







月之暗面开源高效优化器muon,同等预算下性能翻倍!
月之暗面与DeepSeek再度“撞车”,这次是开源优化器Muon的较量。Muon优化器在计算效率上比AdamW提升了2倍,并已用于训练3B/16B参数的MoE模型Moonlight,刷新了当前的帕累托最优。
Muon的改进关键在于:
- 添加权重衰减: 有效解决大模型训练中权重过大问题。
- 一致的RMS更新: 确保不同形状矩阵更新的一致性,避免性能损失。
这些改进使得Muon无需调整超参数即可直接用于大规模训练。实验表明,Muon在达到与AdamW相当性能的同时,仅需约52%的训练FLOPs。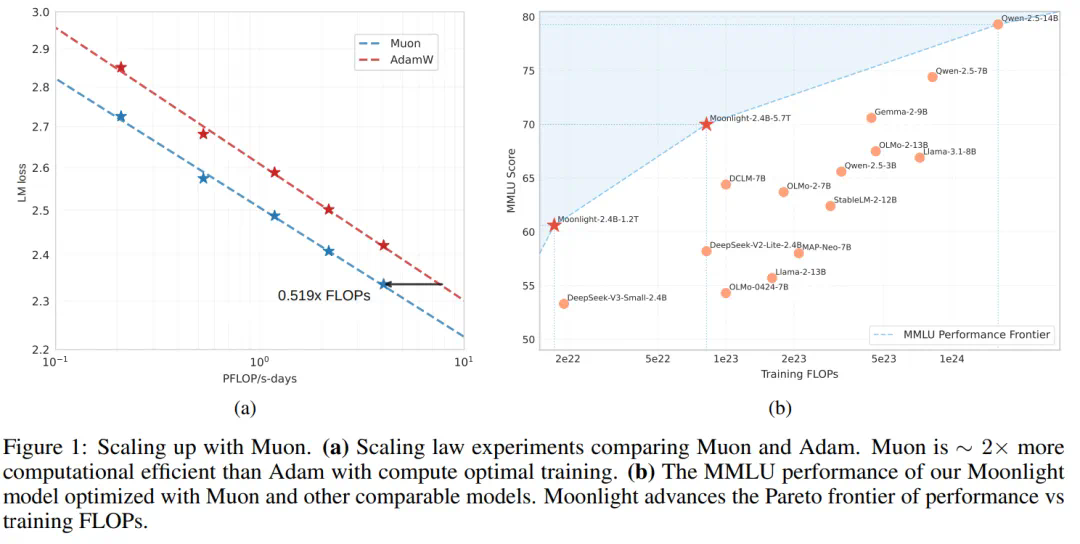
月之暗面已开源Muon的代码、预训练模型、指令微调以及中间检查点,并发布了相关论文《MUON IS SCALABLE FOR LLM TRAINING》。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


- 论文地址:https://www.php.cn/link/98b1e16f65a1500023372d2b362c0991
- 代码地址:https://www.php.cn/link/776af9671dbfa3ac15c6e0711001bdea
- 模型地址:https://www.php.cn/link/28dcee36ddc3665d679c5e8372568a31
Muon的扩展与分布式实现
研究人员发现原始Muon在大模型训练中的性能提升有限。通过添加权重衰减和实现一致的RMS更新,解决了这一问题。 此外,还提出了一种基于ZeRO-1的分布式Muon实现方案,进一步提升了训练效率。 实验结果通过图表详细展示了Muon的优越性能,包括与AdamW的比较以及不同RMS控制方法的对比。 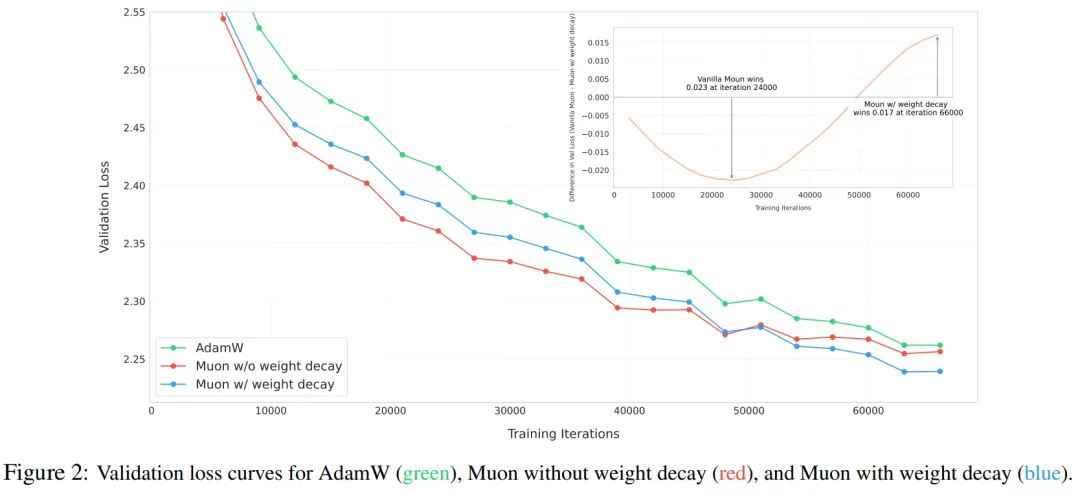

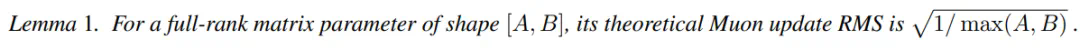
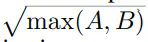




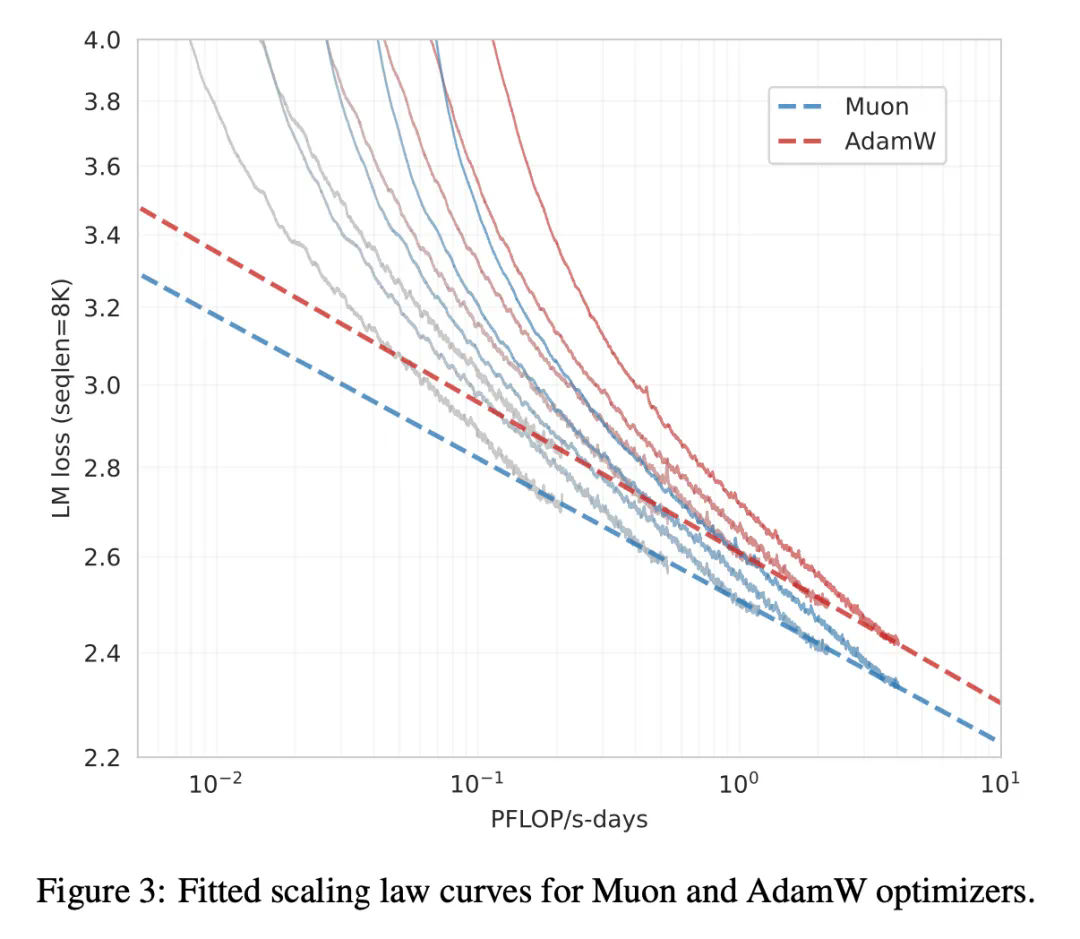

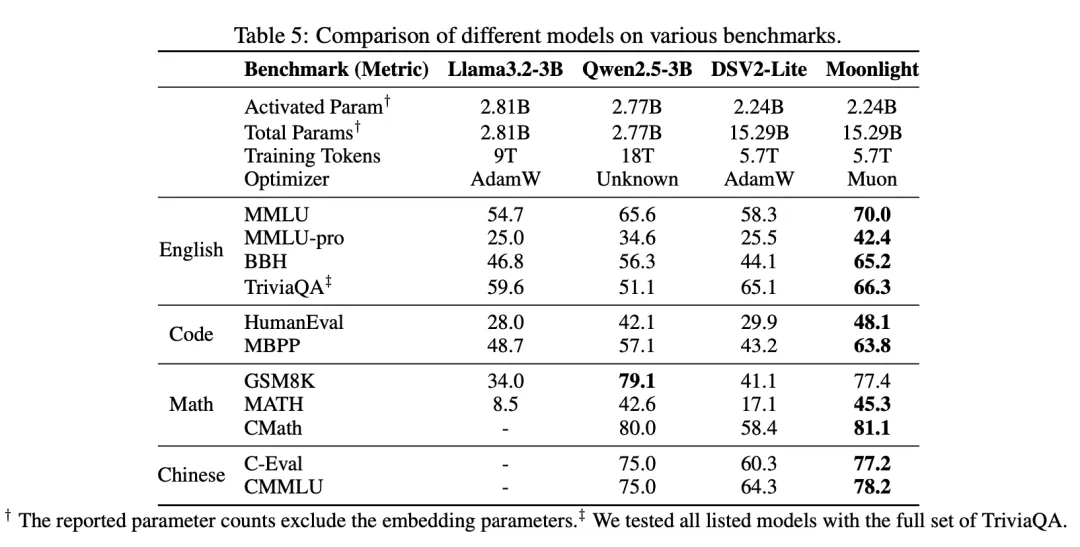
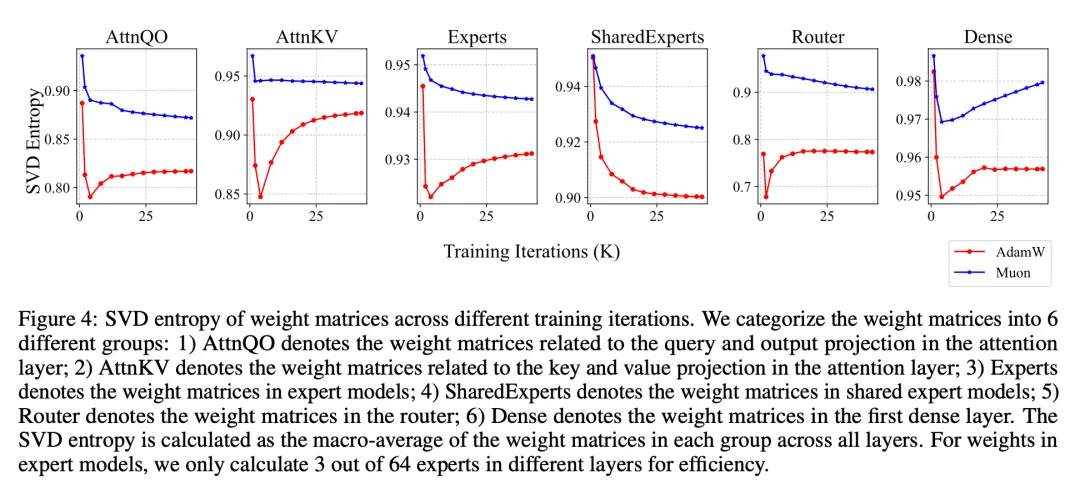
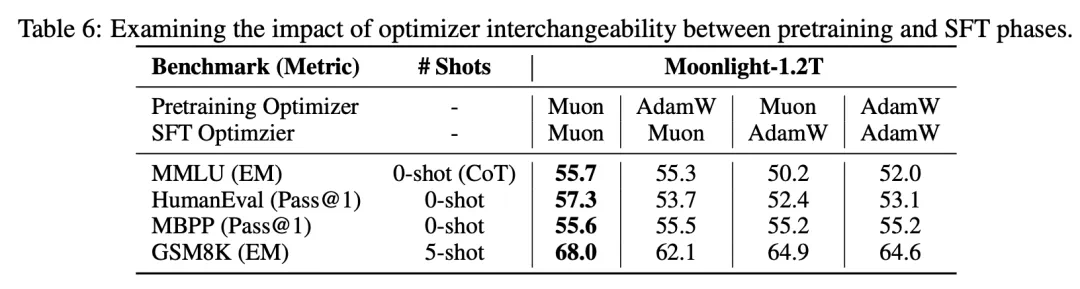
Muon的开源为大规模语言模型训练提供了新的高效方案,值得关注。




























