
深度解析:大型语言模型的缩放定律是否已触及瓶颈?
近年来,人工智能领域,特别是大型语言模型(LLM)的进步,很大程度上依赖于缩放定律。简单来说,就是通过增加训练数据和模型规模来提升性能。这种关系可以用数学公式精确表达,预测更大规模训练的效果,从而为持续投资提供依据。然而,近期有报道称顶级实验室在训练下一代LLM时遇到困难,引发了人们对缩放定律是否已触及瓶颈的疑问。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本文将深入探讨LLM缩放定律及其相关研究,澄清一些误解,并分析导致其“停滞”的因素,最终展望AI研究的未来方向。
LLM缩放定律的基础:幂律
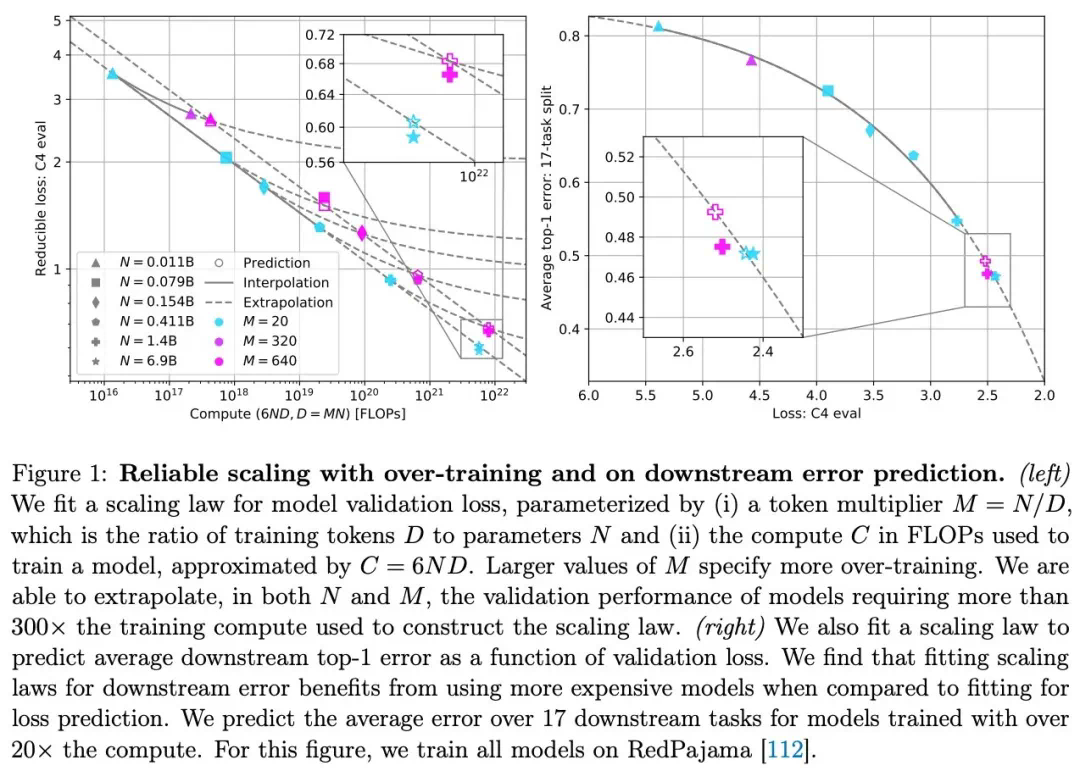
理解LLM缩放的关键在于幂律。幂律描述两个量之间的关系,在LLM中,通常是测试损失(或其他性能指标)与模型参数量、训练数据量或计算量之间的关系。例如,增加模型参数量(在数据和计算量充足的前提下)会以可预测的程度降低测试损失。
幂律公式:y = axp
其中,x和y是两个量,a和p是常数。在LLM缩放研究中,通常使用对数坐标系绘制幂律关系,呈现为线性关系。然而,很多情况下,图像是反幂律关系,公式为:y = ax-p,其中p为正数。
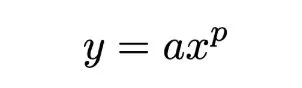
早期研究与GPT系列模型
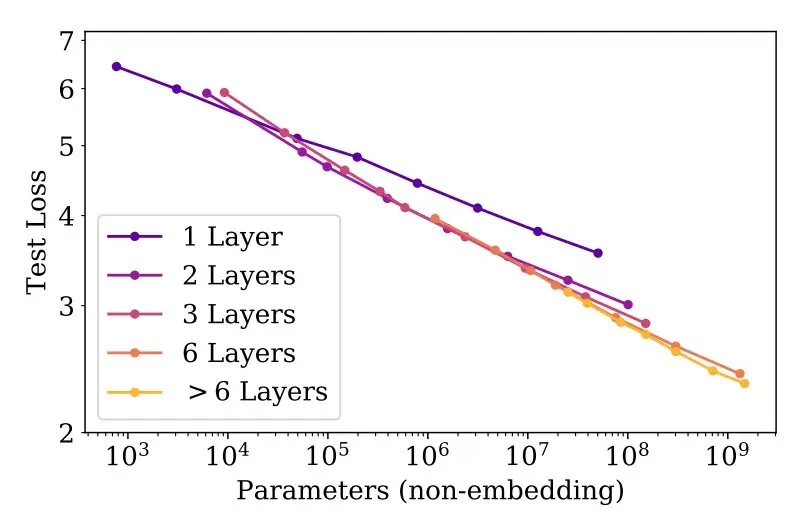
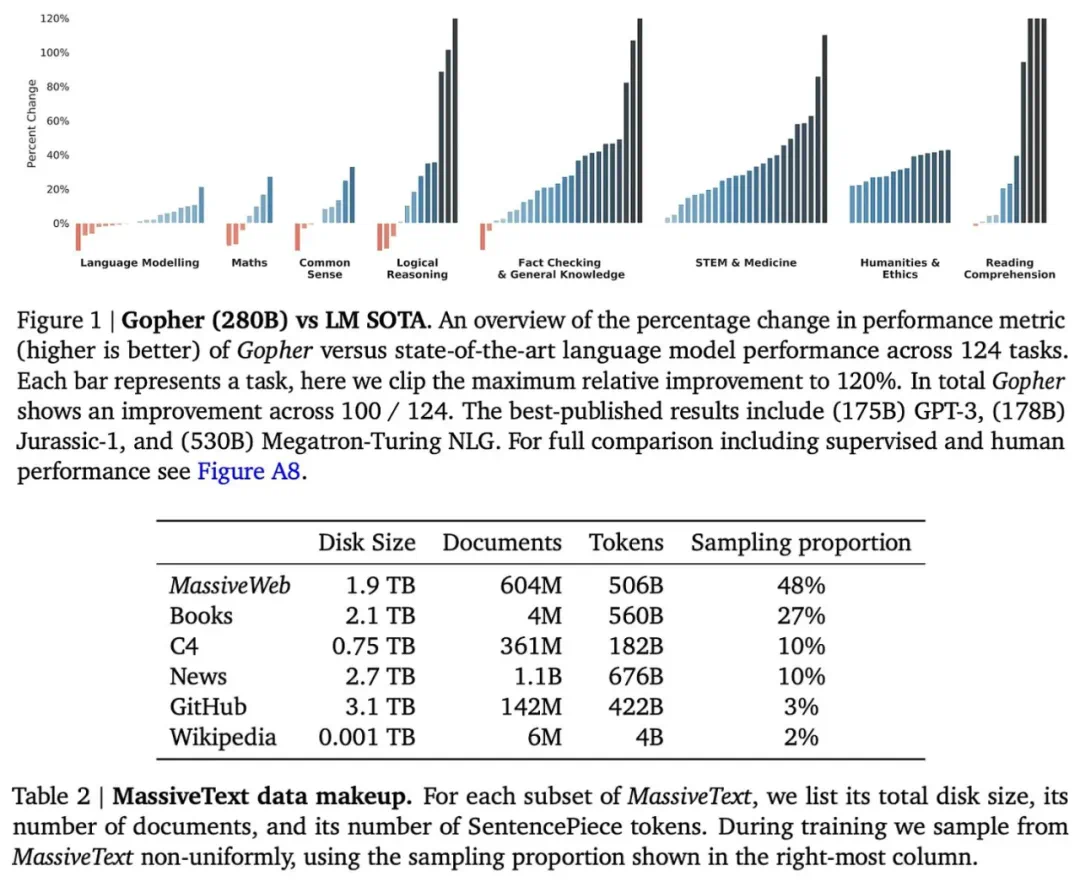
早期研究表明,LLM性能随着模型参数量、数据集大小和训练计算量的增加而稳步提升,且存在幂律关系。这一发现推动了大规模预训练LLM的兴起,例如OpenAI的GPT系列模型。
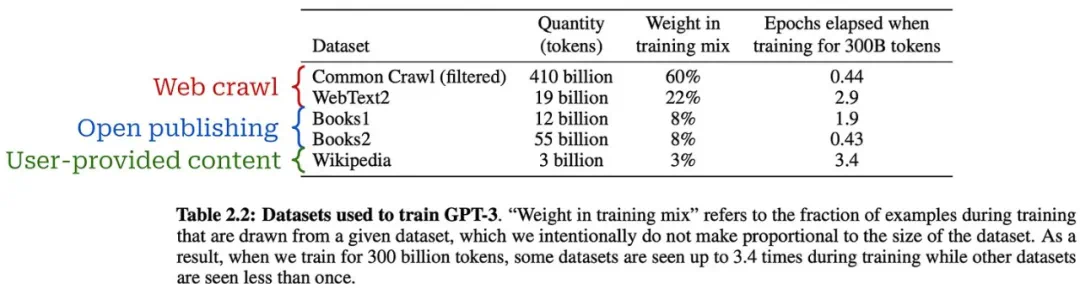
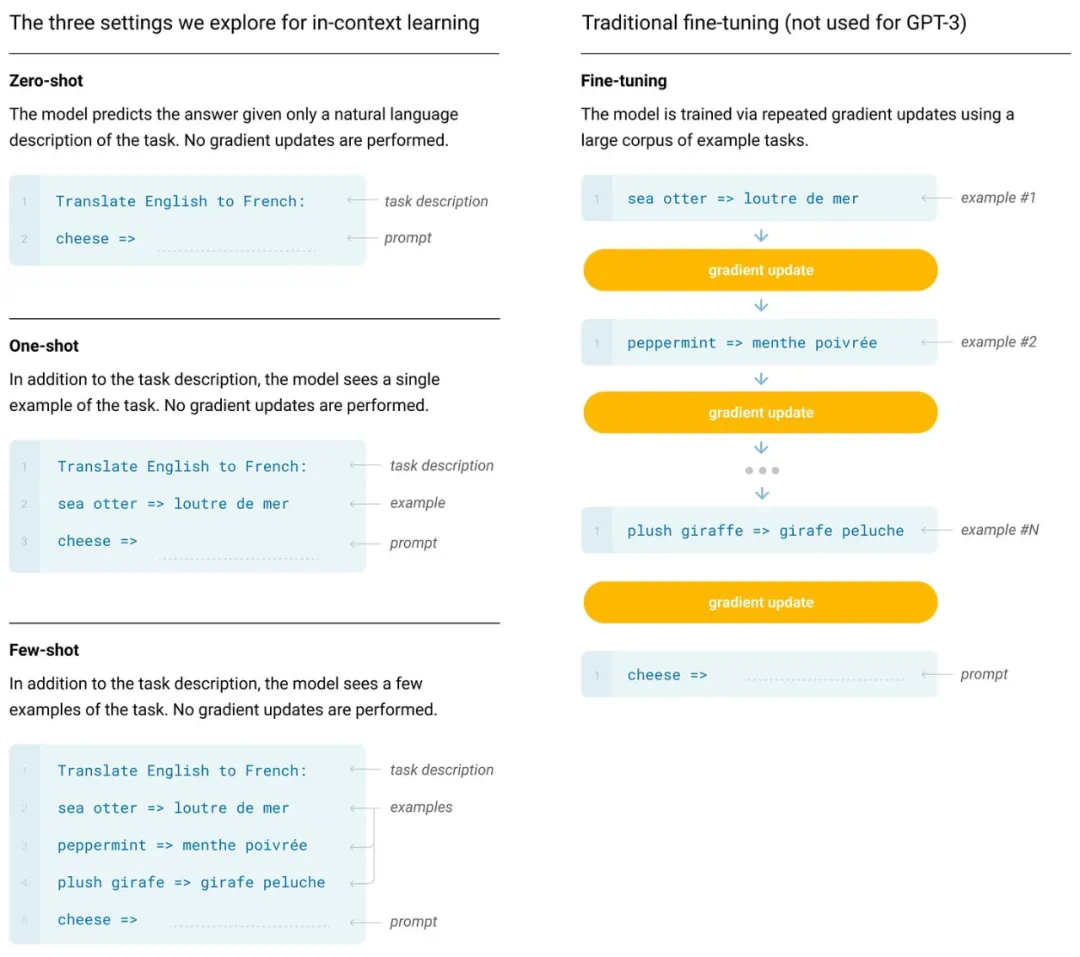
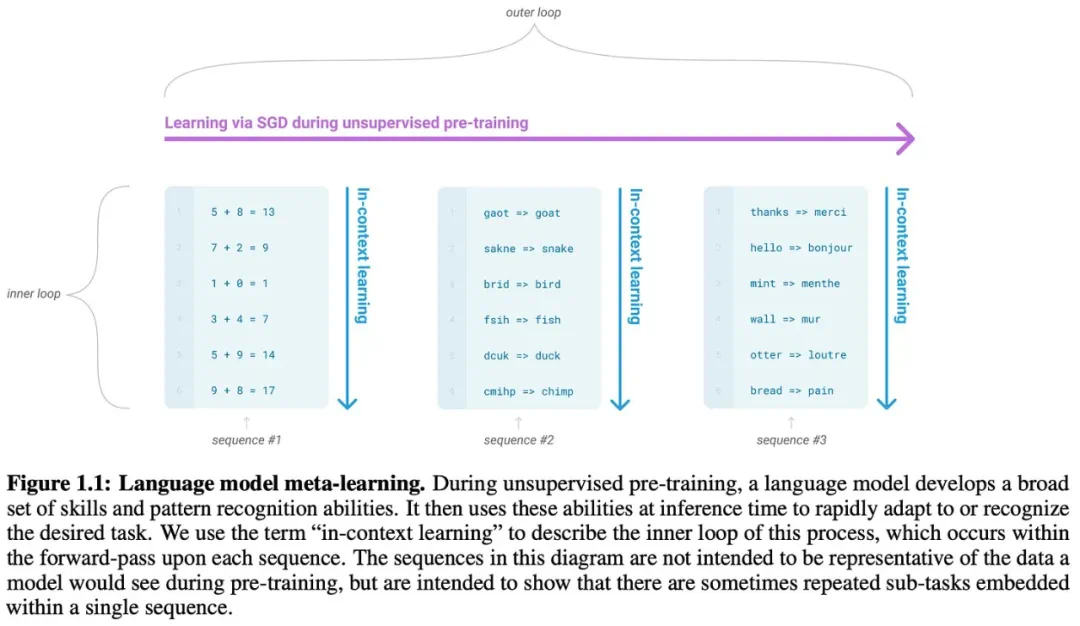
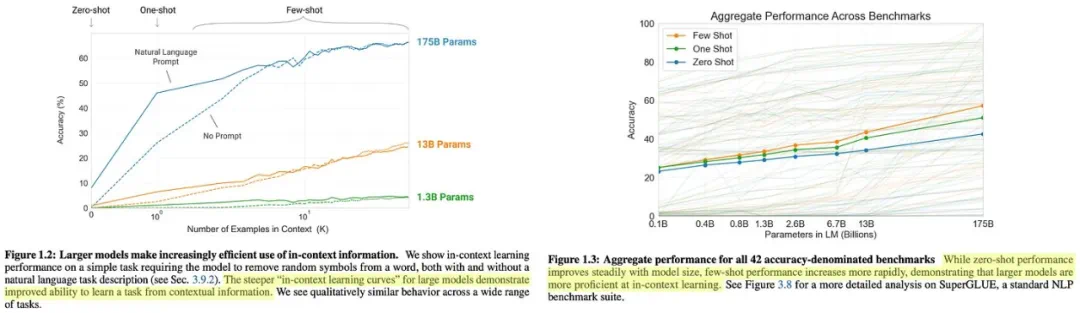
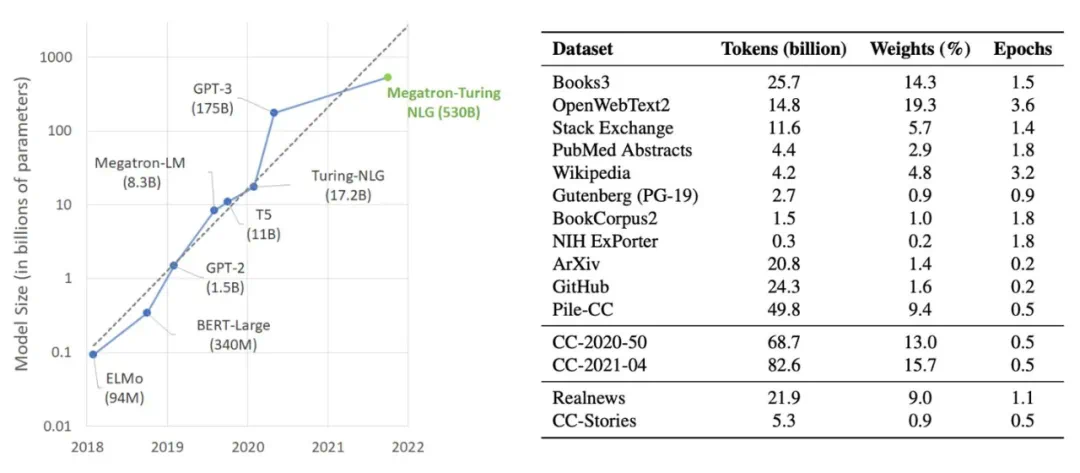
GPT系列模型的演进,从GPT到GPT-3,展现了规模化预训练的显著效果。GPT-3拥有1750亿个参数,在少样本学习方面取得了突破性进展,标志着基础模型时代的到来。
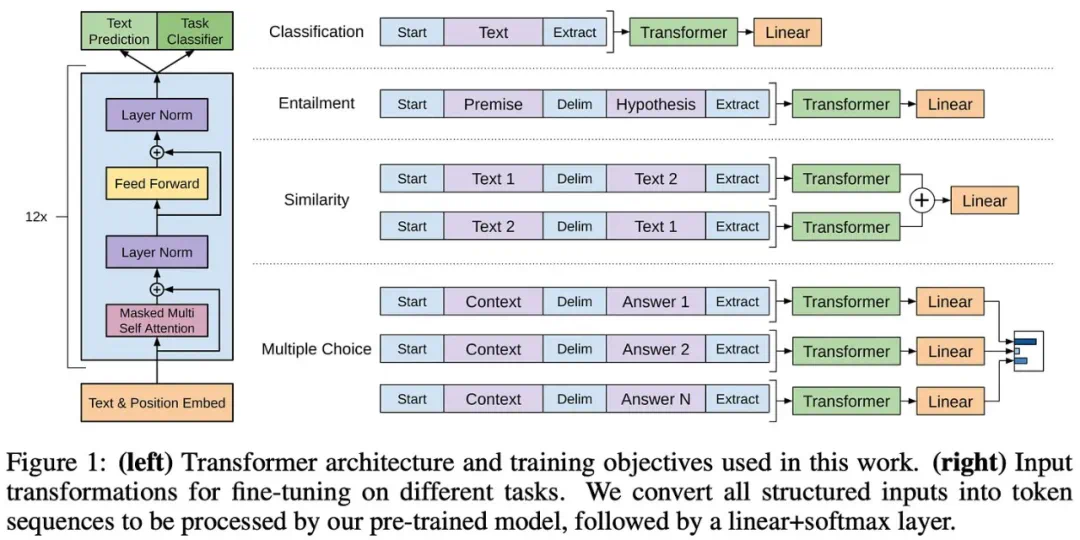
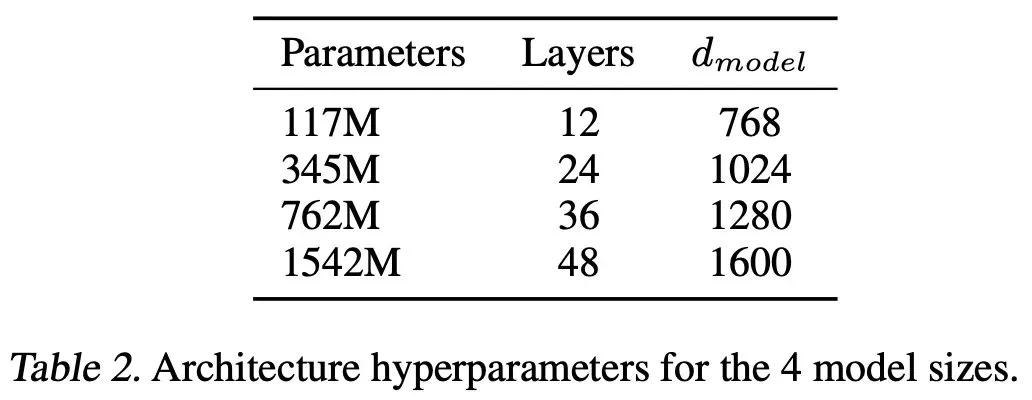
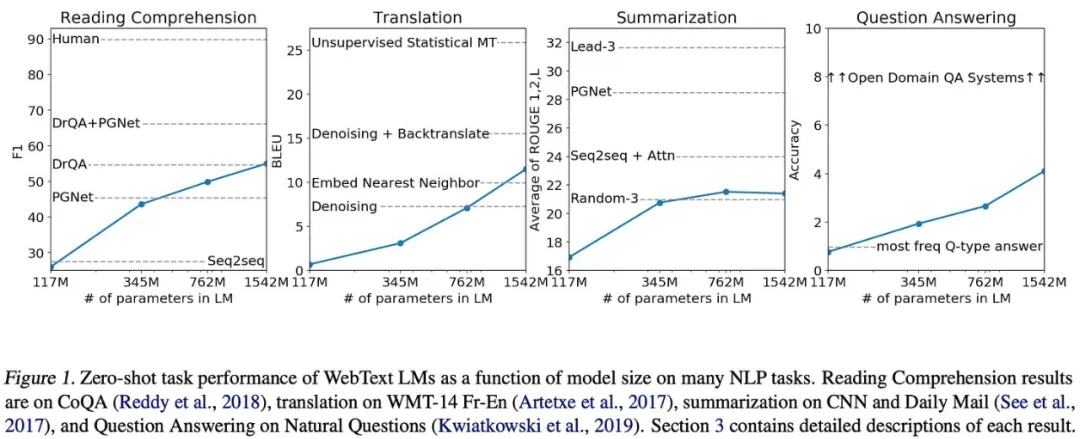
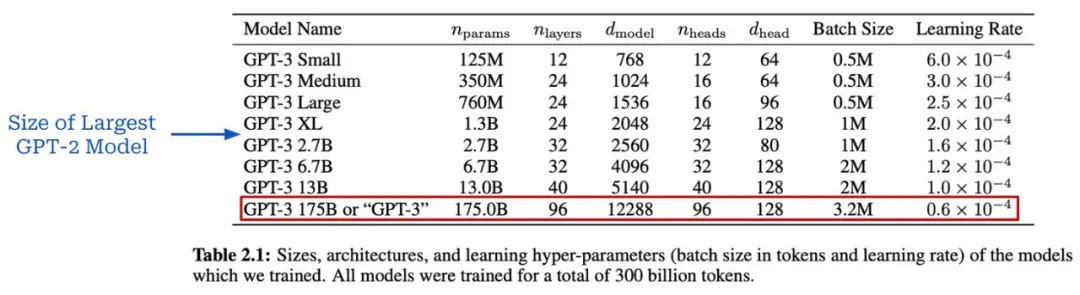
缩放定律的实际应用与局限性
缩放定律并非只是理论研究,它在实际应用中具有重要价值。研究者可以利用它来预测更大模型的性能,从而更有效地分配资源。然而,这种预测并非完美无缺,模型的实际表现可能因规模差异而存在偏差。
Chinchilla模型与计算最优的缩放定律
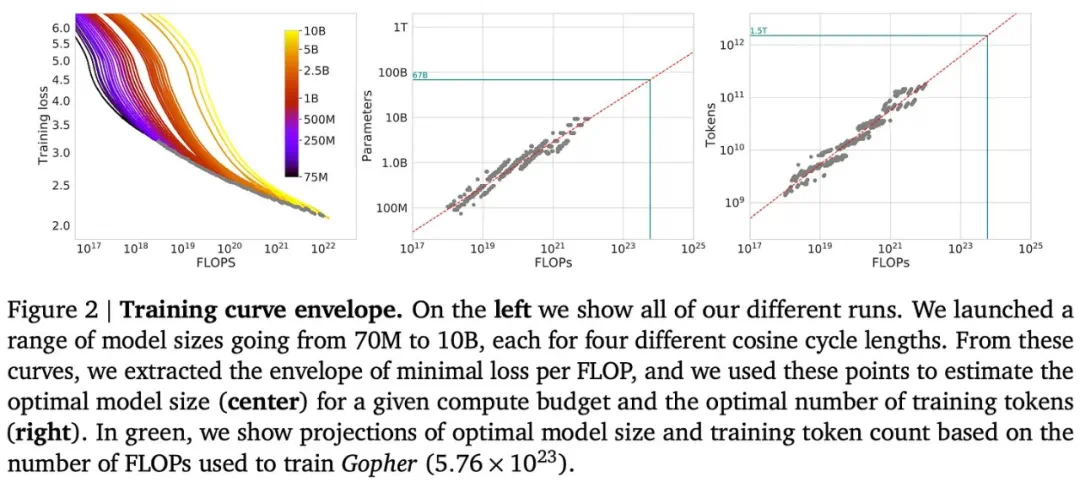
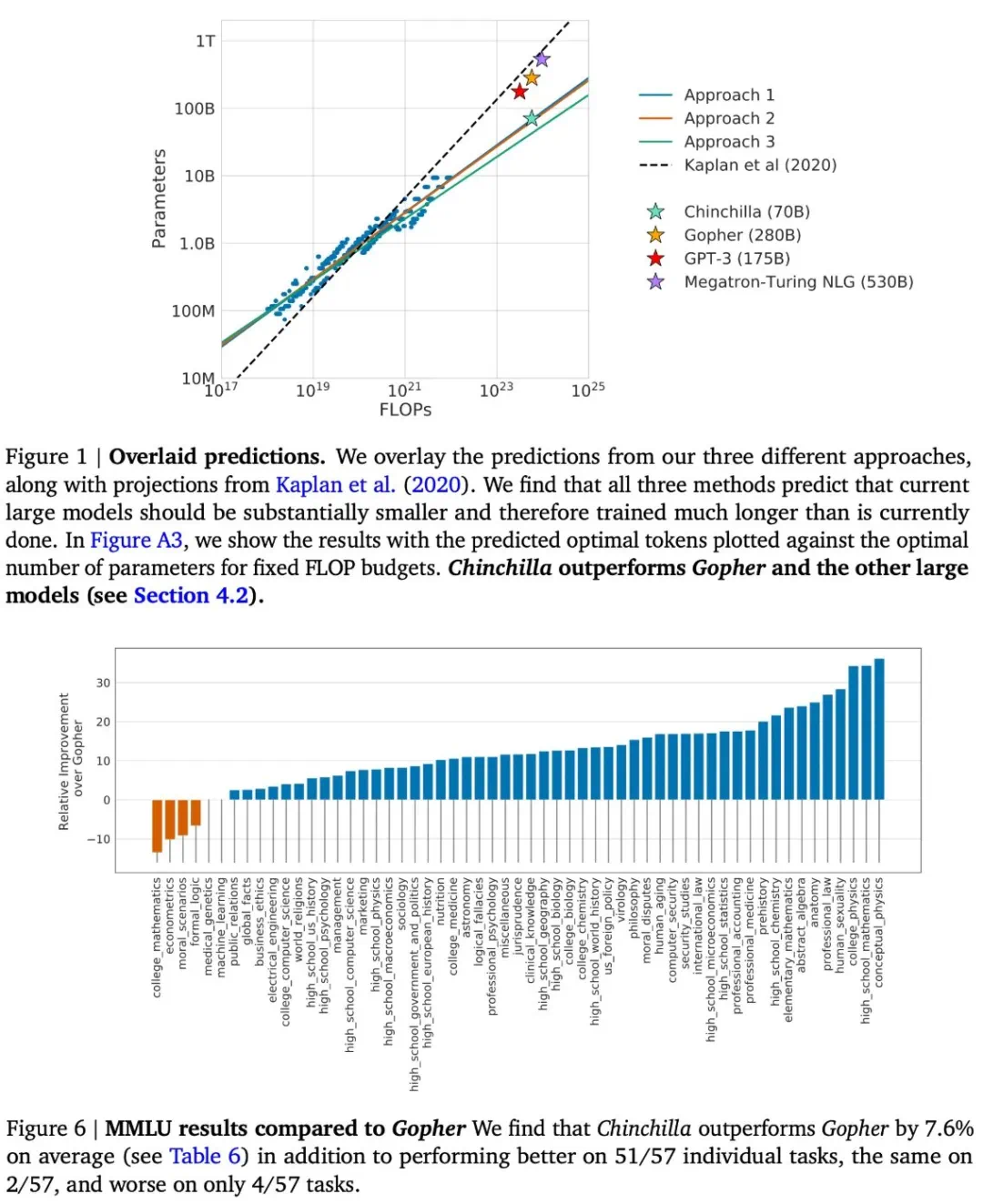
Chinchilla模型的研究表明,模型大小和数据集大小应该按比例缩放,才能达到计算最优的训练效果。这挑战了早期研究中关于数据量相对不那么重要的观点。
缩放定律的“放缓”与挑战
近年来,关于缩放定律是否已触及瓶颈的讨论甚嚣尘上。一些人认为,模型改进速度正在放缓,甚至出现收益递减。这种“放缓”可能源于多个因素:
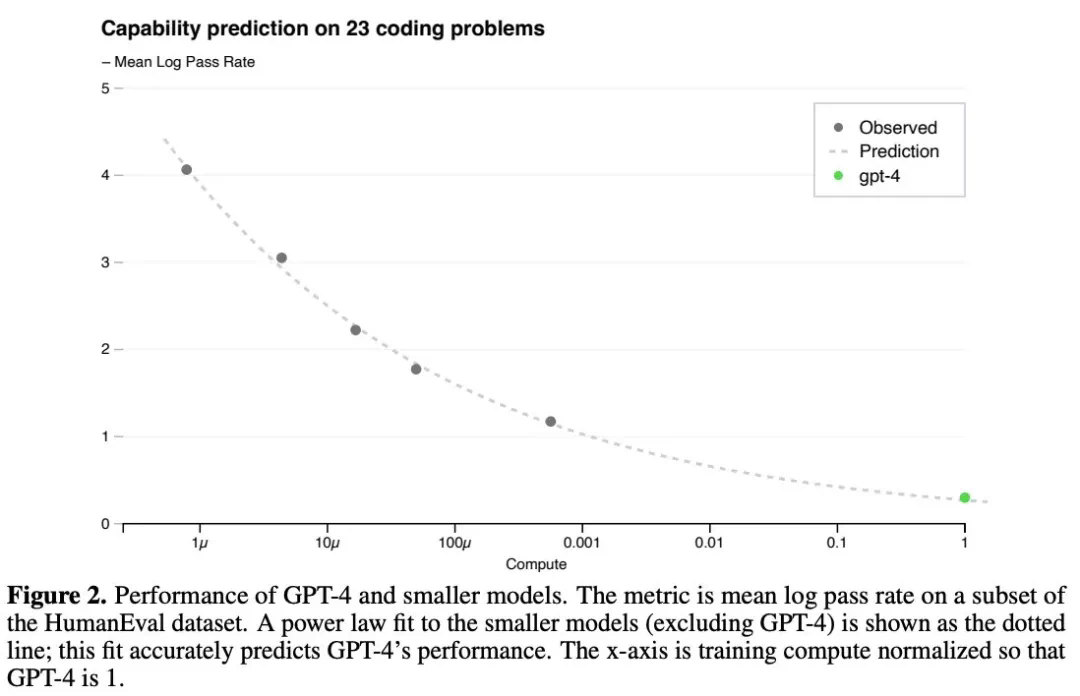
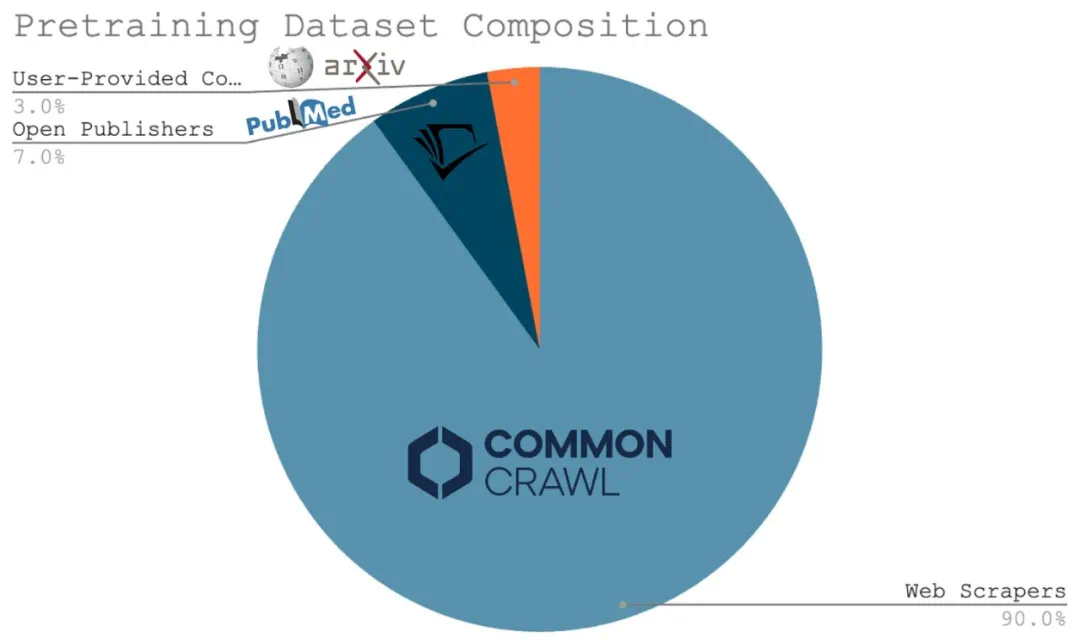
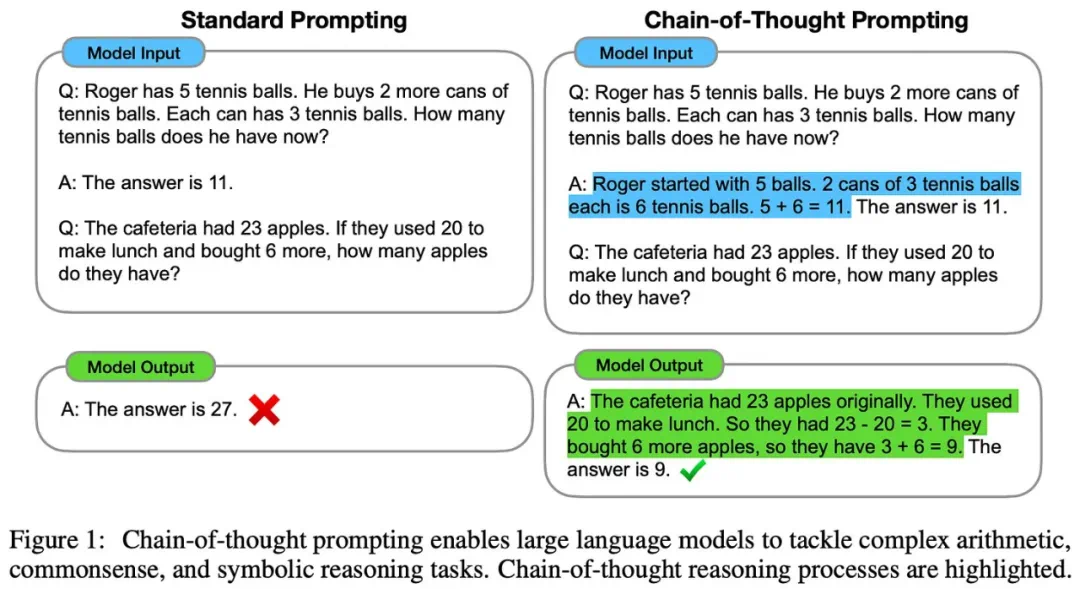
超越单纯的规模:未来的研究方向
即使单纯的规模化预训练遇到瓶颈,AI研究仍有其他途径可以继续发展:
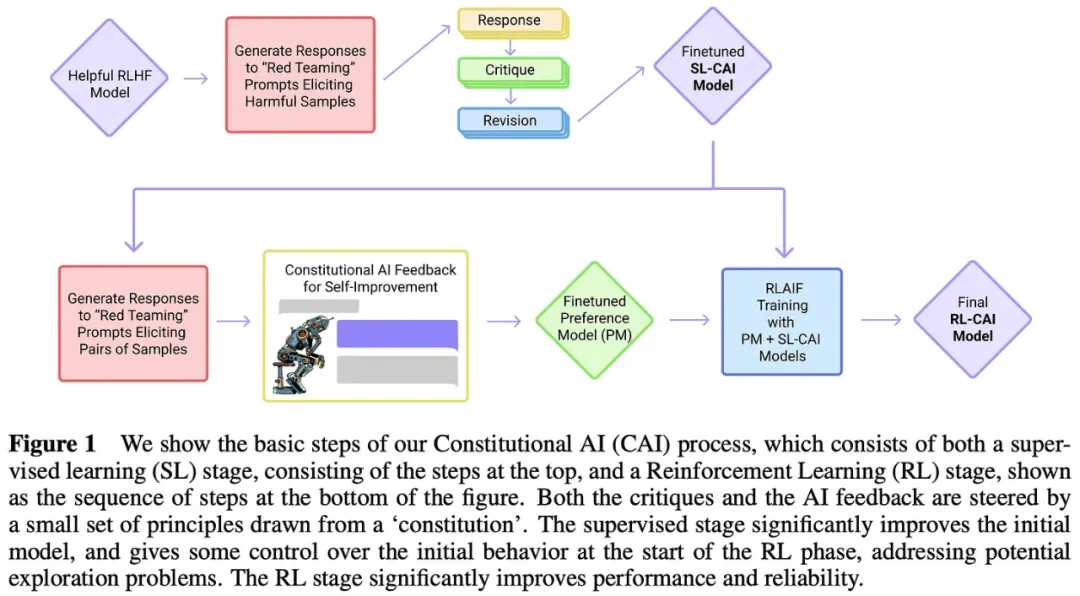


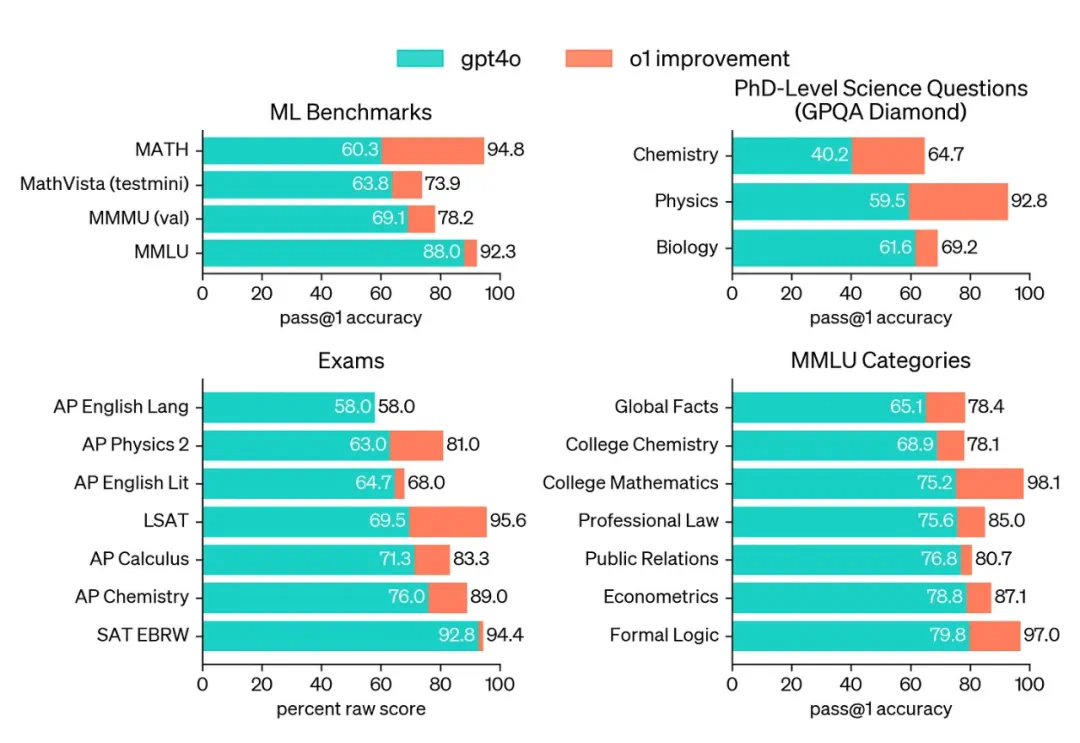
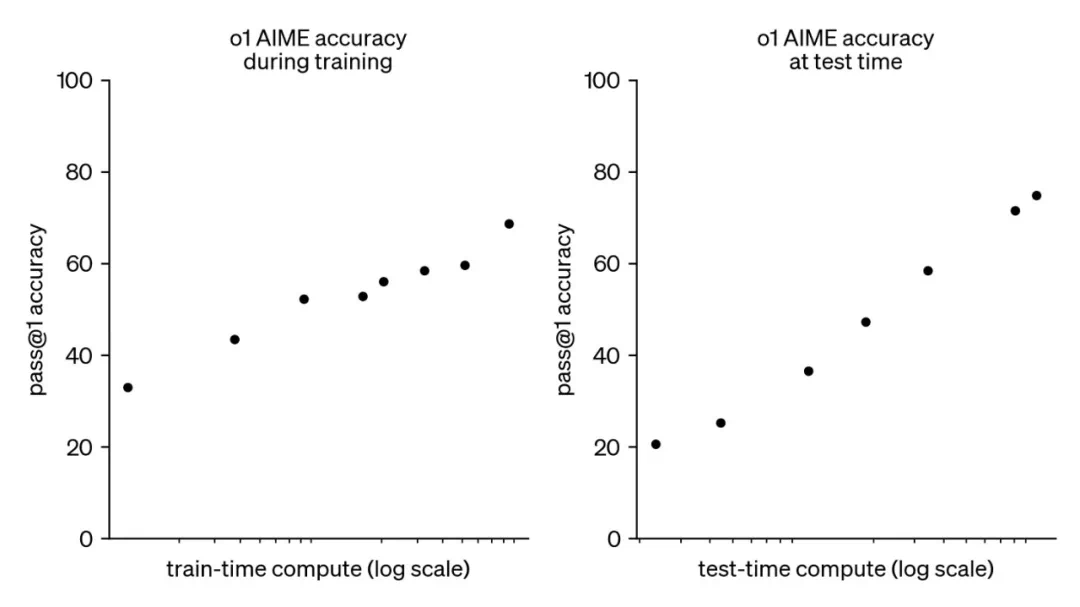
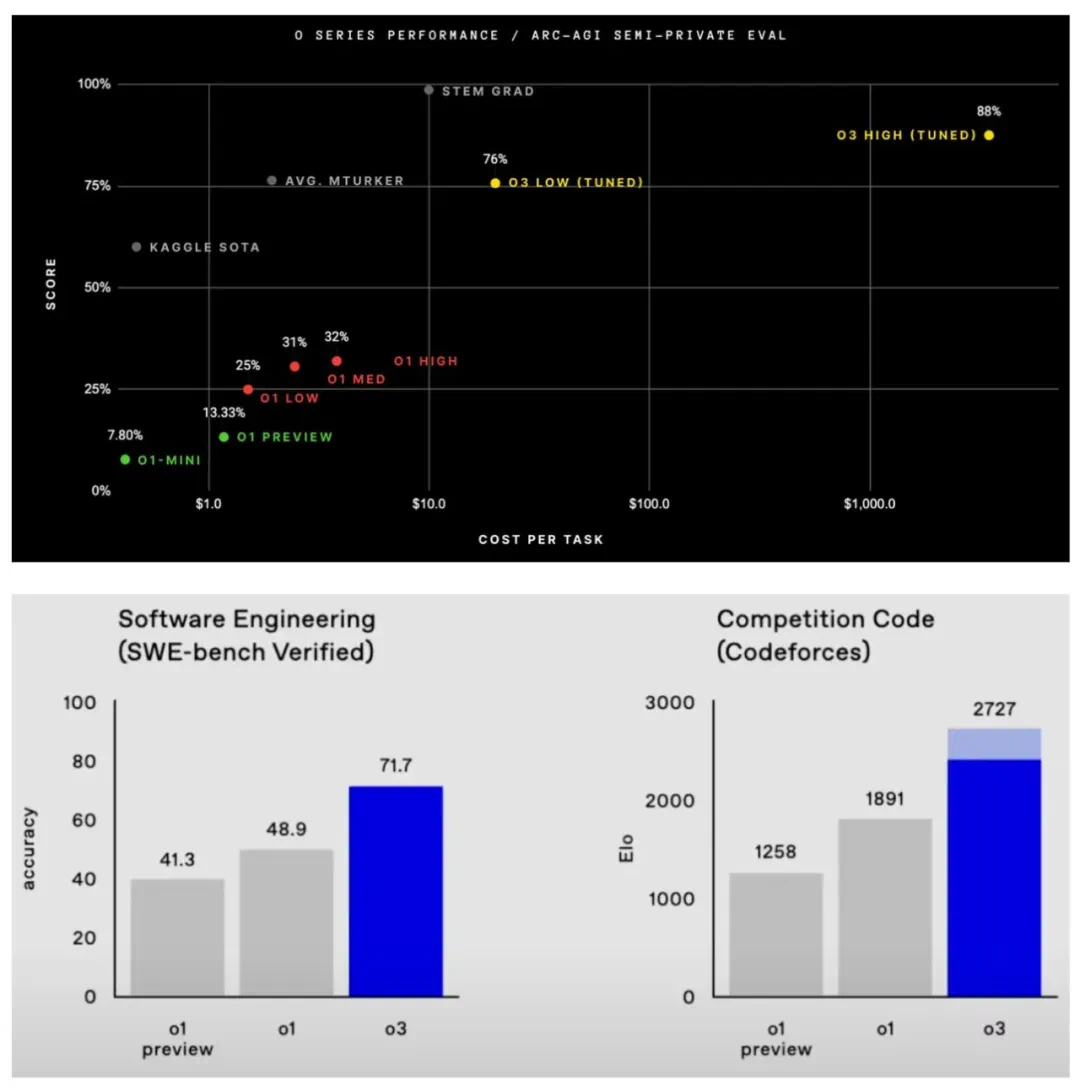
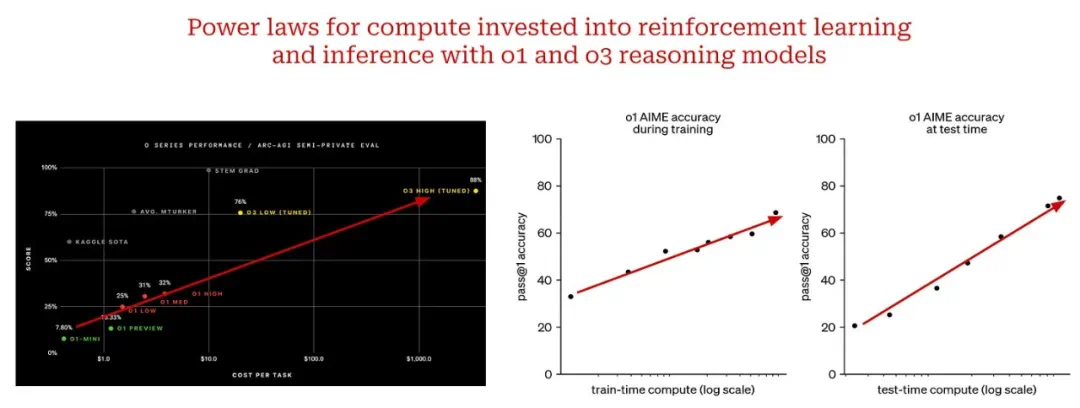

总结
缩放定律对LLM的发展起到了关键作用,但其效力并非无限。未来的AI研究需要探索新的缩放范式,例如在模型架构、训练方法和推理策略等方面进行创新,才能持续推动人工智能技术的进步。 单纯的规模化并非终点,更强大的模型和更有效的应用才是最终目标。
以上就是万字长文解读Scaling Law的一切,洞见LLM的未来的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 686
686



















