
一个pdf文件,要提取其中每章要点的内容:

Deepseek中输入提示词:
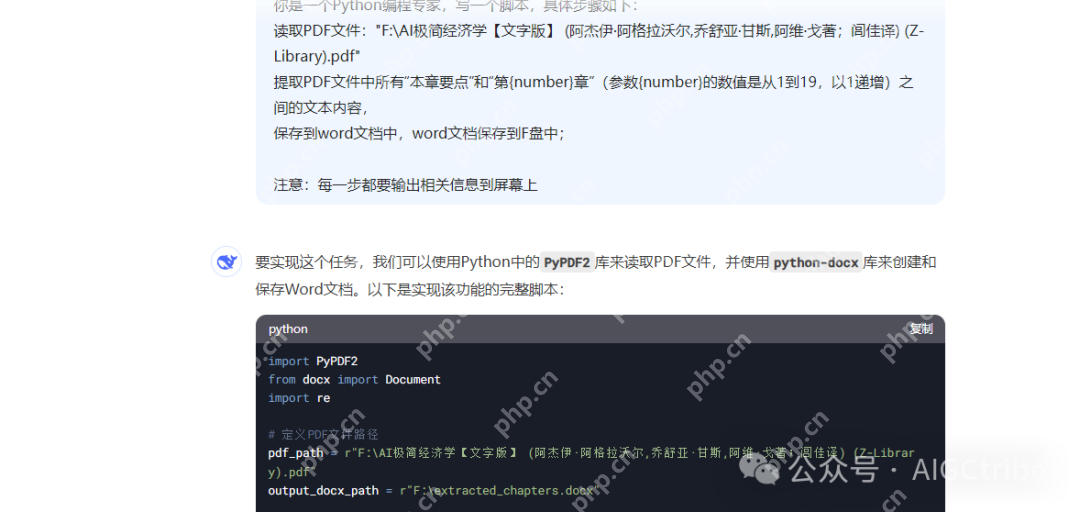
你是一个Python编程专家,写一个脚本,具体步骤如下:
读取PDF文件:"F:\AI极简经济学【文字版】 (阿杰伊·阿格拉沃尔,乔舒亚·甘斯,阿维·戈著;闾佳译) (Z-Library).pdf"
提取PDF文件中所有“本章要点”和“第{number}章”(参数{number}的数值是从1到19,以1递增)之间的文本内容,
保存到word文档中,word文档保存到F盘中;
注意:每一步都要输出相关信息到屏幕上
Deepseek的
要实现这个任务,我们可以使用Python中的PyPDF2库来读取PDF文件,并使用python-docx库来创建和保存Word文档。以下是实现该功能的完整脚本:
import PyPDF2
from docx import Document
import re
# 定义PDF文件路径
pdf_path = r"F:\AI极简经济学【文字版】 (阿杰伊·阿格拉沃尔,乔舒亚·甘斯,阿维·戈著;闾佳译) (Z-Library).pdf"
output_docx_path = r"F:\extracted_chapters.docx"
# 打开PDF文件
print(f"正在打开PDF文件: {pdf_path}")
with open(pdf_path, 'rb') as pdf_file:
reader = PyPDF2.PdfReader(pdf_file)
num_pages = len(reader.pages)
print(f"PDF文件共有 {num_pages} 页")
# 创建一个新的Word文档
doc = Document()
print("已创建新的Word文档")
# 定义正则表达式来匹配“本章要点”和“第{number}章”
chapter_pattern = re.compile(r'第(\d+)章')
key_points_pattern = re.compile(r'本章要点')
# 初始化变量
capture_text = False
current_chapter = None
extracted_text = ""
# 遍历每一页
for page_num in range(num_pages):
page = reader.pages[page_num]
text = page.extract_text()
# 查找“本章要点”和“第{number}章”
key_points_match = key_points_pattern.search(text)
chapter_match = chapter_pattern.search(text)
if key_points_match:
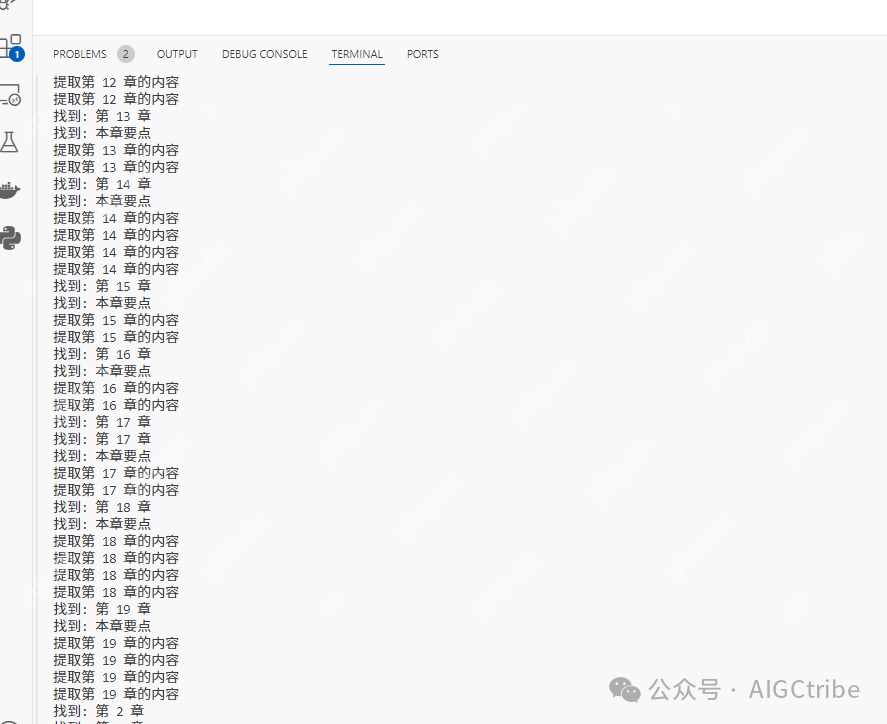
print(f"在第 {page_num + 1} 页找到 '本章要点'")
capture_text = True
extracted_text = ""
if chapter_match:
chapter_number = int(chapter_match.group(1))
print(f"在第 {page_num + 1} 页找到 '第 {chapter_number} 章'")
if capture_text and current_chapter is not None:
# 将提取的文本添加到Word文档中
doc.add_paragraph(extracted_text)
print(f"已将第 {current_chapter} 章的内容添加到Word文档")
current_chapter = chapter_number
capture_text = False
if capture_text:
extracted_text += text + "\n"
# 保存Word文档
doc.save(output_docx_path)
print(f"已将提取的内容保存到Word文档: {output_docx_path}")
脚本说明:
导入库:
PyPDF2:用于读取PDF文件。
python-docx:用于创建和保存Word文档。
re:用于正则表达式匹配。
定义文件路径:
pdf_path:PDF文件的路径。
output_docx_path:输出的Word文档路径。
打开PDF文件:
使用PyPDF2.PdfReader读取PDF文件,并获取总页数。
创建Word文档:
使用python-docx创建一个新的Word文档。
定义正则表达式:
chapter_pattern:用于匹配“第{number}章”。
key_points_pattern:用于匹配“本章要点”。
遍历PDF每一页:
使用正则表达式查找“本章要点”和“第{number}章”。
当找到“本章要点”时,开始捕获文本。
当找到“第{number}章”时,停止捕获文本,并将捕获的文本添加到Word文档中。
保存Word文档:
使用doc.save保存Word文档。
注意事项:
确保PDF文件中的文本是可提取的(有些PDF文件可能是扫描件或图像,无法直接提取文本)。
如果PDF文件中的文本格式复杂,可能需要调整正则表达式或处理逻辑。
运行脚本:
将脚本保存为.py文件并运行,脚本会自动提取指定内容并保存到Word文档中。
以上就是Deepseek批量提取PDF中特点部分的文本的详细内容,更多请关注php中文网其它相关文章!

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 563
563




















