
网页抓取是增强型生成式检索 (rag) 应用程序获取内容的一种有效途径,但解析网页内容却可能充满挑战。mozilla 的开源库 readability.js 提供了一种便捷的解决方案,用于提取网页的核心信息。本文将探讨如何将其集成到 rag 应用程序的数据获取流程中。
网页是 RAG 应用程序宝贵的非结构化数据来源。然而,网页通常包含大量无关信息,例如页眉、侧边栏和页脚等。这些内容虽然对用户浏览网站有帮助,但却偏离了页面的主要主题。
为了优化 RAG 数据质量,我们需要滤除这些无关内容。针对特定网站,可以使用 Cheerio 等工具,根据网站结构自行解析 HTML。但如果需要跨不同布局和设计的网站抓取数据,则需要一种更通用的方法,只提取核心内容,忽略其余部分。
大多数浏览器都内置了阅读器视图,该视图会移除除文章标题和正文以外的所有内容。下图展示了 DataStax 网站一篇博文在浏览器模式和阅读器模式下的差异:

立即学习“前端免费学习笔记(深入)”;
Mozilla 将 Firefox 阅读器模式的核心库以独立开源模块 readability.js 的形式提供。因此,我们可以在数据管道中使用 readability.js 来清除无关内容,从而获得更高质量的抓取结果。
以下示例演示了如何从一篇关于在 Node.js 中创建矢量嵌入的博文中提取文章内容:
首先,使用以下 JavaScript 代码检索页面的 HTML:
<code class="javascript">const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);</code>
这包含了所有 HTML 标签,以及导航、页脚、分享链接、号召性用语等等。
为了改进这一点,您可以安装 Cheerio 模块,并只选择关键部分:
<code class="bash">npm install cheerio</code>
<code class="javascript">import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());</code>这段代码可以获取文章标题和正文。但是,这需要您了解 HTML 结构,而这并非总是可行的。
更好的方法是安装 readability.js 和 jsdom:
<code class="bash">npm install @mozilla/readability jsdom</code>
readability.js 通常在浏览器环境中运行,并使用实时文档而非 HTML 字符串,因此我们需要 jsdom 在 Node.js 中模拟浏览器环境。现在,我们可以将已加载到文档中的 HTML 传递给 readability.js 进行解析:
<code class="javascript">import { readability } from "@mozilla/readability";
import { jsdom } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new jsdom(html, { url });
const reader = new readability(doc.window.document);
const article = reader.parse();
console.log(article);</code>解析后的结果包含标题、作者、摘要、发布时间以及正文内容 (content 和textContent)。textContent 属性是纯文本内容,可以用于分块、创建矢量嵌入并存储到数据库中。content 属性包含原始 HTML,包括链接和图像,方便进一步处理。
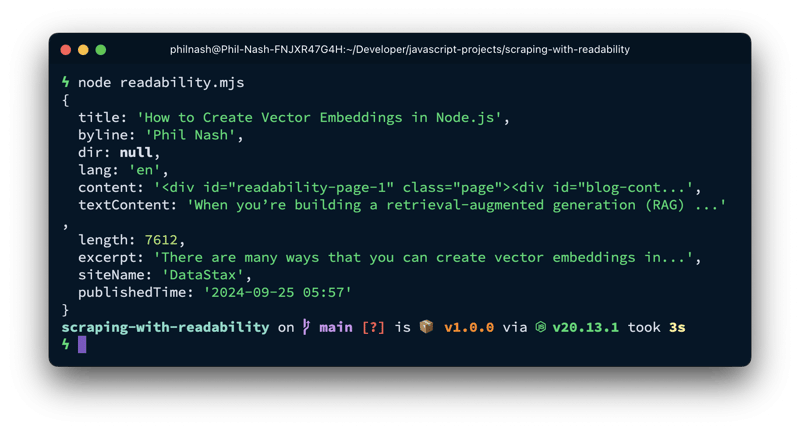
为了确保页面适合使用 readability.js 处理,可以使用 isProbablyReadable 函数进行预先检查:
<code class="javascript">const doc = new jsdom(html, { url });
const reader = new readability(doc.window.document);
if (isProbablyReadable(doc.window.document)) {
const article = reader.parse();
console.log(article);
} else {
// 执行其他操作
}</code>如果页面未通过检查,则需要采取其他策略处理该页面,或者将其排除。
如果您的应用程序使用 Langchain.js,则可以结合使用 readability.js 和 Langchain.js 的 MozillaReadabilityTransformer 来处理网页内容。这可以与 Langchain 的其他组件(例如文本分块器和向量数据库)无缝集成。
readability.js 是一个可靠的库,可以有效地清理网页内容,使其更适合 RAG 应用。您可以直接使用该库,或者结合 Langchain.js 使用 MozillaReadabilityTransformer 来实现。 网页数据获取只是数据处理流程的第一步,后续还需要文本分块、向量嵌入生成以及数据存储等步骤。
您是否使用其他技术来清理 RAG 应用程序的网页内容?欢迎分享您的经验!
以上就是使用 Readabilityjs 清理 HTML 内容以进行检索增强生成的详细内容,更多请关注php中文网其它相关文章!

HTML怎么学习?HTML怎么入门?HTML在哪学?HTML怎么学才快?不用担心,这里为大家提供了HTML速学教程(入门课程),有需要的小伙伴保存下载就能学习啦!

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 993
993
























