
ai大模型正以前所未有的速度发展,其能力已在许多任务上达到甚至超越人类水平。然而,现有的基准测试已难以准确衡量最先进的大型语言模型(llm)的能力,例如,在常用的mmlu基准测试中,顶尖llm的准确率已超过90%。
为应对这一挑战,AI安全中心(Center for AI Safety)与Scale AI合作,推出了一项极具挑战性的新基准测试:人类的最后考试(Humanity's Last Exam,HLE)。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

HLE旨在成为一个涵盖广泛学科的终极封闭式学术基准,目前包含3000多个难题,涉及数百个学科领域,包括数学、人文科学和自然科学。题目主要为多项选择题和简答题,答案明确且易于验证,但无法通过网络搜索快速解答。
HLE的构建汇聚了全球近千名专家的力量,他们来自50多个国家和地区的500多个机构。
 这项庞大的工作也设立了50万美元的奖金池,鼓励高质量的题目提交。
这项庞大的工作也设立了50万美元的奖金池,鼓励高质量的题目提交。
一些SOTA模型在HLE上的表现令人惊讶地低。 即使是顶尖模型,准确率也远低于10%。 HLE数据集的学科覆盖范围如下图所示:
即使是顶尖模型,准确率也远低于10%。 HLE数据集的学科覆盖范围如下图所示: 部分题目示例如下:
部分题目示例如下: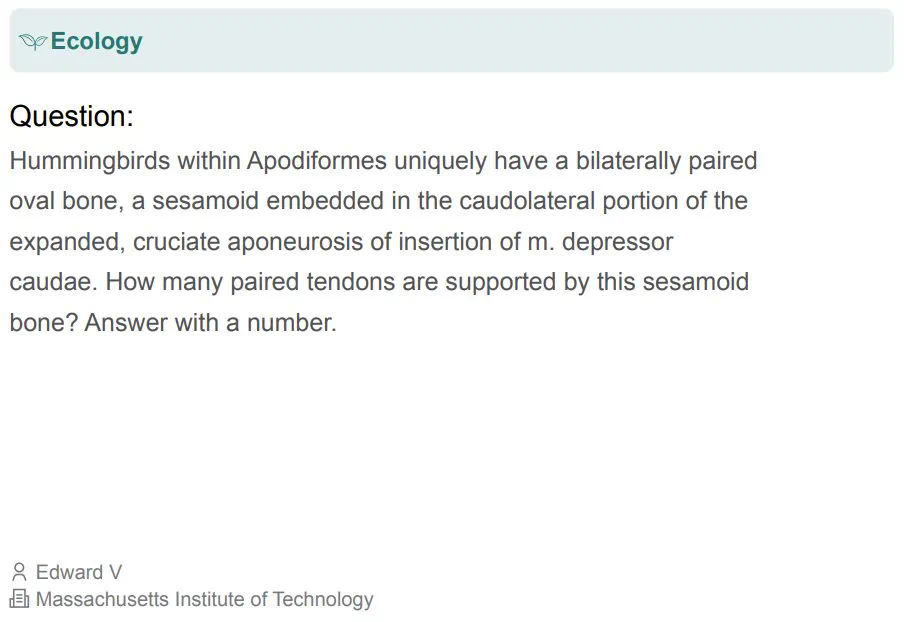
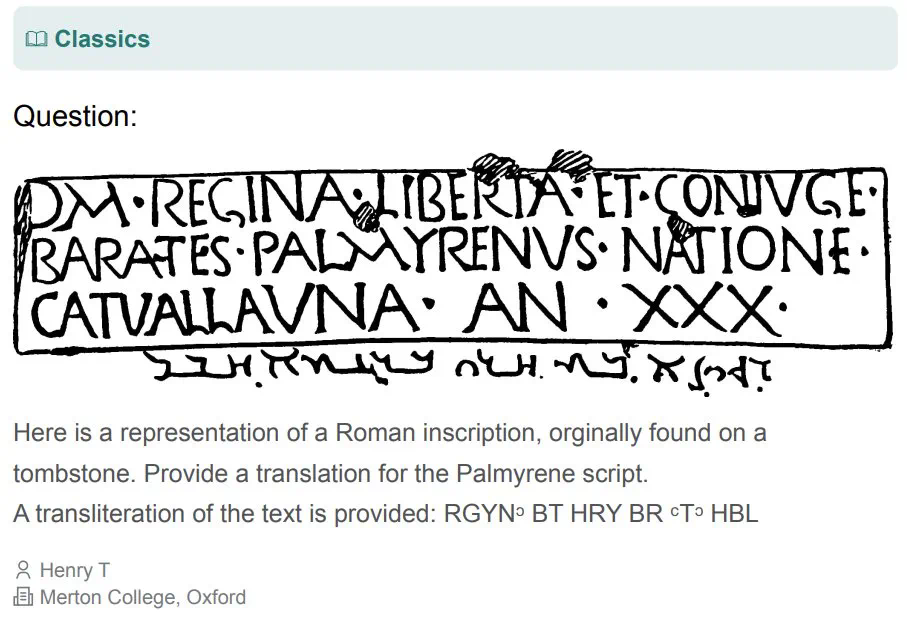


除了公开发布的题目,研究团队还保留了一个私有测试集,用于评估模型的过拟合情况。 HLE的数据收集过程严格,确保题目准确、明确、可解且不可通过简单搜索获得答案。
尽管目前LLM在HLE上的表现不佳,但研究团队预测,到2025年底,模型的准确率可能超过50%。 即使模型在HLE上取得高分,也并不意味着其具备了通用人工智能,HLE主要测试的是模型在结构化学术问题上的推理能力。 研究团队认为,HLE可能是对模型进行的“最后一次学术考试”,但这绝非AI发展的最终基准。 最新的o3-mini模型在HLE上的表现,以及使用Deep Research后的表现结果也已更新至官网。
 模型的token使用量分析也表明,未来模型不仅需要提高准确率,还需要优化计算效率。
模型的token使用量分析也表明,未来模型不仅需要提高准确率,还需要优化计算效率。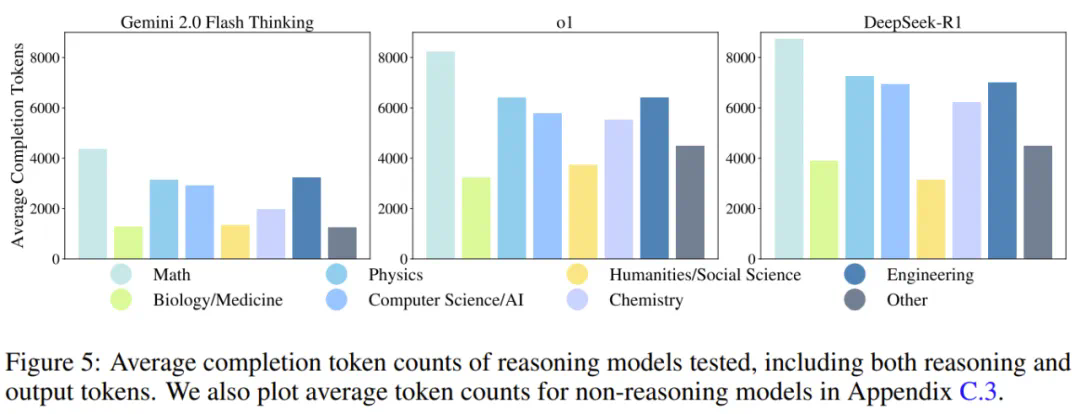
以上就是DeepSeek-R1、o1都低于10%,人类给AI的「最后考试」来了,贡献者名单长达两页的详细内容,更多请关注php中文网其它相关文章!

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 307
307




















