
qwen2.5-omni-3b 是由阿里巴巴 qwen 团队推出的一款轻量级多模态 ai 模型。它是 qwen2.5-omni-7b 的精简版本,专门为消费级硬件设计,支持文本、音频、图像和视频等多种输入功能。参数量从 7b 减少到 3b,但仍能保持 7b 模型 90% 以上的多模态性能,尤其在实时文本生成和自然语音输出方面表现突出。处理 25,000 token 的长上下文输入时,显存占用减少了 53%,从 7b 模型的 60.2gb 降至 28.2gb,可以在 24gb gpu 的设备上运行。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
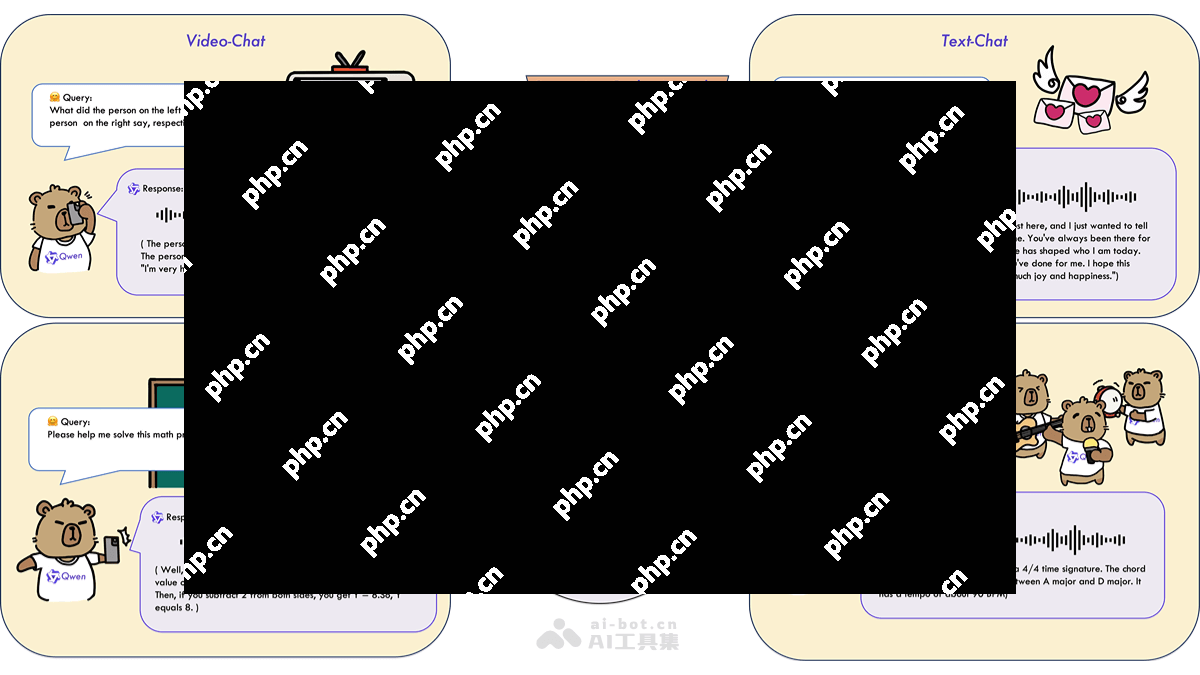
Qwen2.5-Omni-3B的主要功能包括:
Qwen2.5-Omni-3B的技术原理包括:
Qwen2.5-Omni-3B的项目地址为:
Qwen2.5-Omni-3B的应用场景包括:
以上就是Qwen2.5-Omni-3B— 阿里 Qwen 团队推出的轻量级多模态 AI 模型的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 392
392



















