







大家好,欢迎来到程序视点!我是小二哥。
前言:AI 模型正在迅速发展,DeepSeek-R1 作为 OpenAI 的重要竞争对手正在引起关注。究竟谁更胜一筹呢?
 这些模型对 Kotlin 的理解程度如何呢?他们能否生成可靠的代码、解释复杂的概念并帮助我们进行友好的调试呢?
这些模型对 Kotlin 的理解程度如何呢?他们能否生成可靠的代码、解释复杂的概念并帮助我们进行友好的调试呢?
研究团队使用 KotlinHumanEval 和专为 Kotlin 设计的新基准测试,测试了最新的 AI 模型,包括 DeepSeek-R1、OpenAI o1 和 OpenAI o3-mini。
团队研究了这些 AI 模型的整体表现,根据结果对它们进行了排名,并研究了 DeepSeek 对实际 Kotlin 问题的一些答案,以便让我们更清楚地了解这些模型的功能和限制。
使用 AI 模型对 Kotlin 进行基准测试:KotlinHumanEval 基准测试长期以来,评估模型的一个关键指标是它们在 OpenAI 的 HumanEval 基准测试中的性能,该基准测试测试模型从文档字符串生成函数并通过单元测试的能力。
去年,JetBrains 推出了 KotlinHumanEval——这是一个针对 Kotlin 的相同测试基准。
使用 KotlinHumanEval,使得该数据集的分数有了显著提高。这说明:专业集成的AI编程工具比原生的AI模型在代码编程上更加有针对性!
领先的 OpenAI 模型实现了开创性的 91% 成功率,其他模型紧随其后。即使是开源的 DeepSeek-R1 也可以完成这个基准测试中的大部分任务,如下所示。
 新兴基准测试:McEval
新兴基准测试:McEvalMcEval 是一个多语言基准测试,涵盖 40 种编程语言,包括 Kotlin。同样的,还有M2rc-Eval。
虽然之前的所有基准测试都主要测试模型生成代码的能力,但与之 LLMs 的交互范围不止于此。
因此,官方团队在测试基准中,不能只考虑代码生成能力。
根据用户使用习惯研究,继代码生成能力后, AI 工具最流行的用途之一是解释,例如用于错误修复和了解特定代码的作用。但是,现有的基准并不能完全衡量模型对 Kotlin 相关问题的回答程度。
怎么办呢?
Kotlin_QA基准测试(专属测试基准):为了解决上面提到的差距,团队提出了新的基准—Kotlin_QA。
团队收集了 47 个问题,这些问题由官方的开发技术推广工程师准备,或由 Kotlin 用户在 Kotlin 公共 Slack 中分享的 TOP 问题。
对于以上每个点,官方的 Kotlin 专家都提供了答案。然后,对于每个问题,研究团队要求不同的模型来回答。以下是来自 Slack 的一个示例问题:

您可以先尝试回答,然后将您的回答与您最喜欢的 LLM 回答进行比较。欢迎在评论中分享您的结果。
评估 LLMs' 答案:从不同的 LLMs 收集了答案后,下一个挑战就是评估它们的质量。
为此,团队使用了 LLM-as-a-judge 方法,要求潜在的评委模型将回答与专家答案进行比较,并从 1 到 10 分进行评分。
由于不同的 LLMs 评委模型有着不一致的评估,因此团队根据以下因素精心挑选了裁判模型:
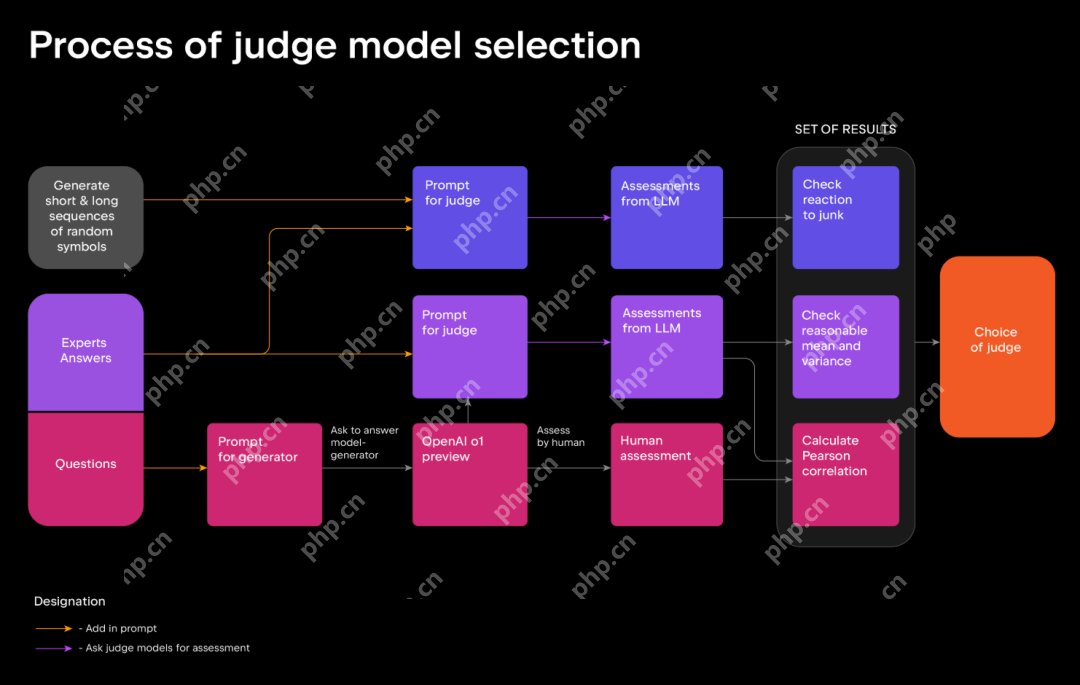 测试表明,GPT-4o(版本 08.06.2024)是最可靠的判断模型(评委模型)。原因是:它与人工评估紧密匹配,并有效地识别了低质量的答案。
测试表明,GPT-4o(版本 08.06.2024)是最可靠的判断模型(评委模型)。原因是:它与人工评估紧密匹配,并有效地识别了低质量的答案。
Kotlin_QA 排行榜:有了评判模型,现在用它来评估 LLMs 对收集到的问题的不同回答。以下是他们的排名:
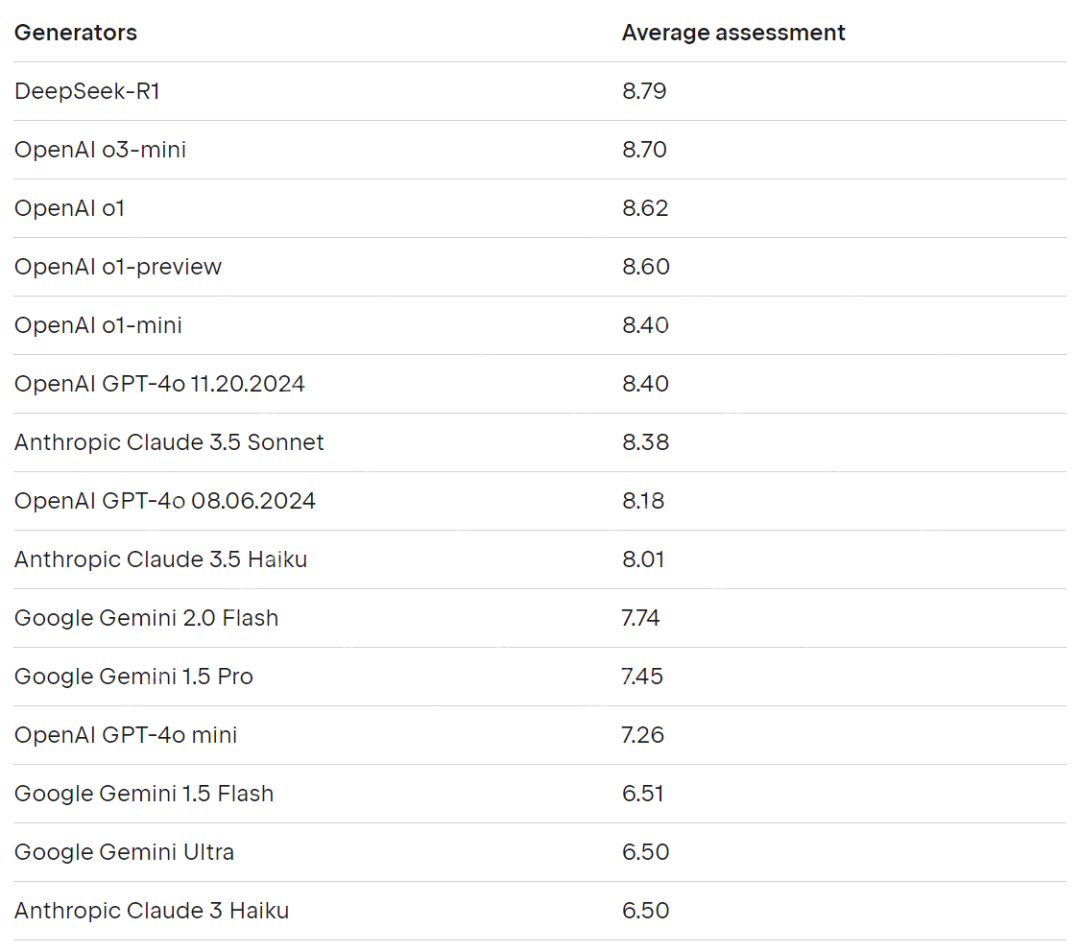 DeepSeek-R1 表现最佳。
DeepSeek-R1 表现最佳。
OpenAI 的最新模型(包括 o3-mini、o1、o1-preview 和 GPT-4o)紧随其后,取得了强劲的成绩。
Thropic 的 Claude 3.5 系列处于中等水平。
谷歌的 Gemini 型号次之,Gemini 2.0 Flash 的表现优于其他版本。
由于 DeepSeek-R1 的得分高于 OpenAI o1,而 Claude 3.5 Haiku 的表现优于 Gemini 1.5 Pro,因此推理能力更好的新模型似乎在 Kotlin 相关问题上的表现往往更好。
然而,虽然 DeepSeek-R1 的准确性很高,但它目前比 OpenAI 模型慢得多,因此对于实时使用来说不太实用。
(DeepSeek加油~~国产之AI光,咱们把速度顶上去!!)
目前,我们已经确定,这些 AI 模型非常能够讨论 Kotlin 代码。
同时,官方还通过查看性能最好的模型 DeepSeek-R1 的一些响应来检查它们的实际含义。(这一节涉及 AI 编程代码相关的内容,限于篇幅,请大家查看此条文章:模型响应示例)





























