
边缘计算设备,例如各种物联网 (iot) 设备,日益普及。然而,这些设备通常计算资源和存储空间有限,限制了在设备端部署大型深度神经网络 (dnn) 的能力。小型 dnn 架构虽然计算效率更高,但性能往往有所降低。
知识迁移为解决这一问题提供了一种途径,主要方法包括知识蒸馏和迁移学习。知识蒸馏通过训练紧凑型“学生”模型来模仿“教师”模型的 logits 或特征图,提升学生模型的准确性。迁移学习则通常利用预训练和微调,将在大规模数据集上预训练获得的知识,通过共享骨干网络应用于下游任务。
传统知识迁移方法依赖于模型结构或特定任务特征/标签的共享元素,在某些情况下效果良好,但在模型架构和任务类型差异较大时,其适用性受到限制。物联网应用场景中,不同设备的计算资源和任务需求差异巨大,这给知识迁移带来了额外挑战。
针对上述问题,浙江大学和上海交通大学的研究团队提出了一种更灵活、通用的知识迁移方法 MergeNet,旨在实现跨模型架构、任务类型甚至数据模态的异构知识迁移。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

 图 1. 知识蒸馏、骨干共享和 MergeNet 的比较
图 1. 知识蒸馏、骨干共享和 MergeNet 的比较
研究挑战与 MergeNet 框架
该团队面临两大挑战:如何实现异构模型知识的统一表示,以及如何实现异构模型知识的适配。传统方法难以处理模型架构、任务类型和数据模态的差异。
MergeNet 框架巧妙地解决了这些问题。它将模型参数作为知识的通用载体,并通过低秩矩阵分解来统一表示异构模型的知识,消除了模型架构差异。此外,MergeNet 引入了一个参数适配器,学习弥合异构模型参数空间的差距,促进知识的有效交互和融合。
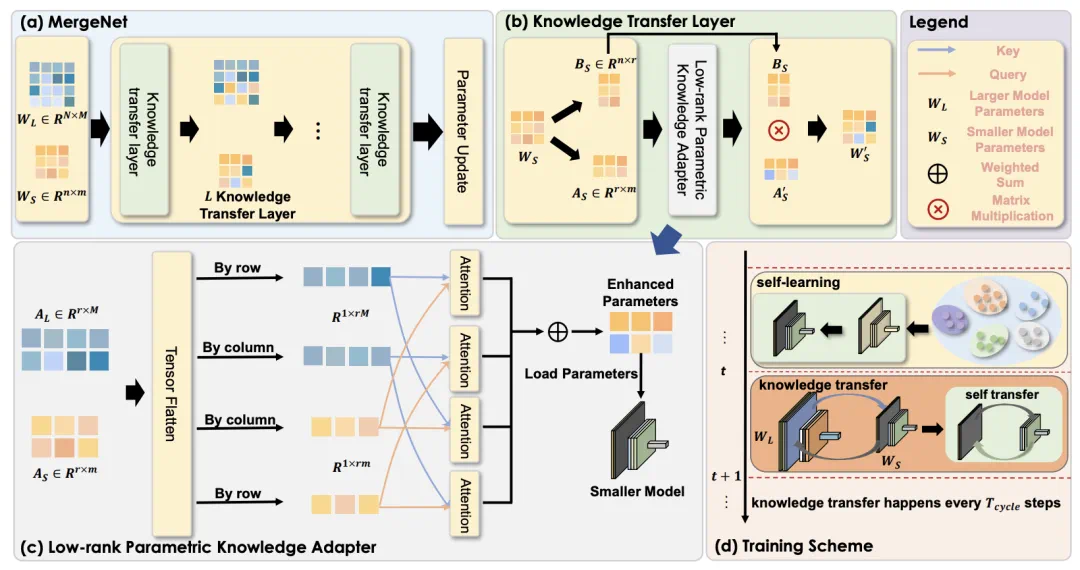
图 2. MergeNet 框架
核心机制:低秩参数知识适配器 (LPKA)
LPKA 利用低秩矩阵分解提取知识,并通过注意力机制将源模型的知识整合到目标模型中,实现知识的动态调整和适应。这类似于根据自身需求选择性地吸收知识,而非全盘接收。
训练过程:自学习与互学习
MergeNet 的训练过程包含自学习和互学习两个阶段。自学习阶段,模型优化自身参数;互学习阶段,进行模型间的知识迁移。这种设计结合了教师指导和自我学习,提升了知识迁移的效率和效果。
实验结果与结论
研究团队在跨结构、跨模态和跨任务知识迁移场景中进行了广泛的实验,结果表明 MergeNet 显著提升了模型性能,验证了其有效性和通用性。 消融实验进一步证明了 MergeNet 各组件的贡献。 MergeNet 提供了一种更强大、更通用的知识迁移框架,尤其适用于资源受限的边缘计算环境。
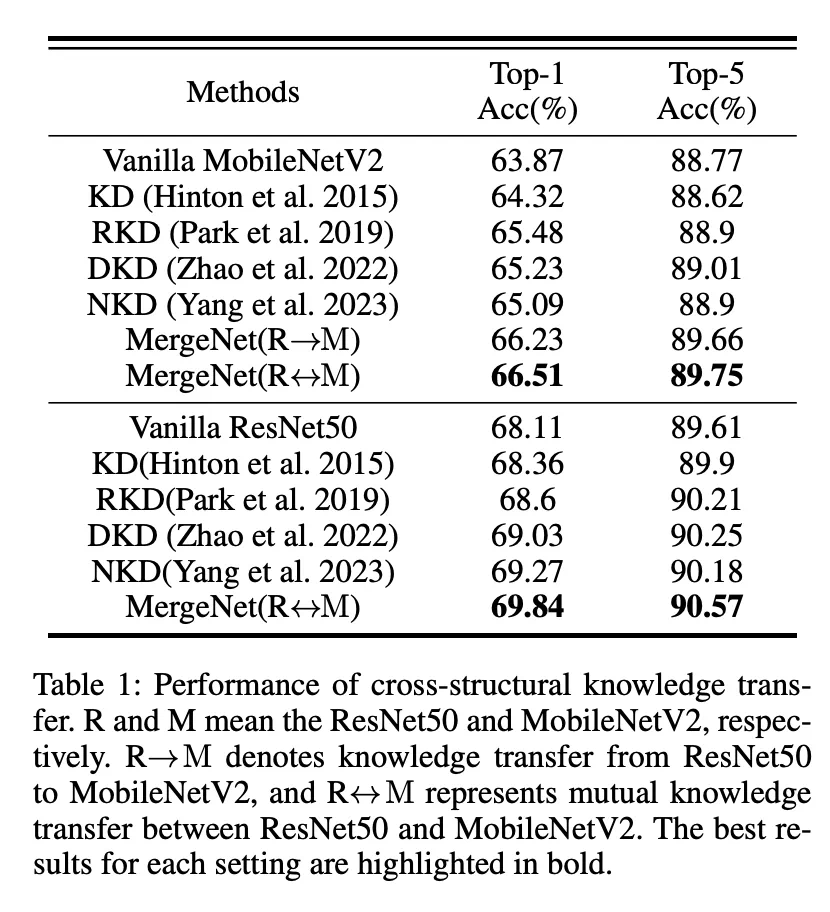
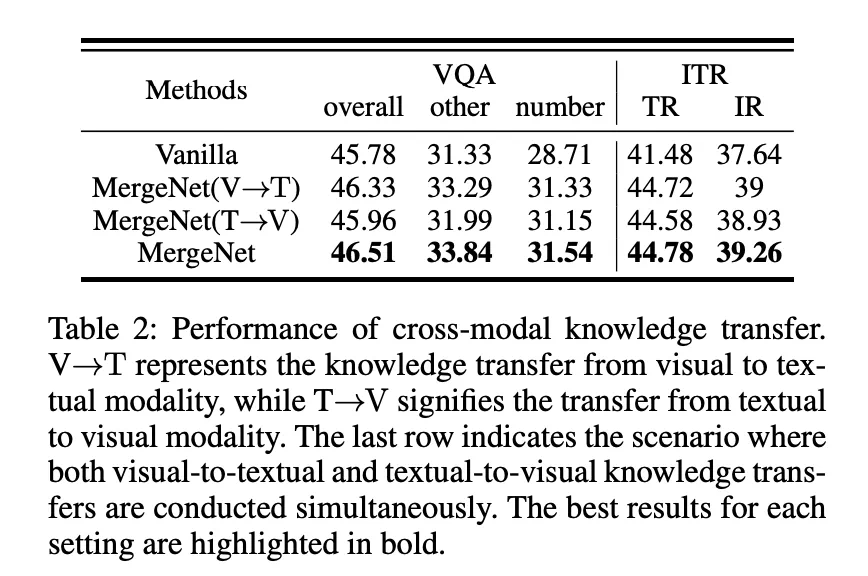
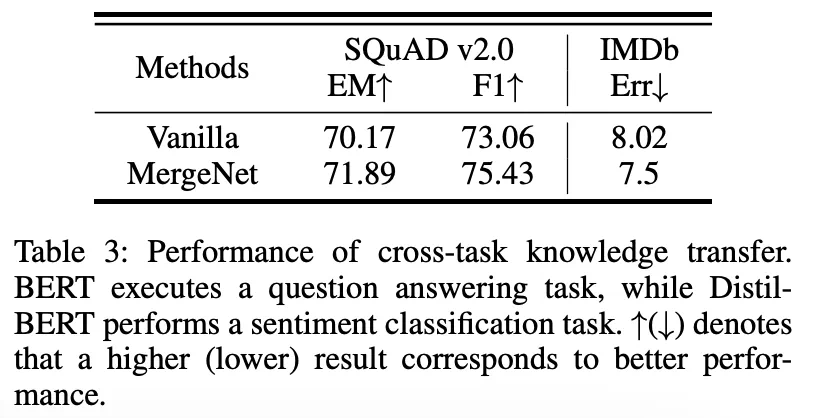
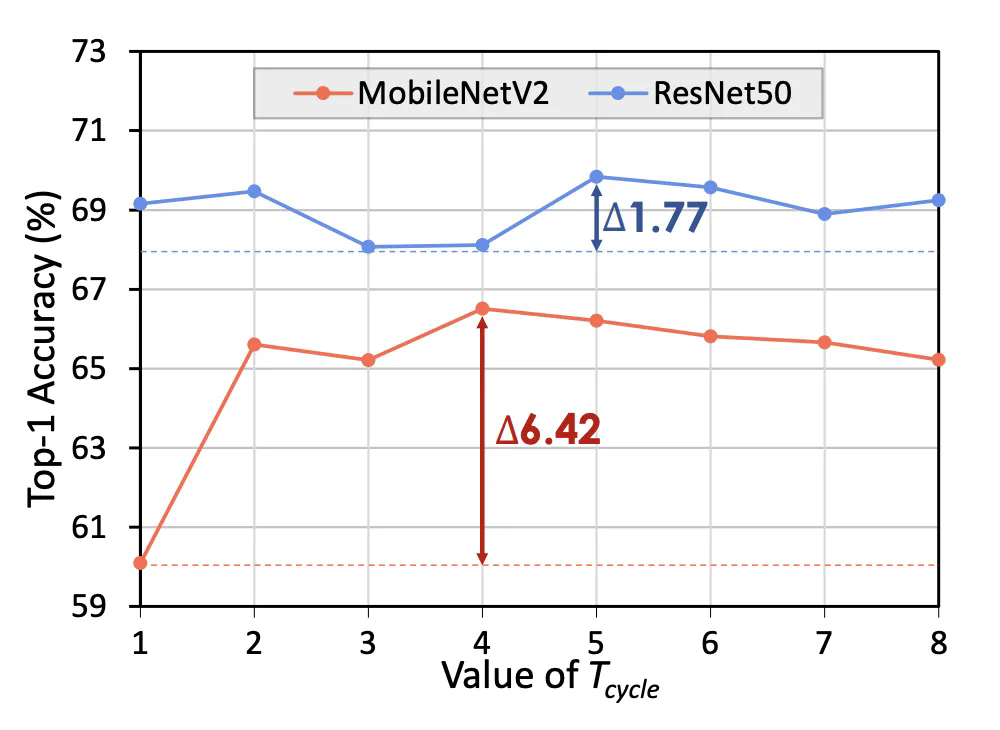
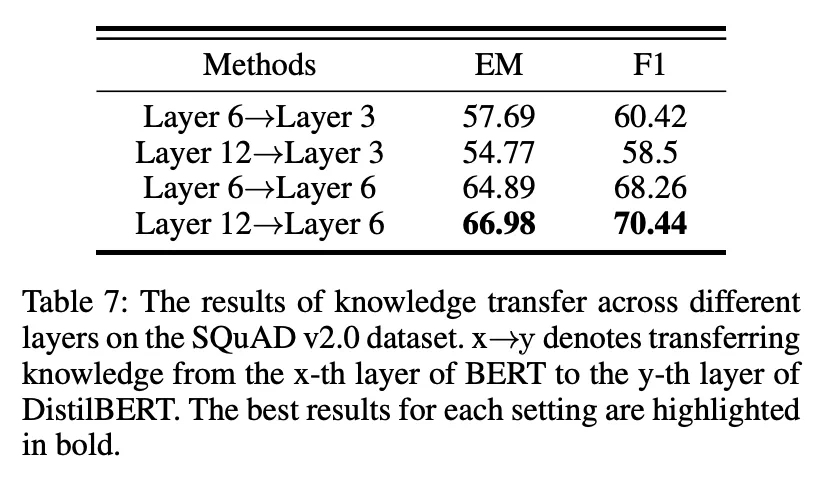
更多细节请参考论文原文。
以上就是模型参数作知识通用载体,MergeNet离真正的异构知识迁移更进一步的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 861
861
























