
摘要:deepseek和automl技术革新了深度学习模型的构建与优化。deepseek,凭借其先进的混合专家架构和多头潜在注意力技术,显著提升了模型性能,同时大幅降低了训练成本。automl则通过自动化手段,从数据预处理到超参数优化,全面提升了模型开发的效率和质量。二者结合,在智能客服、图像识别、文本分类、金融风控等多个领域展现出强大的应用潜力,为各行业的智能化发展提供了有力支持。
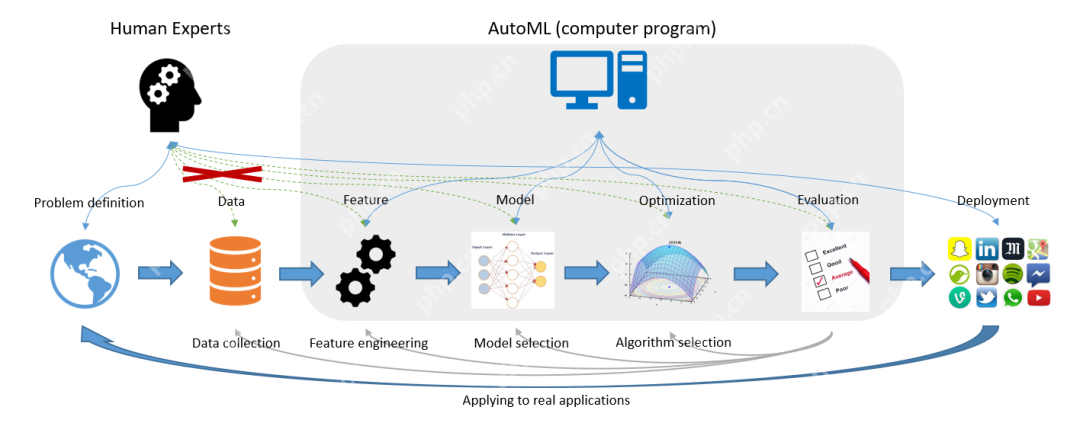
在深度学习的广袤领域中,构建高性能的模型是众多研究者和开发者不懈追求的目标。然而,随着模型复杂度的不断攀升,手动调参这一环节变得愈发艰难且耗时。想象一下,面对一个拥有成百上千个超参数的复杂神经网络,要通过人工尝试来找到最优的参数组合,这无疑是一场充满挑战的 “数字游戏”。不仅需要耗费大量的时间和计算资源,而且结果还往往不尽如人意。
为了突破这一困境,自动机器学习(AutoML)技术应运而生。AutoML 就像是一位智能助手,能够自动地为模型寻找最佳的超参数配置,极大地提高了模型训练的效率和准确性 。而在众多的 AutoML 工具和平台中,DeepSeek 凭借其卓越的性能和独特的优势,逐渐崭露头角,成为了深度学习领域中一颗耀眼的明星。它以强大的算法和高效的机制,为开发者们提供了一种全新的超参优化解决方案,使得调参过程变得更加智能、高效。接下来,就让我们一起深入探索 DeepSeek 在超参优化实战中的奥秘,全面解析 AutoML 调参的技术细节和应用技巧。
AutoML,即自动化机器学习(Automated Machine Learning) ,是一种能够自动完成机器学习模型构建和优化过程的技术。它涵盖了从数据预处理、特征工程、模型选择到超参数优化等一系列机器学习任务的自动化实现。传统的机器学习流程需要数据科学家花费大量时间和精力在各个环节进行手动操作和调整,而 AutoML 的出现极大地改变了这一现状。
在实际应用中,AutoML 展现出了诸多重要价值。以医疗领域为例,研究人员利用 AutoML 技术对大量的医疗影像数据进行分析,自动选择合适的模型和超参数,能够快速准确地识别疾病特征,提高疾病诊断的准确率 。在金融行业,AutoML 可以帮助银行自动处理海量的客户数据,构建信用风险评估模型,自动调整模型参数以适应不断变化的市场环境,从而更精准地评估客户的信用风险,降低金融风险。
在机器学习模型中,超参数是在模型训练之前需要人为设定的参数,它们对模型的训练过程和最终性能有着至关重要的影响。
学习率(Learning Rate):它决定了模型在训练过程中参数更新的步长。如果学习率设置过大,模型在训练时可能会跳过最优解,导致无法收敛,损失函数出现剧烈波动甚至上升。例如,在训练一个简单的线性回归模型时,若学习率设置为 1,模型参数可能会在每次更新时变化过大,使得模型无法拟合数据 。相反,若学习率设置过小,模型的训练速度会非常缓慢,需要更多的训练轮次才能收敛,甚至可能陷入局部最优解。一般来说,初始学习率常设置为 0.01、0.001 等,在训练过程中还可以采用学习率衰减策略,如每经过一定的训练轮次,将学习率乘以一个衰减因子(如 0.9),让模型在训练初期能够快速收敛,后期能更精确地调整参数。批量大小(Batch Size):指的是在一次迭代中用于计算梯度并更新模型参数的数据样本数量。较大的批量大小可以充分利用计算资源,加速训练过程,因为一次处理更多的数据可以减少计算梯度的次数,提高计算效率。但如果批量大小过大,模型可能会陷入较差的局部最小值,并且对内存的需求也会增加,容易导致内存不足的问题。例如在训练神经网络时,当批量大小设置为 1024,模型在训练时内存占用明显增加。较小的批量大小则可以提供更多的随机性,有助于模型跳出局部最小值,提升模型的泛化能力,但会增加训练的迭代次数和时间。通常,批量大小会选择 2 的幂次方,如 32、64、128 等,不过也需要根据具体的数据集和模型进行调整。迭代次数 / 训练轮数(Epochs):表示模型在整个训练数据集上进行训练的次数。如果迭代次数过少,模型可能无法充分学习数据中的特征和规律,导致欠拟合,在训练集和测试集上的表现都较差。例如在训练一个图像分类模型时,只训练 5 个 epoch,模型可能无法准确识别图像中的各种类别。而如果迭代次数过多,模型可能会过拟合,即对训练数据过度学习,在训练集上表现良好,但在测试集等新数据上的泛化能力很差。在实际应用中,需要通过监控模型在验证集上的性能来确定合适的迭代次数,当验证集上的性能不再提升甚至下降时,就可以停止训练。正则化参数(Regularization Parameter):常见的有 L1 和 L2 正则化系数。正则化的主要作用是防止模型过拟合,通过在损失函数中添加正则化项,对模型的复杂度进行约束。L1 正则化会使模型的某些参数变为 0,从而实现特征选择的效果,得到一个稀疏模型;L2 正则化则是使参数值变小,让模型更加平滑。以 L2 正则化为例,如果正则化系数设置过小,对模型复杂度的约束作用不明显,模型容易过拟合;如果设置过大,模型可能会过于简单,出现欠拟合现象。在逻辑回归模型中,通过调整 L2 正则化系数,可以平衡模型对训练数据的拟合能力和泛化能力。网络架构相关参数:以神经网络为例,层数和每层的神经元数量是重要的超参数。增加网络层数可以使模型学习到更复杂的特征表示,但也容易导致梯度消失或梯度爆炸问题,增加训练的难度,同时还可能出现过拟合。例如在一个多层感知机中,当层数从 3 层增加到 10 层时,模型的训练难度明显加大,需要更复杂的训练技巧和更长的训练时间。每层的神经元数量也影响着模型的学习能力,神经元数量过少,模型可能无法学习到足够的特征;神经元数量过多,则会增加模型的复杂度和计算量,同样容易引发过拟合。在设计神经网络架构时,需要根据具体的任务和数据特点来合理选择层数和神经元数量。
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司 ,成立于 2023 年 7 月,是一家专注于通用人工智能(AGI)研发的创新型公司。尽管成立时间不长,但凭借着在人工智能领域的卓越技术创新和高效实践,DeepSeek 迅速在竞争激烈的 AI 市场中崭露头角,成为了行业内备受瞩目的新星。
在技术创新方面,DeepSeek 展现出了强大的实力。其研发的大语言模型采用了先进的混合专家架构(MoE),这种架构允许模型在处理不同任务时,动态地激活最合适的 “专家” 模块,从而大大提高了模型的效率和性能 。例如,在处理文本生成任务时,模型可以自动调用擅长语言生成的专家模块,使得生成的文本更加流畅、自然。同时,DeepSeek 还引入了多头潜在注意力(MLA)技术,通过对注意力键和值进行低秩联合压缩,有效减少了推理过程中的键值缓存(KV cache),降低了推理时的内存占用,使得模型在处理长上下文时更加得心应手 。在训练 DeepSeek-V3 模型时,运用 MLA 技术,使得模型在处理长篇文章时,能够快速准确地理解文章的主旨和细节,提高了处理效率和准确性。
在模型训练成本上,DeepSeek 也展现出了显著的优势。以 DeepSeek-V3 模型为例,其训练成本仅为约 558 万美元 ,而 Meta 同规格的 Llama 3.1 模型训练成本约 9240 万美元,DeepSeek 的训练成本大幅低于同类模型,仅为其约 1/16。这种低成本的训练模式,使得更多的研究机构和企业能够以较低的成本使用先进的 AI 技术,加速了 AI 技术的普及和应用。在推理成本方面,DeepSeek V3 和 R1 模型的价格分别为 OpenAI GPT-4o 和 o1 模型的十分之一和二十分之一 ,进一步降低了用户的使用门槛,使得更多用户能够享受到高效的 AI 服务。
此外,DeepSeek 采取了完全开源的策略,其模型和代码完全开源,符合开放源代码促进会(OSI)发布的开源 AI 定义 1.0(OSAID 1.0)的所有要求 。这一举措吸引了全球大量开发者的关注和参与,截至目前,已有超过 10 万开发者加入到 DeepSeek 的开源社区中,共同推动 AI 技术的创新和发展。开源策略不仅促进了技术的快速传播和创新,也为 DeepSeek 赢得了良好的口碑和广泛的支持,使其在 AI 领域的影响力不断扩大。
DeepSeek 的超参优化技术是其实现高效模型训练的关键之一,它基于一套复杂而精妙的原理,旨在自动为模型选择最合适的超参数组合,从而提升模型的性能和效率。
在模型选择方面,DeepSeek 利用了先进的机器学习算法和元学习技术。它会根据输入数据的特点,如数据的规模、特征分布、数据类型等,从预先构建的模型库中自动挑选出最适合的基础模型架构。如果输入数据是图像数据,且数据量较大,DeepSeek 可能会选择适合处理大规模图像数据的卷积神经网络架构,并根据具体任务需求,如分类、目标检测等,对模型进行进一步的定制和优化 。在处理医疗影像数据进行疾病诊断时,DeepSeek 会根据影像数据的分辨率、图像模态(如 X 光、CT 等)以及疾病类型等因素,选择合适的卷积神经网络模型,并调整模型的参数,以适应医疗影像分析的特殊需求。
对于超参数的调整,DeepSeek 采用了基于贝叶斯优化的方法 。贝叶斯优化是一种基于概率模型的优化算法,它通过构建一个关于超参数和模型性能之间关系的概率模型(通常是高斯过程),利用已经尝试过的超参数组合及其对应的模型性能来更新这个概率模型,从而预测不同超参数组合下模型性能的概率分布。在这个过程中,DeepSeek 通过不断地迭代试验,利用采集函数(如期望提升,Expected Improvement)来平衡探索(尝试新的超参数组合)和利用(选择那些根据当前模型预测性能较好的超参数组合),逐步逼近最优的超参数配置 。在训练一个深度学习模型时,DeepSeek 首先会随机尝试一些超参数组合,并评估这些组合下模型在验证集上的性能。然后,利用这些试验结果构建高斯过程模型,预测不同超参数组合下模型性能的概率分布。根据期望提升采集函数,选择下一个超参数组合进行试验,不断重复这个过程,直到找到性能最优的超参数组合。
在数据预处理和特征工程环节,DeepSeek 也实现了自动化。它能够自动对输入数据进行清洗、归一化、标准化等预处理操作,以提高数据的质量和可用性 。同时,DeepSeek 还能自动从原始数据中提取和生成有价值的特征,通过特征选择和特征组合技术,找到对模型性能影响最大的特征子集。在处理文本数据时,DeepSeek 会自动进行词法分析、句法分析等操作,提取文本的关键特征,如词向量、词性标签等,并通过特征组合生成更具代表性的特征,从而提高文本分类、情感分析等任务的模型性能。
(三)DeepSeek 超参优化优势数据自动处理与清洗:DeepSeek 具备强大的数据自动处理和清洗能力,能够快速识别并处理数据中的噪声、缺失值和异常值 。在处理大规模图像数据集时,它可以自动检测并修复图像中的模糊区域、划痕等噪声,同时对图像进行归一化处理,使得不同图像的数据特征处于同一尺度,提高了数据的质量和一致性,为后续的模型训练提供了可靠的数据基础。这种自动化的数据处理方式,不仅节省了大量的人力和时间成本,还避免了人工处理可能出现的错误和偏差 。智能特征工程:DeepSeek 的智能特征工程技术能够自动从原始数据中挖掘出最具代表性和判别力的特征。在处理金融数据时,它可以自动提取诸如交易金额、交易频率、用户信用评级等关键特征,并通过特征组合和变换生成新的特征,如交易金额与用户信用评级的关联特征等 。这些经过精心设计的特征能够更好地反映数据的内在规律,提高模型对数据的理解和学习能力,从而显著提升模型的预测准确性和泛化能力 。自动模型选择与优化:DeepSeek 能够根据数据的特点和任务需求,从众多的模型架构中自动选择最合适的模型,并对其超参数进行优化。在进行图像分类任务时,它可以根据图像的分辨率、类别数量等因素,自动选择如 ResNet、VGG 等适合的卷积神经网络架构,并通过超参优化找到最佳的参数配置 。这种自动模型选择和优化的功能,使得用户无需具备深厚的机器学习专业知识,也能轻松获得高性能的模型,大大降低了模型开发的门槛和难度 。可视化反馈与结果分析:DeepSeek 提供了直观的可视化反馈和详细的结果分析工具。在超参优化过程中,它可以实时展示模型性能随超参数变化的趋势图,让用户清晰地了解不同超参数组合对模型性能的影响 。在训练神经网络时,DeepSeek 会绘制学习率与模型准确率的关系曲线,用户可以通过观察曲线,直观地看到学习率在不同取值下模型准确率的变化情况,从而更好地理解超参数的作用和影响。同时,DeepSeek 还会对优化后的模型结果进行详细分析,提供诸如模型的准确率、召回率、F1 值等评估指标,帮助用户全面评估模型的性能 。四、DeepSeek 超参优化实战步骤
<code class="javascript">from deepseek import HyperparameterTuner# 定义超参数搜索空间param_space = { "learning_rate": [0.0001, 0.001, 0.01], "batch_size": [16, 32, 64], "num_layers": [2, 3, 4]}# 初始化调优器tuner = HyperparameterTuner(model, param_space, optimizer='Bayesian', metric='accuracy')# 运行调参best_params, best_score = tuner.tune(dataset)</code>在运行调参过程中,DeepSeek 会根据选择的调参算法,在超参数搜索空间中不断尝试不同的超参数组合,并训练模型、评估模型性能。
2. 监控指标:在调参过程中,需要实时监控模型的性能指标,如准确率、损失函数值等。DeepSeek 通常会提供可视化工具,以图表的形式展示模型性能随超参数变化的趋势。例如,它可以绘制学习率与准确率的关系曲线,让你直观地看到不同学习率下模型准确率的变化情况 。通过监控这些指标,你可以了解模型的训练状态,判断调参过程是否朝着预期的方向进行。如果发现某个超参数的变化导致模型性能急剧下降,可能需要调整超参数的取值范围或重新选择调参算法 。
3. 解读结果选择最优超参数组合:当调参过程结束后,DeepSeek 会返回最优的超参数组合及其对应的模型性能指标。例如,返回的结果可能是best_params = {'learning_rate': 0.001, 'batch_size': 32, 'num_layers': 3} ,best_score = 0.95 ,这表示在学习率为 0.001、批量大小为 32、网络层数为 3 的超参数组合下,模型在验证集上的准确率达到了 0.95 。在解读结果时,要综合考虑模型的性能和实际应用需求。如果模型在验证集上的准确率很高,但在测试集上的表现不佳,可能存在过拟合问题,需要进一步调整超参数或采取正则化等措施 。同时,还要考虑模型的训练时间和计算资源消耗,选择在性能和资源消耗之间达到最佳平衡的超参数组合。
本案例聚焦于图像分类领域,旨在通过对大量的花卉图像进行分类,识别出不同种类的花卉。所使用的数据集为公开的 Flowers 数据集,其中包含了 1000 张不同花卉的图像,涵盖了玫瑰、郁金香、向日葵等 5 个不同的花卉类别,每个类别各有 200 张图像。在数据集划分上,按照 80%、10%、10% 的比例将其分为训练集、验证集和测试集 ,即训练集包含 800 张图像,验证集和测试集各包含 100 张图像。
选用的模型为经典的卷积神经网络(Convolutional Neural Network,CNN),具体为 ResNet-18 模型 。ResNet-18 模型以其独特的残差结构,能够有效解决深层神经网络训练过程中的梯度消失和梯度爆炸问题,从而可以构建更深层次的网络结构,学习到更复杂的图像特征,在图像分类任务中表现出色。在本案例中,初始的模型设置存在超参数选择不够优化的问题,导致模型在训练过程中的收敛速度较慢,并且在测试集上的准确率仅为 70%,未能达到预期的性能要求。因此,需要使用 DeepSeek 进行超参优化,以提升模型的性能。

<code class="javascript">param_space = { "learning_rate": [0.0001, 0.001, 0.01], "batch_size": [16, 32, 64], "num_residual_blocks": [16, 18, 20], # 对应网络层数调整 "num_filters_conv1": [64, 128, 256], # 第一层卷积层的滤波器数量,代表神经元数量 "num_units_fc": [128, 256, 512] # 全连接层的神经元数量}</code>3.选择调参算法:选择贝叶斯优化算法作为调参算法,因为其在处理复杂超参数空间时,能够利用已有的试验结果来指导后续搜索,提高搜索效率,减少不必要的计算资源浪费 。在 DeepSeek 中,通过设置optimizer='Bayesian'来指定使用贝叶斯优化算法。
4.运行调参:调用 DeepSeek 的超参优化函数,将模型定义(ResNet-18 模型)、数据集(训练集和验证集)、超参数搜索空间和调参算法等参数传入。
代码语言:javascript代码运行次数:0运行复制<code class="javascript">from deepseek import HyperparameterTunerfrom torchvision.models import resnet18from torchvision import datasets, transformsfrom torch.utils.data import DataLoader# 定义数据变换transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 加载数据集train_dataset = datasets.ImageFolder('train_data_path', transform=transform)val_dataset = datasets.ImageFolder('val_data_path', transform=transform)train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False)# 初始化模型model = resnet18(num_classes=5)# 初始化调优器tuner = HyperparameterTuner(model, param_space, optimizer='Bayesian', metric='accuracy')# 运行调参best_params, best_score = tuner.tune((train_loader, val_loader))</code>在调参过程中,DeepSeek 会根据贝叶斯优化算法,在超参数搜索空间中不断尝试不同的超参数组合。每次尝试都会训练模型,并在验证集上评估模型的准确率。通过多次迭代,逐渐逼近最优的超参数组合。
在本次 DeepSeek 超参优化实战中,我们深入探索了 AutoML 调参的强大能力和 DeepSeek 的卓越性能。通过一系列的操作步骤,从前期的数据准备、超参数搜索空间的精心设置,到调参算法的合理选择以及调参过程的严谨执行和结果分析,我们成功地利用 DeepSeek 对模型进行了超参优化。在图像分类案例中,优化后的模型在测试集上的准确率从 70% 大幅提升至 85%,损失值显著下降,训练时间也大幅缩短。这一显著的成果充分证明了 DeepSeek 在超参优化方面的有效性和高效性。它能够自动处理数据、进行智能特征工程、实现自动模型选择与优化,并提供可视化反馈与结果分析,为我们节省了大量的时间和精力,同时提升了模型的性能和质量。

展望未来,AutoML 调参技术有望在多个方面取得进一步的发展。在算法改进方面,将不断涌现更加高效、智能的调参算法,这些算法将能够更快速、更准确地搜索到最优的超参数组合,减少计算资源的浪费和训练时间。贝叶斯优化算法可能会在处理高维超参数空间时取得更大的突破,提高其在复杂问题中的性能表现。同时,AutoML 调参技术将与其他前沿技术实现更深度的融合。与深度学习结合,实现神经网络架构的自动搜索和超参数的动态调整,进一步提升深度学习模型的性能和效率;与强化学习结合,利用强化学习的反馈机制,让模型在训练过程中自动学习并调整超参数,实现更加智能化的调参过程。此外,随着边缘计算和物联网的发展,AutoML 调参技术也将逐渐向边缘设备扩展,实现在资源受限的环境下进行高效的模型优化。
(三)对读者的建议对于广大读者而言,DeepSeek 和 AutoML 调参技术为我们提供了强大的工具和方法,能够显著提升模型开发的效率和质量。建议读者在实际项目中积极应用这些技术,勇于尝试不同的调参算法和策略,不断积累经验。同时,要持续关注 AutoML 调参技术的发展动态,学习新的算法和理念,不断提升自己在这一领域的技术水平。在面对复杂的模型和数据时,不要畏惧挑战,充分利用 DeepSeek 等工具的优势,探索最优的超参数配置,为实现项目的成功奠定坚实的基础。通过不断的实践和学习,相信大家都能在深度学习的领域中取得更好的成果,为推动人工智能技术的发展贡献自己的力量。

DeepSeek 官方GitHub仓库:DeepSeek GitHub
ONNX 官方网站:ONNX Official Website
DeepSeek 文档:DeepSeek Documentation
ONNX 文档:ONNX Documentation
DeepSeek 示例代码:Python
代码语言:javascript代码运行次数:0运行复制<code class="javascript">from deepseek import DeepSeek# 初始化DeepSeek模型model = DeepSeek()# 使用模型进行文本生成text = "这是一个测试文本"response = model.generate(text)print(response)</code>
ONNX 示例代码:Python
代码语言:javascript代码运行次数:0运行复制<code class="javascript">import onnxruntimeimport numpy as np# 加载ONNX模型session = onnxruntime.InferenceSession("model.onnx")# 准备输入数据input_data = np.random.randn(1, 3, 224, 224).astype(np.float32)# 进行推理input_name = session.get_inputs()[0].nameoutput_name = session.get_outputs()[0].nameresult = session.run([output_name], {input_name: input_data})print(result)</code>感谢您耐心阅读本文。希望本文能为您提供有价值的见解和启发。如果您对《DeepSeek超参优化实战:AutoML调参全解析,解锁AI性能密码(16/18)》有更深入的兴趣或疑问,欢迎继续关注相关领域的最新动态,或与我们进一步交流和讨论。让我们共同期待[DeepSeek超参优化实战-AutoML调参全解析]在未来的发展历程中,能够带来更多的惊喜和突破。
再次感谢,祝您拥有美好的一天!
以上就是DeepSeek超参优化实战:AutoML调参全解析,解锁AI性能密码(16/18)的详细内容,更多请关注php中文网其它相关文章!

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 380
380























