
清华大学陈键飞团队推出sageattention2:实现4-bit即插即用注意力机制,显著提升大模型推理速度
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏持续报道全球顶尖AI研究成果。 近年来,该专栏已发表2000余篇学术技术文章,涵盖众多高校和企业实验室的先进研究。 欢迎优秀研究者投稿或联系报道 (邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com)。
论文共同一作张金涛和黄浩峰分别来自清华大学计算机系和交叉信息研究院,通讯作者陈键飞副教授及其他合作者均来自清华大学计算机系。
大模型线性层的低比特量化已日趋成熟,但注意力模块仍普遍采用高精度计算(如FP16或FP32),尤其在长序列处理中,注意力机制的计算成本日益突出。
此前,陈键飞团队提出的8-bit即插即用注意力机制SageAttention (https://www.php.cn/link/8928157317a66f146e4f2d5617537336),通过将QK^T量化至INT8,保持PV精度为FP16,并结合Smooth K技术,实现了2倍于FlashAttention2的速度提升,同时保持了端到端精度。SageAttention已广泛应用于CogvideoX、Mochi、Flux、Llama3、Qwen等开源及商业大模型。
最新研究成果SageAttention2进一步将注意力机制量化至4-bit,相较于FlashAttention2和xformers分别实现了3倍和4.5倍的即插即用推理加速,并同样在各种大模型上保持了端到端精度。

即插即用特性
SageAttention2提供高效的注意力算子,实现即插即用加速。 只需输入Q, K, V矩阵,即可快速获得注意力输出(O)。 克隆仓库 (git clone https://www.php.cn/link/b0263bc40e0ff50f481b85a968c30ac1) 并执行 python setup.py install 后,一行代码即可替换模型中的注意力函数:
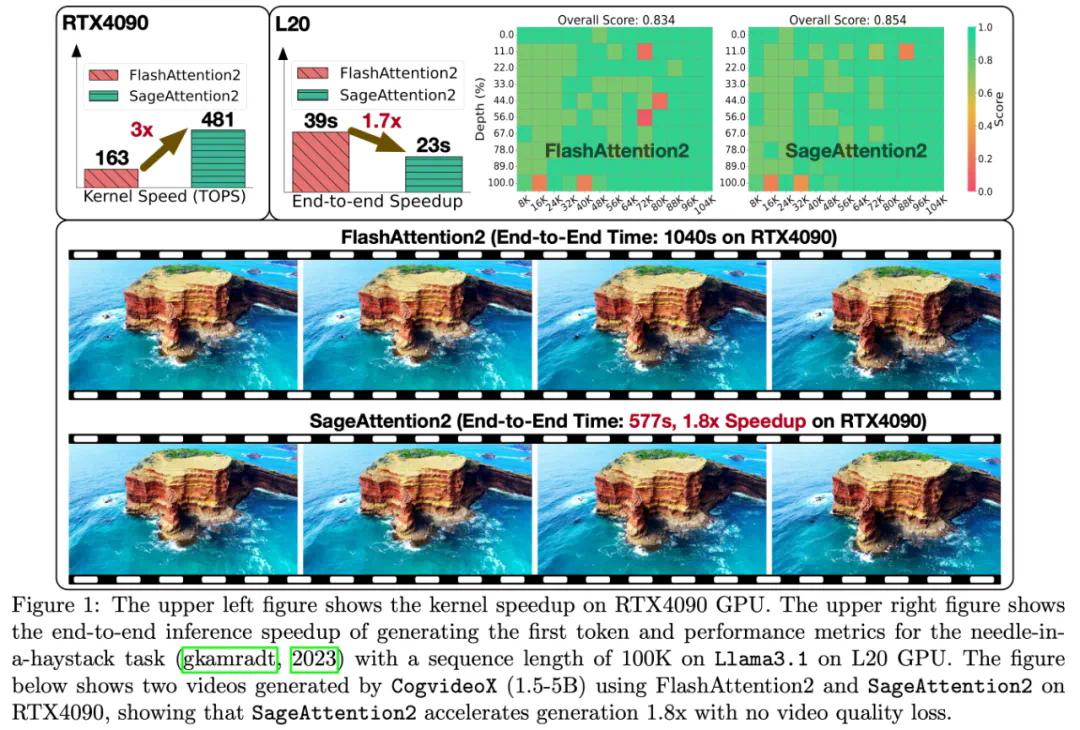

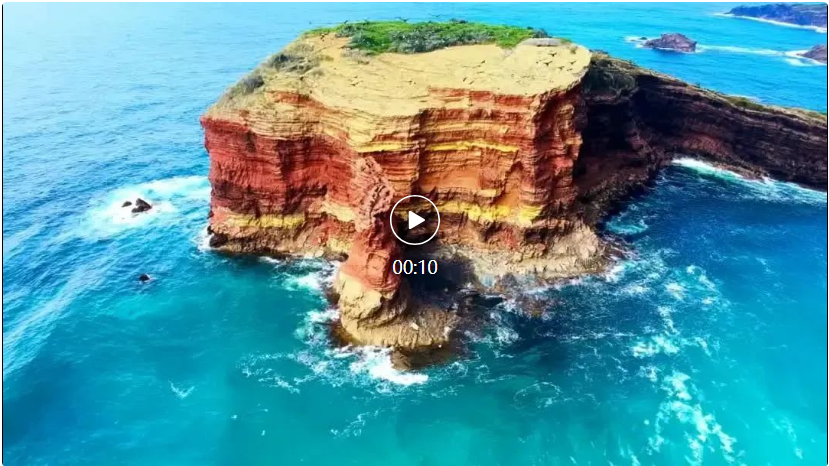
以CogvideoX-1.5-5B为例,SageAttention2实现了1.8倍的端到端加速,且视频生成质量无损:
 全精度 Attention
全精度 Attention
 SageAttention2
SageAttention2
SageAttention2还扩展了硬件支持,在不同GPU平台上均有显著加速效果。
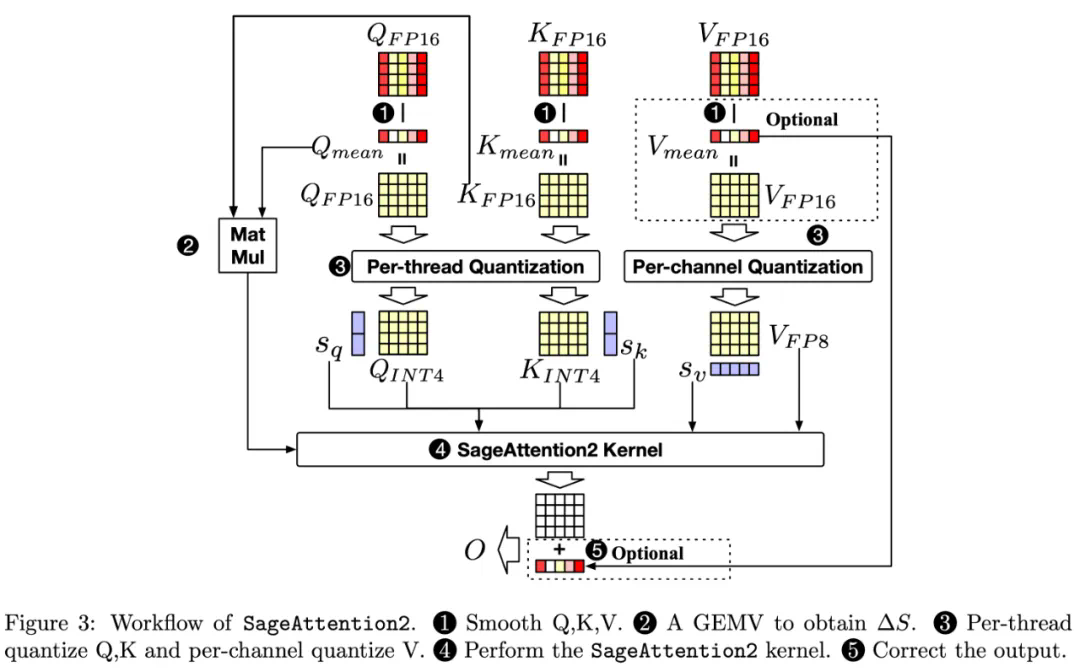
(后续内容,由于篇幅限制,此处省略对前言、挑战、技术方案和实验效果的详细描述,但图片链接保留,读者可自行参考原文深入了解。)
(此处保留原文中所有图片链接)
以上就是4比特量化三倍加速不掉点!清华即插即用的SageAttention迎来升级的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 549
549



















