
在上一篇关于提示工程(prompt engineering)的文章中,我们讨论了提示的概念。提示通过改变语言模型(llm)的输入来影响其输出,提示对词汇的分布极为敏感,即使是微小的变化也可能导致显著的差异。虽然通过提示可以调整模型在词汇上的分布,但当我们需要将一个在特定领域训练的模型应用到全新领域时,仅靠提示是不够的。与此相反,训练过程则涉及到直接修改模型的参数。简单来说,训练过程是通过向模型提供输入,让模型预测输出,并根据预测结果调整参数,使模型的下一次输出更接近正确答案。
模型训练是改变词汇分布的关键方法。从零开始训练一个模型需要巨大的成本,对于大多数用户来说这几乎是不可能的任务。因此,用户通常会选择一个在大规模数据上预训练的模型进行进一步的训练。这些预训练模型通常是在通用任务或数据集上训练的,具备学习一般特征和模式的能力。常见的训练类型包括Fine-tuning(微调)、Parameter-Efficient Fine-Tuning(参数高效微调)、Soft Prompting(软提示)以及Continue Pre-training(持续预训练)等。
模型训练需要消耗大量的硬件资源,下面是基于OCI(Oracle Cloud Infrastructure)的不同训练方法的硬件成本示例:
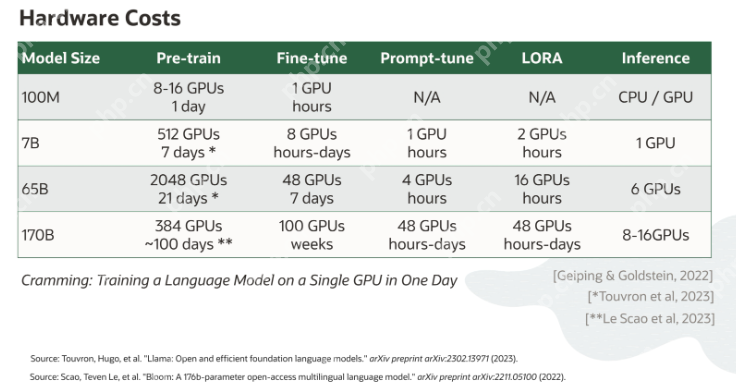
通过以上方法和成本分析,用户可以根据自己的需求和预算选择最合适的训练策略。
以上就是模型训练的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 475
475



















