
moe架构:大模型训练的未来方向?
MoE(Mixture of Experts,混合专家)架构在大模型训练和推理中的应用,引发了业界对其未来发展方向的广泛讨论。本文将深入探讨MoE架构的优势、挑战以及在行业中的应用现状。
MoE的核心在于其模块化的稀疏激活机制。不同于OpenAI的GPT系列和Meta的Llama系列等稠密模型(所有参数都参与计算),MoE模型仅激活部分参数(“激活参数”),从而降低计算成本。 MoE通常基于Transformer架构,通过对前馈神经网络(FFN)层进行横向扩展,将其参数划分成多个“专家”(expert)组。一个路由器(Router)网络根据输入动态选择激活哪些专家。
Mistral AI去年底开源的Mixtral 8x7B模型,以其媲美GPT-3.5和Llama 2 70B的性能,却仅消耗13B稠密模型的计算量,为MoE架构带来了巨大关注。此后,MiniMax、昆仑万维、xAI、阶跃星辰、阿里巴巴、元象科技、面壁智能以及DeepSeek AI等国内外厂商纷纷推出基于MoE架构的大模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
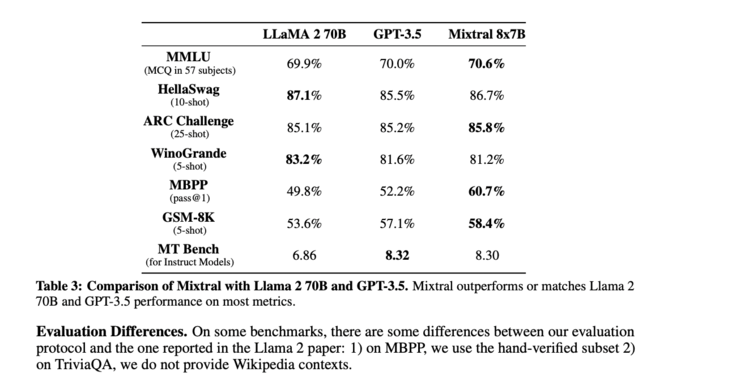
MoE的兴起,很大程度上源于算力瓶颈。 遵循Scaling Law(模型越大,性能越强),大模型参数量不断增长,对算力的需求也随之激增。MoE架构通过稀疏化,在扩大模型参数规模的同时,显著降低计算成本,成为应对算力短缺的有效方案。 早在2017年,MoE已在LSTM模型中得到应用,但直到Mistral AI的开源,才真正推动MoE在大模型领域的广泛应用。
阶跃星辰、元象科技等公司在早期就已关注MoE,并将其应用于千亿甚至万亿参数模型的训练。面壁智能,作为国内最早关注MoE的团队之一,也持续深耕该领域。
MoE的优势在于其专家化、动态化和稀疏化特性:
然而,MoE架构的选择路径并非唯一。目前主要有两种方案:
目前,大部分厂商选择Upcycle方法,而DeepSeek AI则选择从头训练。 此外,专家数量、激活专家数量、共享专家的存在与否等细节,各家厂商也有不同选择。DeepSeek AI的模型通过更细粒度的专家划分和引入共享专家,提升了模型表达能力。元象科技则根据实验结果,采用非标准FFN的专家设计。

尽管MoE架构具有诸多优势,但它也并非完美无缺。 MoE模型的训练和推理难度较大,专家之间的不平衡性可能影响效率。 此外,MoE模型的内存消耗仍然较高,限制了其在端侧部署的应用。 Meta选择继续使用稠密模型的Llama 3也表明,在算力充足的情况下,稠密模型仍然具有优势。

总而言之,MoE架构并非大模型训练的终极解决方案,而是在算力受限条件下的一个有效权衡。 未来,优化MoE架构的训练和推理效率,降低内存消耗,以及探索更细粒度的稀疏化方法,将是重要的研究方向。 数据质量和训练技巧也对MoE模型的最终性能至关重要。 虽然MoE的未来仍存在不确定性,但在当下,它无疑是许多企业在追求Scaling Law的同时,不得不做出的选择。
以上就是MoE 高效训练的 A/B 面:与魔鬼做交易,用「显存」换「性能」的详细内容,更多请关注php中文网其它相关文章!

 C++高性能并发应用_C++如何开发性能关键应用
C++高性能并发应用_C++如何开发性能关键应用
 Java AI集成Deep Java Library_Java怎么集成AI模型部署
Java AI集成Deep Java Library_Java怎么集成AI模型部署
 Golang后端API开发_Golang如何高效开发后端和API
Golang后端API开发_Golang如何高效开发后端和API
 Python异步并发改进_Python异步编程有哪些新改进
Python异步并发改进_Python异步编程有哪些新改进
 C++系统编程内存管理_C++系统编程怎么与Rust竞争内存安全
C++系统编程内存管理_C++系统编程怎么与Rust竞争内存安全
 Java GraalVM原生镜像构建_Java怎么用GraalVM构建高效原生镜像
Java GraalVM原生镜像构建_Java怎么用GraalVM构建高效原生镜像
 Python FastAPI异步API开发_Python怎么用FastAPI构建异步API
Python FastAPI异步API开发_Python怎么用FastAPI构建异步API
 C++现代C++20/23/26特性_现代C++有哪些新标准特性如modules和coroutines
C++现代C++20/23/26特性_现代C++有哪些新标准特性如modules和coroutines
Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 907
907

















