
运行平台:Windows Python版本:Python3.6 IDE:Sublime Text 其他工具:Chrome浏览器
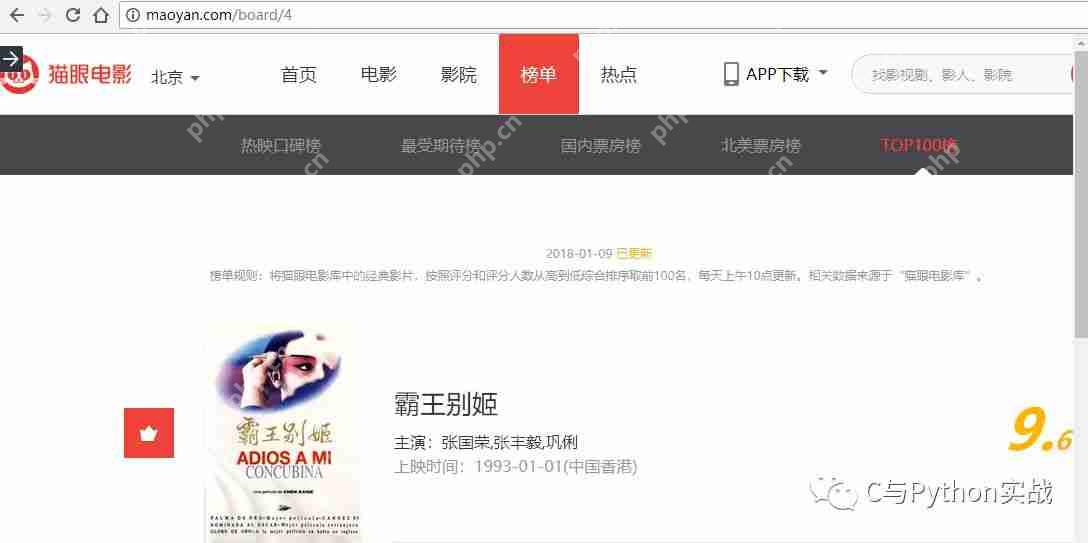 接下来,我们通过编写代码来提取网页的HTML内容。
接下来,我们通过编写代码来提取网页的HTML内容。
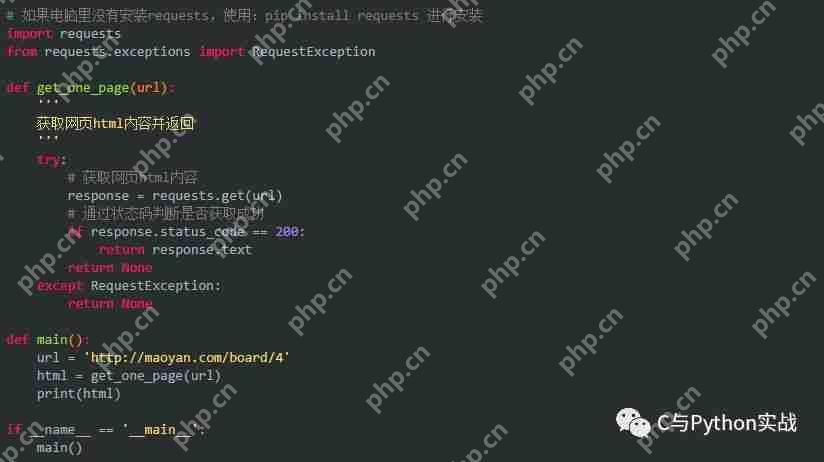 运行结果如下:
运行结果如下:
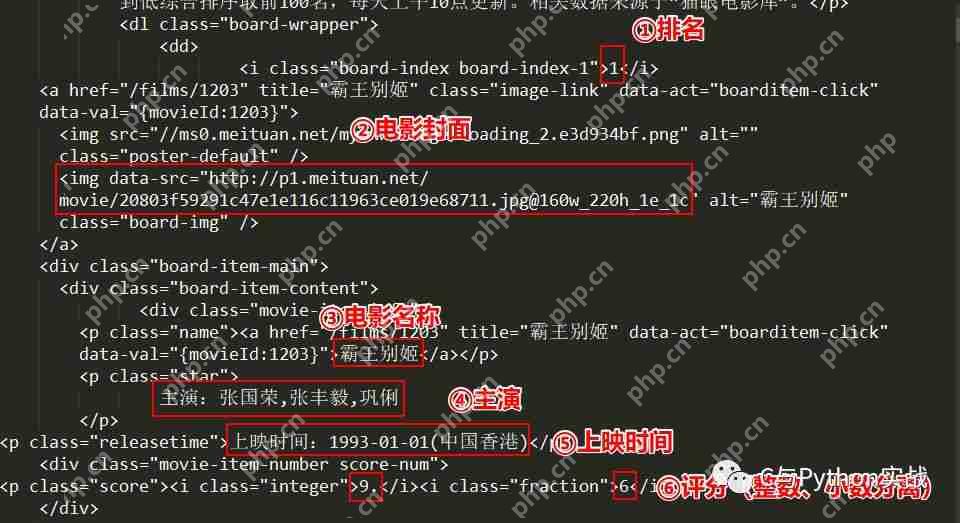
 运行结果如下:
运行结果如下:
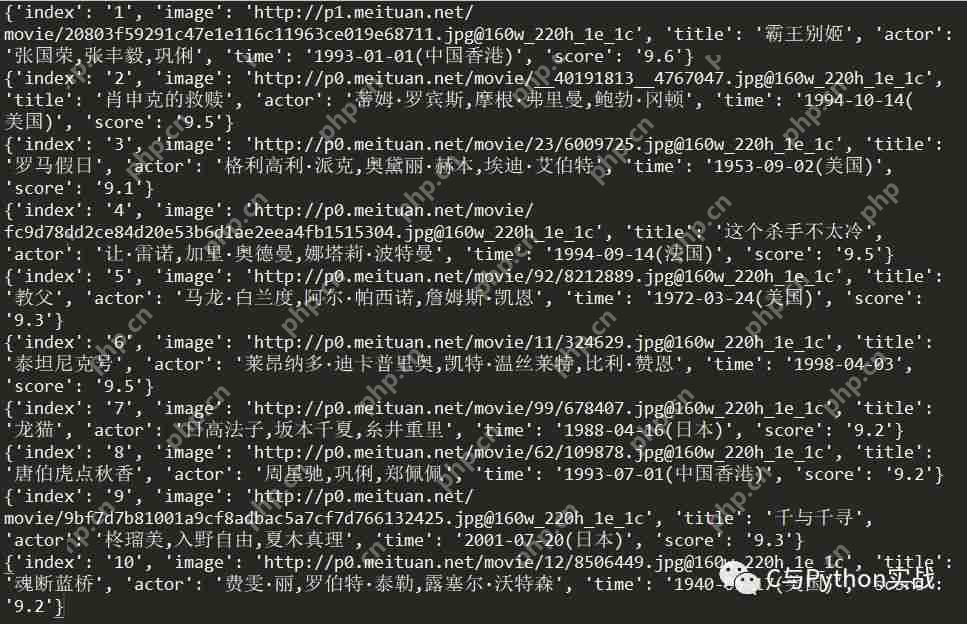
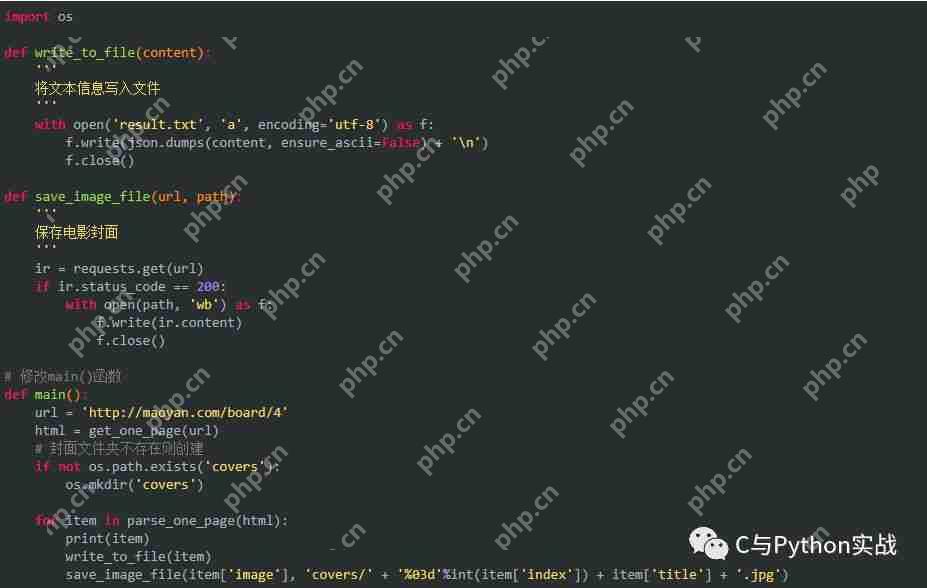 保存结果如下:
保存结果如下:

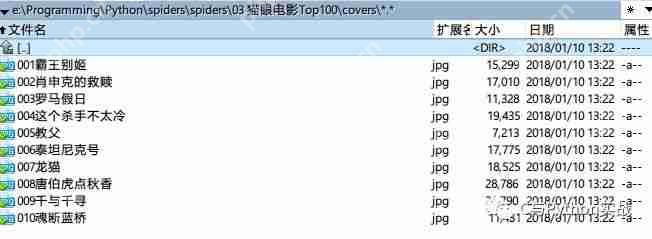
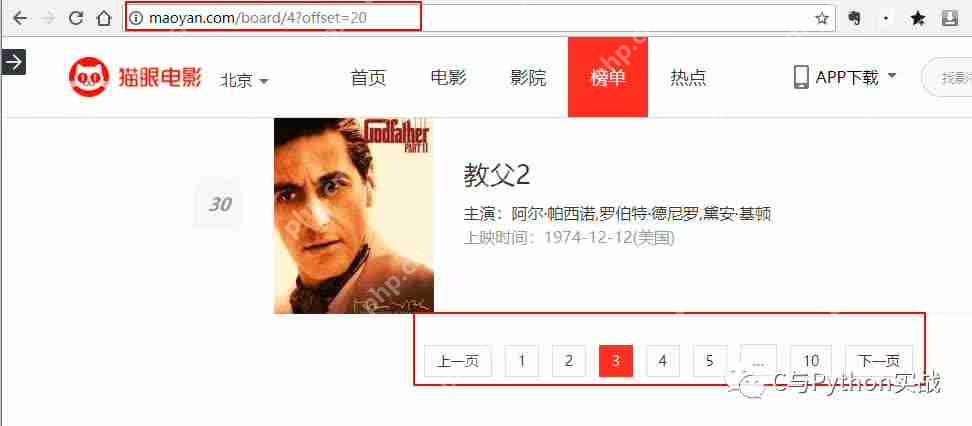 修改main函数以动态改变URL:
修改main函数以动态改变URL:
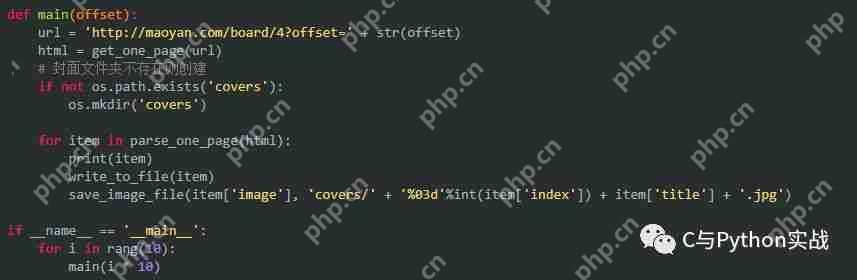 至此,我们已经成功获取了TOP100的电影信息和封面。
至此,我们已经成功获取了TOP100的电影信息和封面。
 以下是普通抓取和多进程抓取的时间对比:
以下是普通抓取和多进程抓取的时间对比:

以下是完整代码:
立即学习“Python免费学习笔记(深入)”;

以上就是Python爬虫之三:抓取猫眼电影TOP100的详细内容,更多请关注php中文网其它相关文章!

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 205
205























