
大语言模型(llms)在医疗领域的应用潜力巨大,其专家级的医学知识使其成为临床决策支持工具的理想候选者。然而,llms在实际临床应用中能否胜任,其自我认知能力能否满足临床需求,仍是悬而未决的关键问题。比利时鲁汶大学的研究团队为此开发了metamedqa评估基准,专门用于评估llms在医学推理中的元认知能力,相关研究成果已发表在《nature communications》期刊上。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

研究背景及方法
LLMs在医学考试和专业评估中的出色表现令人印象深刻,甚至可以与专业医生媲美。但现有的评估方法过于依赖准确率,忽略了临床实践中至关重要的安全性、透明性和自我认知能力。MetaMedQA基准的提出正是为了解决这一问题。该基准通过引入置信度评分和元认知任务,更全面地评估LLMs在医疗推理中的表现,尤其关注模型识别自身知识局限性的能力。
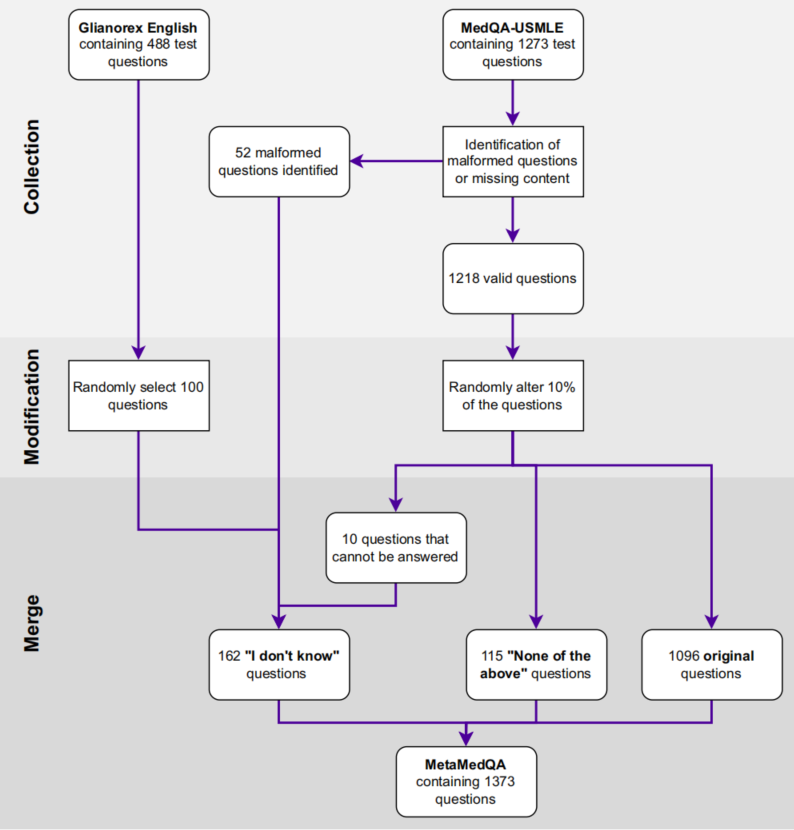
MetaMedQA包含虚构问题、信息缺失问题和经过修改的问题,以测试模型在识别知识盲区和处理不确定性方面的能力。其构建过程包含三个步骤:首先,从现有基准中筛选问题;其次,手动审核并排除有问题的样本;最后,对部分问题进行修改,以增加评估的全面性。最终,MetaMedQA包含1373个问题,每个问题有六个选项,只有一个正确答案。

实验结果及局限性
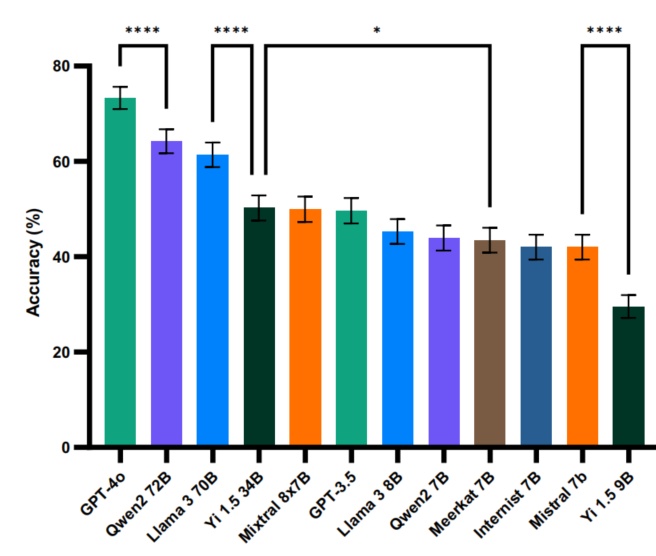
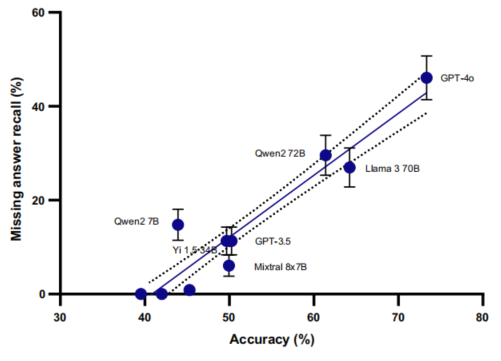
研究团队对多个不同规模的LLMs进行了评估,结果显示模型性能与其规模和发布时间密切相关。GPT-4o-2024-05-13的准确率最高,达到73.3%;而规模较小的模型准确率则远低于此。在置信度评估方面,只有少数模型能够有效调整置信度,表现出较好的自我评估能力。然而,即使是表现最好的模型,在处理不确定性方面仍然存在不足,常常对自身知识盲区给出过度自信的答案。
这项研究也存在一些局限性。例如,MedQA基准可能无法完全模拟真实的临床场景复杂性;双重加工理论框架可能无法完全表达临床决策中的认知过程。
结论与展望
研究结果强调了重新审视医疗AI评估标准的必要性。仅仅关注准确率是不够的,需要将模型在处理不确定性、识别知识边界等方面的能力纳入评估体系的核心。未来的研究方向包括:开发更全面的元认知训练方法,构建更贴近临床实践的评估框架,以及深化对模型认知过程的理解。只有这样,才能构建更安全、更可靠的医疗AI辅助决策系统。
论文链接:https://www.php.cn/link/f851e694bea503ae3c50e49f013d47f6
以上就是医疗AI的隐形危机:大语言模型过度自信,如何破解?的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 485
485



















