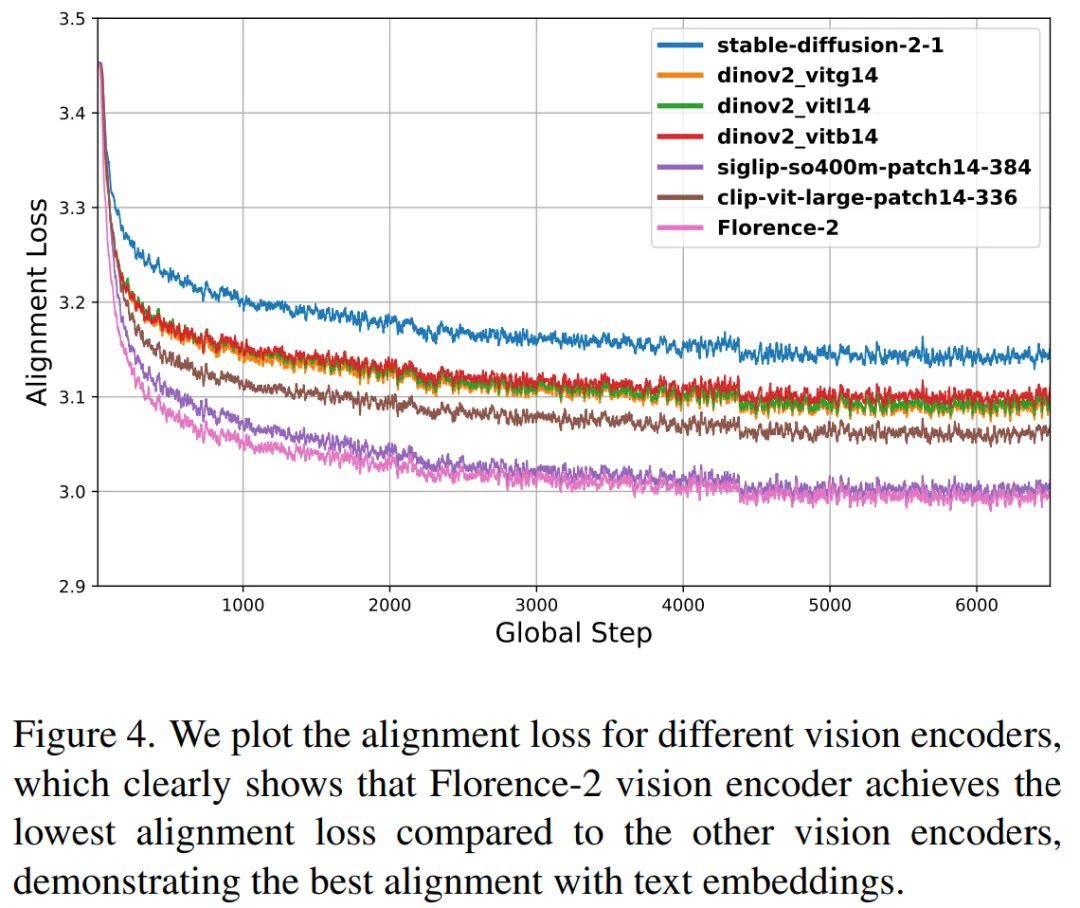
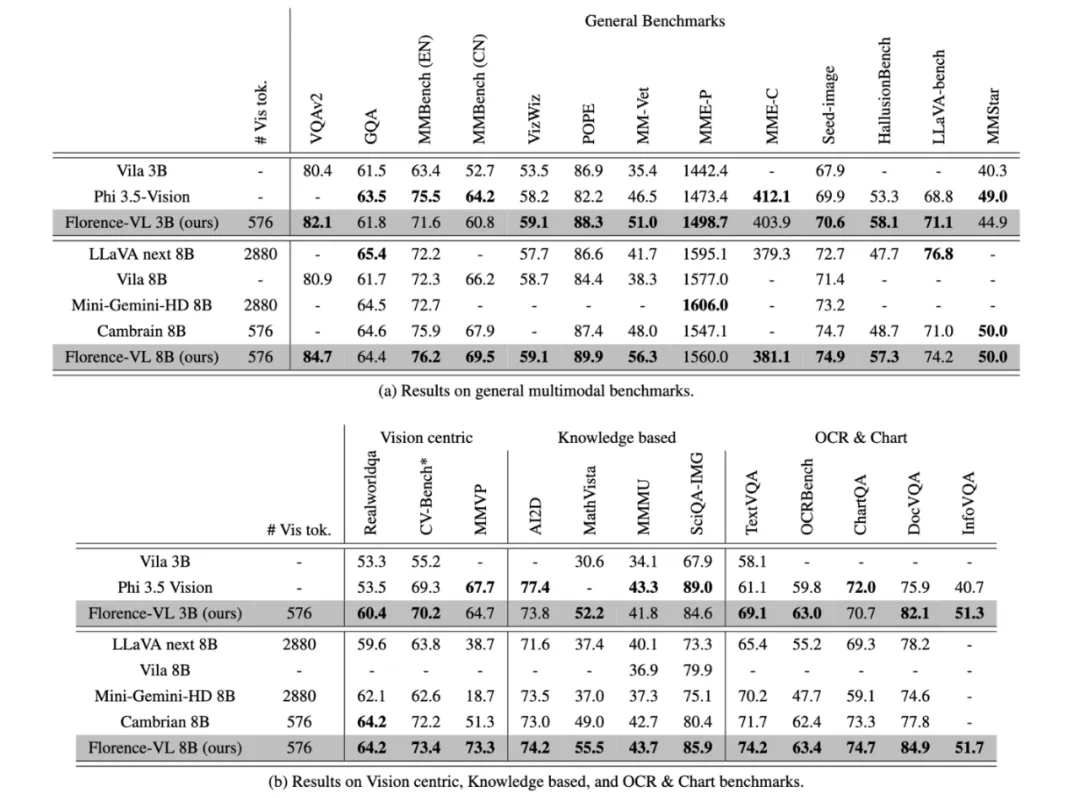
总结与展望
Florence-VL凭借其创新的生成式视觉编码器和深度-广度融合策略,在多模态大语言模型领域取得了显著进展。未来研究方向包括探索更先进的自适应融合策略,以根据不同任务动态调整特征融合的策略。
(脚注:[1] https://www.php.cn/link/3f26de5213216fe4c8a797b1ad68d771)
以上就是Florence-VL来了!使用生成式视觉编码器,重新定义多模态大语言模型视觉信息的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 270
270




















