







你有没有想过,能不能像跟人聊天一样,直接问 pdf 文件或技术手册问题?比如你有一本很厚的说明书,不想一页页翻,只想问它:“这个功能怎么用?”或者“这个参数是什么意思?”现在有了 ai 技术,这完全可以实现!
这篇文章教你如何用两个工具(DeepSeek R1 和 Ollama)来搭建一个智能系统,让它帮你从 PDF 里找答案。这个系统叫 RAG(检索增强生成),简单来说就是:先找资料,再生成答案。
为什么要用 DeepSeek R1?省钱:它比 OpenAI 的模型便宜 95%,效果却差不多。精准:每次只从 PDF 里找 3 个相关片段来回答问题,避免瞎编。本地运行:不用联网,速度快,隐私也有保障。你需要准备什么?Ollama:一个让你在电脑上本地运行 AI 模型的工具。
下载地址:https://ollama.com/
ollama run deepseek-r1 # 默认用7B模型DeepSeek R1 模型:有不同大小,最小的 1.5B 模型适合普通电脑,更大的模型效果更好,但需要更强的电脑配置。
运行小模型:ollama run deepseek-r1:1.5b通用配置原则 模型显存占用(估算):
每 1B 参数约需 1.5-2GB 显存(FP16 精度)或 0.75-1GB 显存(INT8/4-bit 量化)。例如:32B 模型在 FP16 下需约 48-64GB 显存,量化后可能降至 24-32GB。内存需求:至少为模型大小的 2 倍(用于加载和计算缓冲)。
存储:建议 NVMe SSD,模型文件大小从 1.5B(约 3GB)到 32B(约 64GB)不等。
怎么搭建这个系统?第一步:导入工具包我们用 Python 写代码,需要用到一些工具包:
LangChain:处理文档和检索。Streamlit:做一个简单的网页界面。代码语言:javascript代码运行次数:0运行复制import streamlit as stfrom langchain_community.document_loaders import PDFPlumberLoaderfrom langchain_experimental.text_splitter import SemanticChunkerfrom langchain_community.embeddings import HuggingFaceEmbeddingsfrom langchain_community.vectorstores import FAISSfrom langchain_community.llms import Ollama
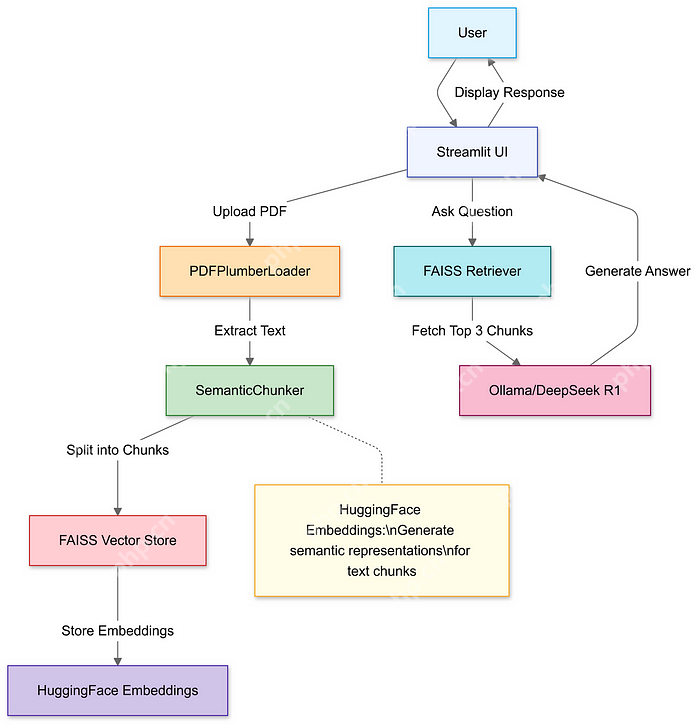
用 Streamlit 做一个上传按钮,把 PDF 传上去,然后用工具提取里面的文字。
代码语言:javascript代码运行次数:0运行复制uploaded_file = st.file_uploader("上传PDF文件", type="pdf")if uploaded_file: with open("temp.pdf", "wb") as f: f.write(uploaded_file.getvalue()) loader = PDFPlumberLoader("temp.pdf") docs = loader.load()第三步:把 PDF 切成小块PDF 内容太长,直接喂给 AI 会吃不消。所以要把文字切成小块,方便 AI 理解。
代码语言:javascript代码运行次数:0运行复制
text_splitter = SemanticChunker(HuggingFaceEmbeddings())documents = text_splitter.split_documents(docs)
把切好的文字块转换成向量(一种数学表示),存到一个叫 FAISS 的数据库里。这样 AI 就能快速找到相关内容。
代码语言:javascript代码运行次数:0运行复制embeddings = HuggingFaceEmbeddings()vector_store = FAISS.from_documents(documents, embeddings)retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # 每次找3个相关块第五步:设置 AI 模型用 DeepSeek R1 模型来生成答案。告诉它:只根据 PDF 内容回答,不知道就说“我不知道”。
代码语言:javascript代码运行次数:0运行复制llm = Ollama(model="deepseek-r1:1.5b")prompt = """1. 仅使用以下上下文。2. 如果不确定,回答“我不知道”。3. 答案保持在4句话以内。上下文: {context}问题: {question}答案:"""QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)第六步:把整个流程串起来把上传、切块、检索和生成答案的步骤整合成一个完整的系统。
代码语言:javascript代码运行次数:0运行复制llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)document_prompt = PromptTemplate( template="上下文:\n内容:{page_content}\n来源:{source}", input_variables=["page_content", "source"])qa = RetrievalQA( combine_documents_chain=StuffDocumentsChain( llm_chain=llm_chain, document_prompt=document_prompt ), retriever=retriever)第七步:做个网页界面用 Streamlit 做一个简单的网页,用户可以输入问题,系统会实时返回答案。
代码语言:javascript代码运行次数:0运行复制user_input = st.text_input("向你的PDF提问:")if user_input: with st.spinner("思考中..."): response = qa(user_input)["result"] st.write(response)
DeepSeek R1 只是开始,未来还会有更多强大的功能,比如:
自我验证:AI 能检查自己的答案对不对。多跳推理:AI 能通过多个步骤推导出复杂问题的答案。总结用这个系统,你可以轻松地从 PDF 里提取信息,像跟人聊天一样问问题。赶紧试试吧,释放 AI 的潜力!
完整代码可以在我的公众号后台 901 ,获取。





























