
《深探deepseek原理应用与实践》
15.DeepSeek-V3/R1架构设计思路
在开源周的最后一天,DeepSeek分享了DeepSeek-V3/R1的架构设计思路,让大家能够更系统、更全面地了解其推理系统的设计过程,以及更深入地理解之前开源的6个项目。
 DeepSeek-V3/R1推理系统的核心目标是什么?
DeepSeek-V3/R1推理系统的核心目标是什么?
通过软件架构的优化,达到:
为什么DeepSeek选择了这条路?
曾经AI技术发展的瓶颈在于GPU。
当GPU成为瓶颈时,有两条路可走:
其一,水平扩展scale out:囤卡,堆GPU; 其二,垂直扩展scale up:GPU升级换代;
但这两条路都被牢牢控制在国外手中。
囤卡受限,不允许你囤积。 先进的卡不卖给你,因为你落后五年。
为了突破瓶颈,DeepSeek被迫走上了第三条路:通过软件优化架构。
为了实现目标,DeepSeek的核心方案是什么?
大规模的跨节点专家并行EP,Expert Parallelism。
通过增加专家并行EP的数量(batch size),提升GPU矩阵乘法的效率,从而提高吞吐量;同时,多个专家分散在不同的GPU上,每个GPU只需计算更少的专家,访问更少的数据,从而降低延迟。
大规模的跨节点专家并行EP会给软件架构带来哪些新的挑战?
大规模的跨节点专家并行EP的部署与策略是怎样的?
由于V3/R1的专家数量众多,并且每层256个专家中仅激活其中8个,DeepSeek采用多机多卡间的专家并行策略来达到以下目的:
预填充阶段:路由专家EP-32、MLA和共享专家DP-32,一个部署单元是4节点,32个冗余路由专家,每张卡9个路由专家和1个共享专家; 解码阶段:路由专家EP-144、MLA和共享专家DP-144,一个部署单元是18节点,32个冗余路由专家,每张卡2个路由专家和1个共享专家; 这两个阶段的负载均衡策略各不相同。
如何解决计算与传输并行的问题?
多机多卡的专家并行会引入较大的通信开销,因此DeepSeek使用双向通道,提高整体吞吐量。
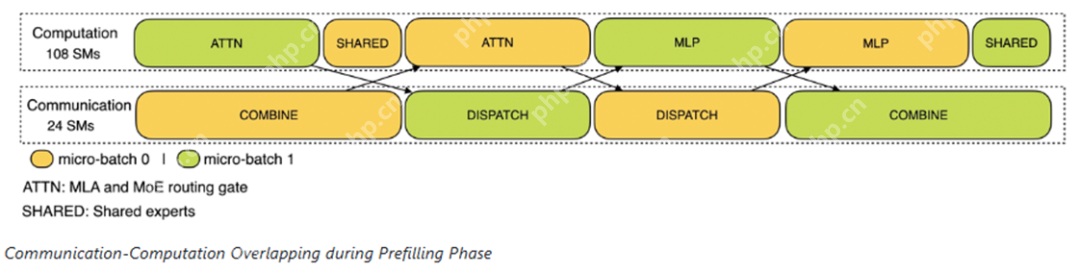 预填充阶段:计算和通信交替进行,一个通道计算时,另一个通道通信。
预填充阶段:计算和通信交替进行,一个通道计算时,另一个通道通信。
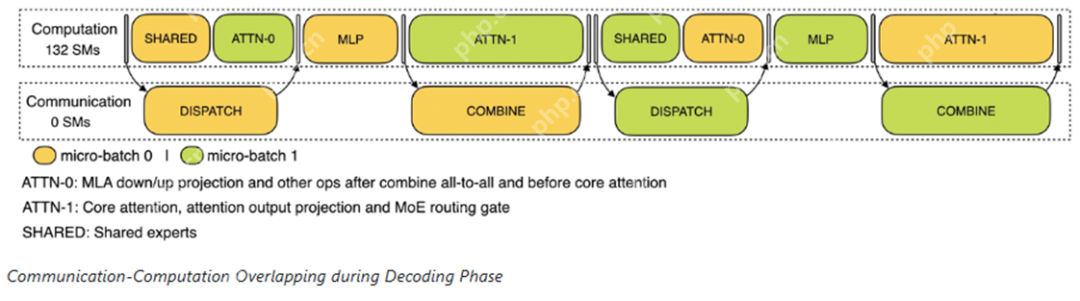 解码阶段类似:计算与通信交替进行,通过流水线实现计算和通信的重叠。
解码阶段类似:计算与通信交替进行,通过流水线实现计算和通信的重叠。
如何最大程度地实现负载均衡?
由于采用了大规模的数据并行与专家并行,如果某个GPU的计算或通信负载过重,单个长尾将成为整个系统的瓶颈。与此同时,其他GPU因为等待而空转,造成整体资源利用率下降。因此,必须尽可能地为每个GPU平均分配计算负载和通信负载。
预填充阶段(prefilling stage):
解码阶段(decoding stage):
总而言之,保证负载均衡,充分发挥GPUs的潜力,提升训练效率,缩短训练时间。
其整体架构如下:
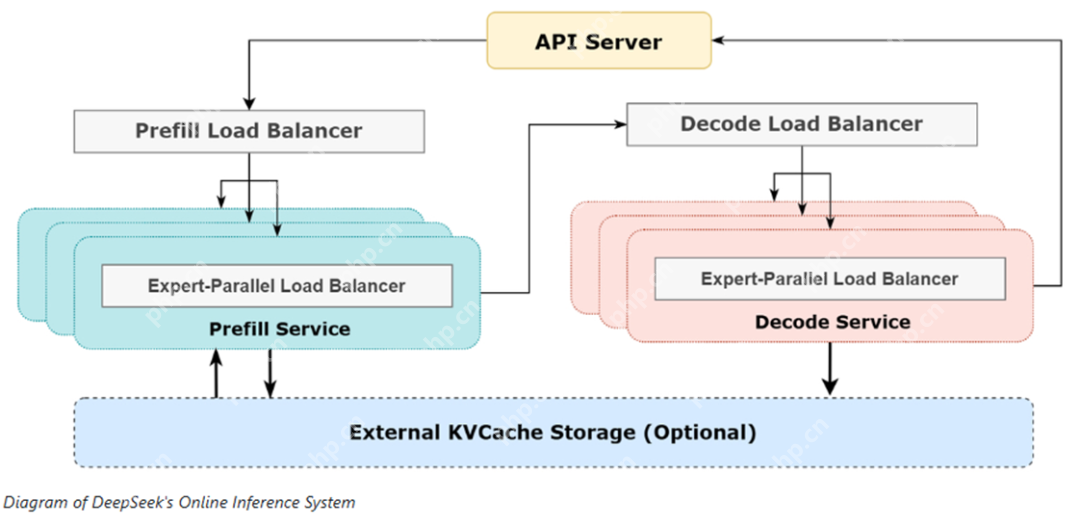 V3/R1的所有GPU均使用H800 GPU:
V3/R1的所有GPU均使用H800 GPU:
同时兼顾效率与质量。
另外,由于白天的服务负荷高,晚上的服务负荷低,因此DeepSeek实现了一套机制:
综上所述,如果所有tokens全部按照R1的定价计算,理论上DeepSeek一天的总收入为$562,027,成本利润率545%。
到这里,DeepSeek开源周的所有7个项目就介绍完了,最后再来个汇总:
补充阅读材料:
https://www.php.cn/link/2ac5f9cb8a8e89382c2fc21937c21ae6
官方git,可参考。
==全文完==
以上就是DeepSeek开源V3/R1架构设计思路,原来545%的利润率,它也只是被逼无奈?的详细内容,更多请关注php中文网其它相关文章!

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 807
807
























