
aixiv专栏:探索无编码器架构在3d大型多模态模型中的潜力
AIxiv专栏持续报道全球顶尖AI研究成果,已收录2000余篇来自高校和企业实验室的学术技术文章。欢迎投稿或联系报道,投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
作者简介: 本文第一作者汤轶,上海科技大学本科毕业,师从李学龙教授,并在上海人工智能实验室实习。研究方向涵盖3D视觉、大模型高效迁移、多模态大模型和具身智能等,代表作包括Any2Point, Point-PEFT, ViewRefer等。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

近年来,大型多模态模型(LMMs)研究蓬勃发展,旨在赋予大型语言模型(LLMs)解读多模态信息的能力,例如2D图像(LLaVA)和3D点云(Point-LLM, PointLLM, ShapeLLM)。主流LMMs通常依赖强大的多模态编码器(如2D的CLIP和3D的I2P-MAE),虽然这些预训练编码器提供了丰富的预先知识,但也存在局限性,例如难以适应不同点云分辨率,以及编码器提取的特征可能无法满足LLMs的语义需求。
为此,研究人员首次系统性地研究了无编码器架构在3D LMMs中的应用潜力,直接将3D编码器的功能集成到LLM中。他们提出了首个无编码器架构的3D LMM——ENEL,其7B参数模型性能与当前最先进的ShapeLLM-13B相当,展现了无编码器架构的巨大潜力。
研究背景与动机

基于编码器的3D LMMs架构存在以下不足:
技术方案
研究人员以PointLLM为基准模型,使用GPT-4评分标准在Objaverse数据集上评估不同策略。他们提出了两个关键问题:如何弥补3D编码器缺失的高层语义信息,以及如何将归纳偏置整合到LLM中以更好地感知3D几何结构。

LLM嵌入式语义编码
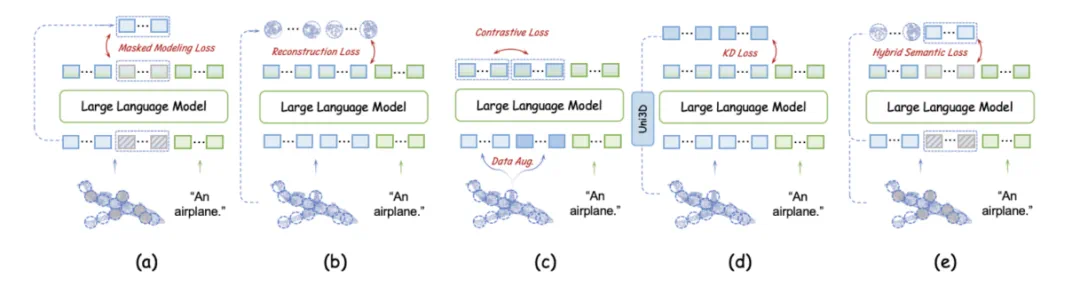
由于缺乏3D编码器,点云语义信息编码不足。研究人员评估了四种自监督学习损失(掩蔽建模、重建、对比学习和知识蒸馏)对无编码器3D LMM的影响,并提出了混合语义损失(Hybrid Semantic Loss),结合掩蔽建模和重建策略,有效地将高层语义嵌入LLM中,并保持几何一致性。
层次几何聚合策略
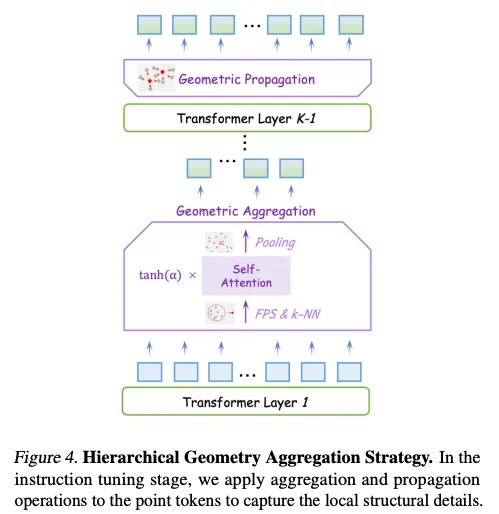
为了使LLM主动感知3D局部细节,研究人员提出了层次几何聚合策略,通过最远点采样、k-NN算法、门控自注意力机制和池化操作,逐步聚合局部几何信息,并通过几何传播将信息传递回整个点云。
实验结果
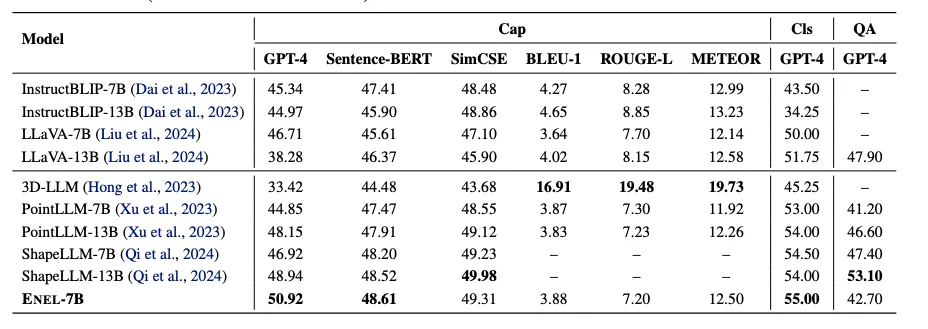
ENEL-7B在Objaverse基准测试中取得了显著成果,在3D物体描述和分类任务中均超越了之前的基于编码器的3D LMMs,并在3D-VQA任务上也表现出色。
实现细节
研究人员使用了7B Vicuna v1.1检查点,并详细描述了模型的嵌入层、训练过程(包括预训练和指令微调)、以及使用的硬件和软件配置。
这项工作为3D大型多模态模型的研究提供了新的方向,展现了无编码器架构的巨大潜力。
以上就是无编码器架构潜力或被低估,首个无编码器3D多模态LLM大模型来了的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 760
760



















