
我们已经部署过windows版本、linux版本、单机版本和集群版本,并且在过程中使用了多个模型。那么,这个模型到底是什么呢?你可以选择哪些模型呢?什么是蒸馏版、满血版和量化版呢?
首先,我们需要理解什么是训练模型和推理模型。
训练模型
训练模型是指模型在学习阶段的过程。在这一阶段,模型通过大量标注数据(输入数据和对应的标签/答案)逐步调整内部参数(如神经网络的权重),目标是学习数据中的规律,从而能够对未知数据做出预测或分类。
国产大模型DeepSeek之所以火爆,是因为它以较低的成本(500万美元以上)训练出的模型达到了ChatGPT等闭源模型的性能。DeepSeek将训练的模型开源并允许商用,目前国内许多厂商都使用DeepSeek的67B模型来供普通用户使用。
注:这里的B指的是参数,参数越大,代表能力越强,一个B代表10亿参数。
推理模型
推理模型是指训练完成后,模型应用阶段的过程。此时模型参数已固定,用于对新的输入数据(未见过的数据)进行预测或分类。我们前面搭建的所有大模型都是使用DeepSeek开源的模型搭建的。
蒸馏模型
DeepSeek到目前为止开源的模型有多个,其中最火爆的是DeepSeek-R1,因为它不仅发布了67B的满血版,还发布了蒸馏版。通过知识蒸馏技术将DeepSeek-R1(参数量67B)的推理能力迁移至更小的模型中。可以简单理解为蒸馏版比原始版本更厉害。
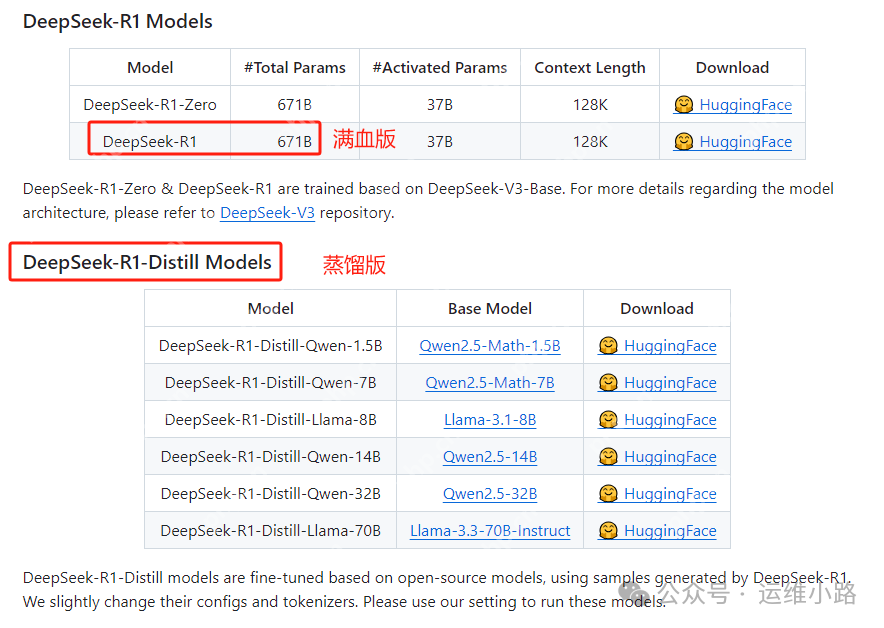
目前这些模型可以在多个大模型框架中使用(包括我们讲过的ollama和vllm,甚至未讲过的sglang等)。

由淘返利提供的清爽型淘客天下模板是经过多重杀毒软件检查,是一款开放的ASP源程序,为淘宝客免费提供服务。 后台地址:你的网址/admin/index.asp 浏览后台账 号:admin密 码:admin路 径:adminn 网站后台具有的功能1.淘宝商品推广,店铺推广及管理功能。2.超强的分类管理,商品分类随心所欲自由排序、修改分类时同步更新所属商品。3.内嵌仿Word在线编辑器,可在商品介绍、新
 0
0

量化模型
虽然这些模型对原始模型进行了蒸馏,但对于GPU的要求仍然较高。对于ollama框架来说,模型仍然较大,因此ollama对这些模型进行了进一步量化。以1.5模型为例,默认格式是fp16,原始大小是3.6G,量化一次可以降低接近50%的大小,也相对降低对显存的需求。

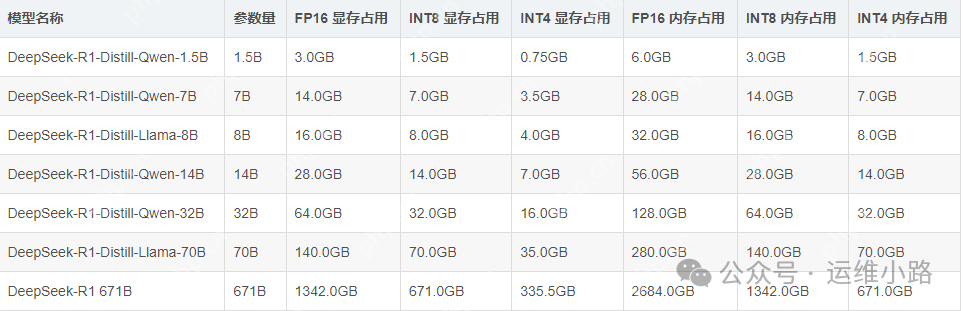
显存需求
此图是我从互联网找来,仅供参考。
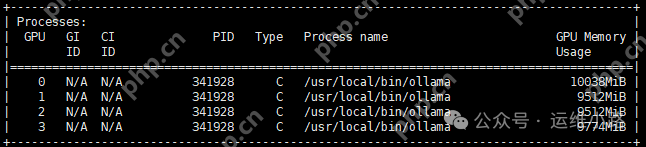
实测ollama运行deepseek-r1:32b-qwen-distill-q8_0模型,显存占用在40G左右。
vllm运行deepseek-ai/DeepSeek-R1-Distill-Qwen-14B和deepseek-ai/DeepSeek-R1-Distill-Qwen-32B模型,显存占用都是到116G(vllm会按照显存的90%去计算剩余显存,当模型等资源加载完成以后剩下的都会用作缓存)。
代码语言:javascript 代码运行次数:0
运行 复制 ```javascript (VllmWorkerProcess pid=195) INFO 03-09 10:10:40 worker.py:267] model weights take 15.41GiB; non_torch_memory takes 0.14GiB; PyTorch activation peak memory takes 0.24GiB; the rest of the memory reserved for KV Cache is 12.76GiB. ```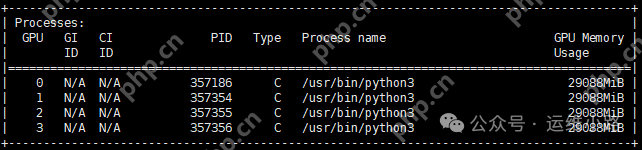
以上就是DeepSeek-模型(model)介绍的详细内容,更多请关注php中文网其它相关文章!

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号






 135
135

























