







仅靠逻辑益智题,竟能让AI数学竞赛水平大幅提升?DeepSeek R1的秘密武器
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

继中国大模型在技术领域取得突破后,国内团队再次带来惊喜!这项研究揭秘了DeepSeek R1模型背后的秘密:通过少量合成数据和强化学习,一个7B参数的小模型在逻辑推理测试中超越了OpenAI的o1模型,甚至逼近o3-mini-high的水平。更令人瞩目的是,在从未见过的美国数学奥林匹克(AIME)测试中,其推理能力提升了惊人的125%!
研究成果:
- 论文标题: Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
- 论文链接: https://www.php.cn/link/971c6340495b40cce8b7ef650650a599
- Github链接: https://www.php.cn/link/fb1f13df81c7bee04d8a083204858880
该研究由微软亚洲研究院和九坤投资等机构的研究人员共同完成,是首个对类似R1强化学习模型训练过程进行全面深入分析的研究。 值得强调的是,该团队不仅完整开源了全部代码,还公开了详细的参数设置、训练数据和经验总结。
研究目标:
研究团队试图解答以下关键问题:
- GRPO是否是强化学习的最佳算法?如何进行参数调整以实现稳定训练?循序渐进的课程学习是否仍然有效?
- 基于基础模型进行强化学习与完全冷启动训练有何区别?哪种方式更优?
- 模型输出长度的线性增长规律是否与推理能力的提升直接相关?
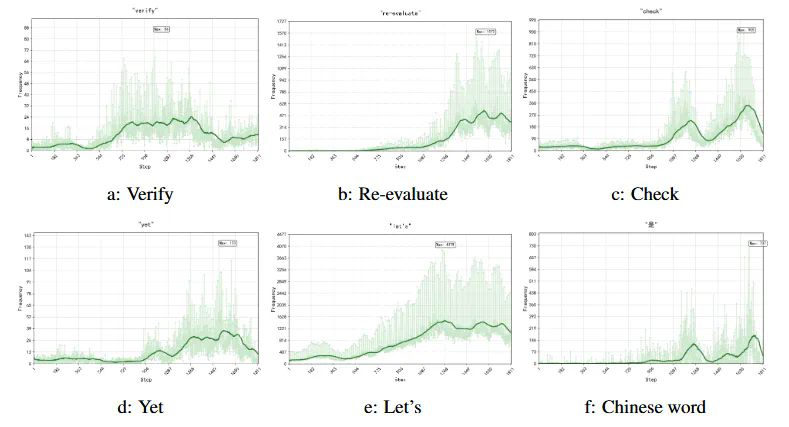
- 模型频繁使用“verify”、“check”等反思性词汇是否意味着推理能力增强?哪些词语能够可靠地反映推理能力的提升?
- 强化学习是否真正掌握了抽象推理能力,还是仅仅依赖于模式记忆?与传统的监督微调相比,强化学习的优势在哪里?
- 模型在推理过程中混用中英文是否对性能提升有帮助,甚至可能是有害的?

研究方法:
数据选择: 为了更好地分析推理模型机制,研究人员选择使用程序生成的逻辑谜题作为训练数据,例如经典的“骑士与骗子”问题。这种方法的优势在于:
- 数据是全新的,可以有效测试模型的泛化能力。
- 通过调整参数,可以控制谜题的难度。
- 每个谜题都有明确的答案,减少了奖励作弊的风险。
- 消除了自然语言任务中的模糊性,方便区分真正的推理能力和简单的模式记忆。


奖励机制: 研究人员设计了一个基于规则的奖励系统,几乎杜绝了作弊行为,主要包括格式奖励和答案奖励两种。
实验结果:
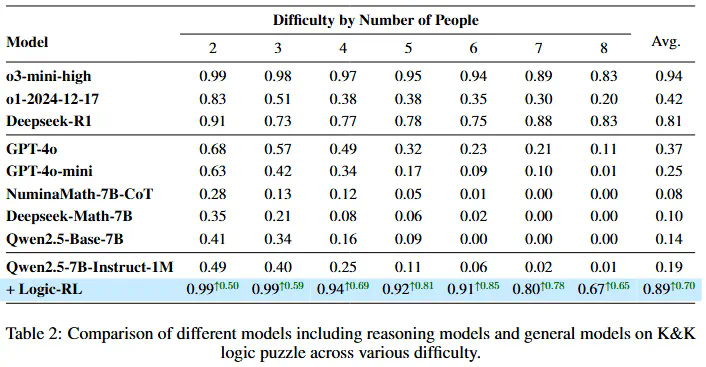
经过大量的对比实验,研究团队最终选择REINFORCE++算法,并对其进行了改进。 在经过约3600步训练后,7B参数的模型在逻辑推理测试中超越了OpenAI o1模型两倍,性能逼近o3-mini-high。
有趣的发现:
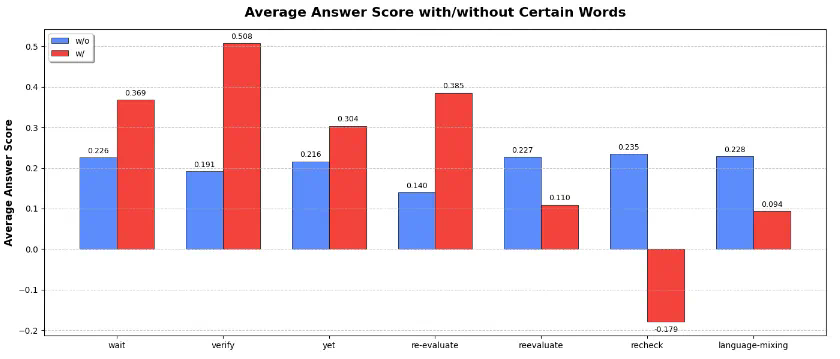
- “思考”词语与推理能力: 研究发现,“verify”、“check”等词语的出现与推理性能提升相关,但并非所有与思考相关的词语都能带来性能提升。“recheck”的出现反而会降低性能。
- 语言混用: 中英文混用会降低模型性能。
- “顿悟时刻”的缺失: 模型性能的提升是逐步进行的,并非突然出现“顿悟时刻”。
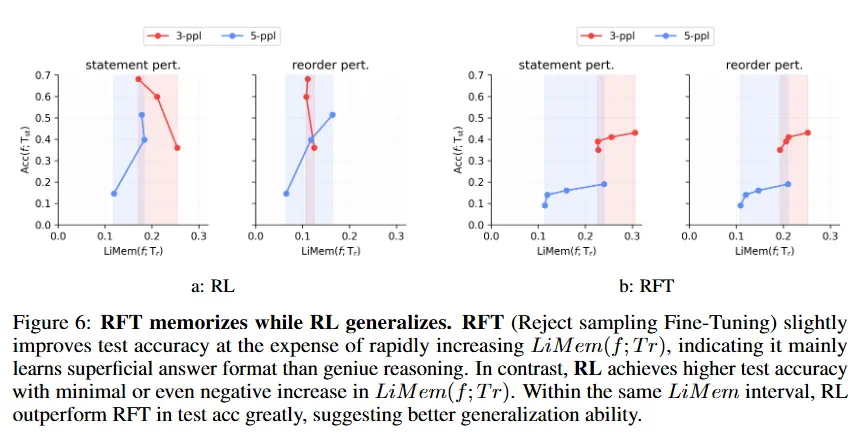
- 强化学习与监督微调的对比: 强化学习的泛化能力更强,对数据的依赖性更低。
- 输出长度与性能: 输出长度的增长并不一定代表推理能力的提升。
更多细节,请参考论文原文。 这项研究为大模型的推理能力提升提供了新的思路,也为未来AI发展提供了宝贵的经验。




























