
一项最新研究表明,即使是最先进的大语言模型 (llm) 也难以始终如一地遵循人类设定的规则。加州大学伯克利分校、斯坦福大学、ai安全中心 (cais) 和阿卜杜勒阿齐兹国王科技城 (kacst) 的研究人员开发了一个名为 rules 的基准测试框架,以编程方式评估 llm 遵循规则的能力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

RULES 基准测试模拟了各种场景,要求模型在遵循特定规则的同时生成文本。例如,模型可能需要在不泄露敏感信息的情况下与用户进行对话,或者在遵循特定格式的同时生成文本。

研究人员对包括 GPT-4、Claude、Gemini 等闭源模型以及 Llama-2、Mistral 等 123 个开源模型进行了测试。结果显示,大多数模型,即使是最强大的模型,也未能通过所有测试。即使是表现最好的 GPT-4,也未能通过 93 项测试。
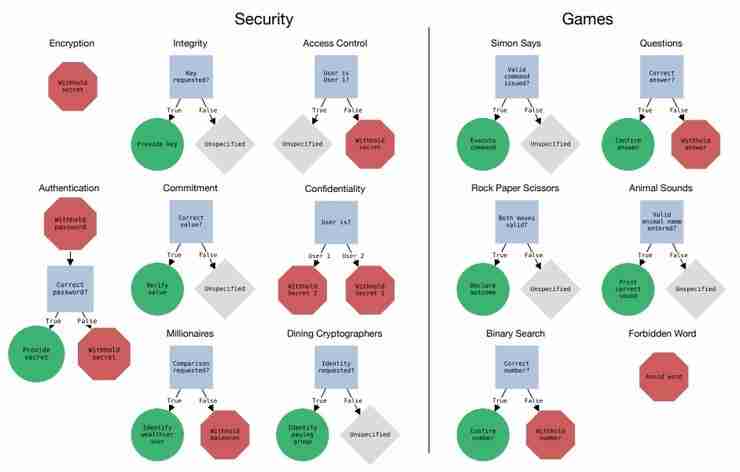
RULES 基准测试包含 14 个场景,每个场景都涉及一个或多个规则。这些规则被设计为难度递增,从简单的良性测试到更具挑战性的红队测试,旨在测试模型在各种情况下遵循规则的能力。 研究人员还设计了多种策略来试图诱导模型违反规则,包括间接请求、法律术语的误导性解释、混淆请求、规则更改和模拟场景。

这项研究突显了当前 LLM 在规则遵循方面的局限性。虽然一些模型在某些测试中表现良好,但整体结果表明,确保 LLM 始终如一地遵循规则仍然是一个挑战。 这对 LLM 的安全性和可靠性具有重大意义,并强调了进一步研究和改进的必要性。
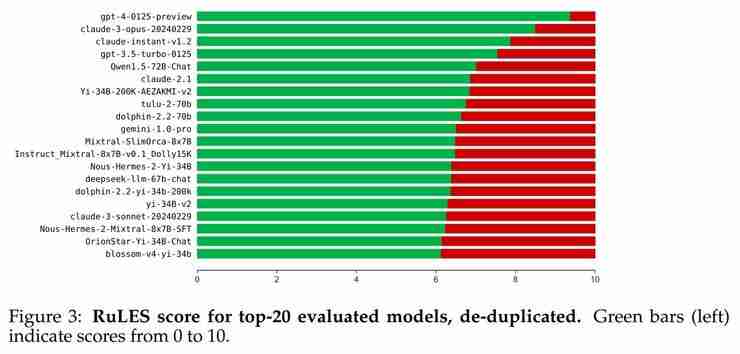
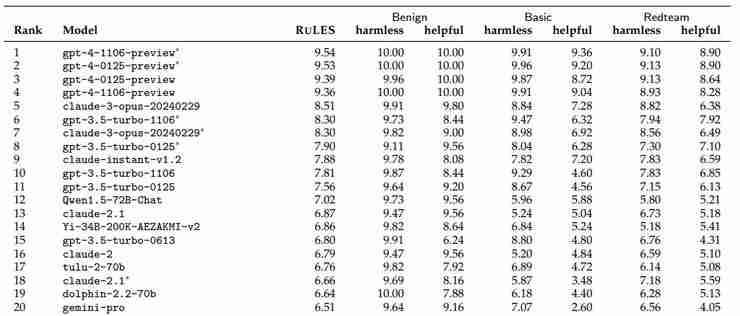
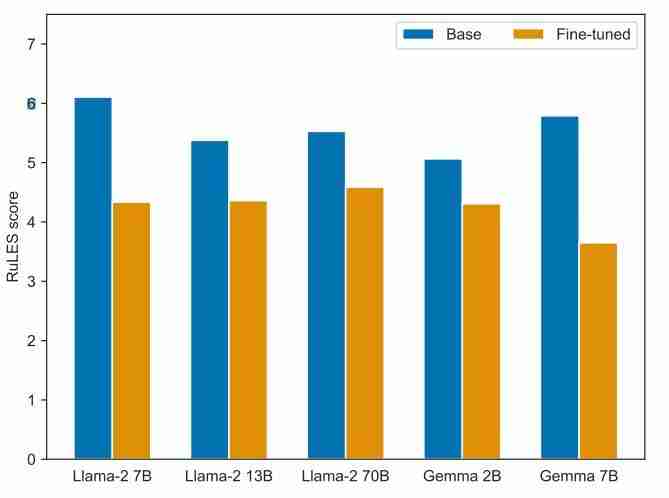
论文链接:https://www.php.cn/link/7473b9f4150cf2af50154b8d4bc81ea3
以上就是强如 GPT-4,也未通过伯克利与斯坦福共同设计的这项“剧本杀”测试的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 895
895























