
在python中使用requests库发送http请求的方法包括:1.安装requests库:pip install requests;2.发送get请求:import requests; response = requests.get('url');3.发送post请求:import requests; response = requests.post('url', data={'key': 'value'});4.发送put请求:import requests; response = requests.put('url', data={'key': 'value'});5.设置自定义头信息:import requests; response = requests.get('url', headers={'user-agent': 'custom'});6.处理认证:import requests; from requests.auth import httpbasicauth; response = requests.get('url', auth=httpbasicauth('username', 'password'));7.错误处理:使用try-except块和raise_for_status()方法;8.最佳实践:使用session对象管理连接,设置超时时间,考虑使用异步请求库如aiohttp优化性能。

在Python中使用requests库是一种高效且灵活的方式来处理HTTP请求。无论你是初学者还是经验丰富的开发者,掌握requests库都将大大提升你的网络编程能力。
让我们从头开始探讨如何使用这个强大的库。首先,确保你已经安装了requests库。你可以使用pip来安装:
pip install requests
现在,我们来看看如何用requests库发送一个简单的GET请求。这就像在浏览器中输入一个URL一样简单:
立即学习“Python免费学习笔记(深入)”;
import requests
response = requests.get('https://api.github.com')
print(response.status_code)
print(response.text)这个代码片段会向GitHub的API发送一个GET请求,并打印出状态码和返回的文本内容。你会发现,requests库的API设计得非常直观,get方法就是用来发送GET请求的。
如果你需要发送POST请求呢?requests库同样提供了简洁的解决方案:
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
response = requests.post('https://httpbin.org/post', data=payload)
print(response.text)在这个例子中,我们向httpbin.org发送了一个POST请求,并传递了一些数据。requests库会自动处理这些数据的编码和发送。
当然,requests库的功能远不止于此。它还支持其他类型的HTTP请求,如PUT、DELETE、HEAD等。让我们来看一个PUT请求的例子:
import requests
response = requests.put('https://httpbin.org/put', data={'key': 'value'})
print(response.text)使用requests库,你还可以轻松地处理各种HTTP头信息。例如,如果你需要设置一个自定义的User-Agent头,可以这样做:
import requests
headers = {'User-Agent': 'My Custom User Agent'}
response = requests.get('https://httpbin.org/headers', headers=headers)
print(response.json())这将向httpbin.org发送一个GET请求,并在请求头中包含一个自定义的User-Agent字符串。
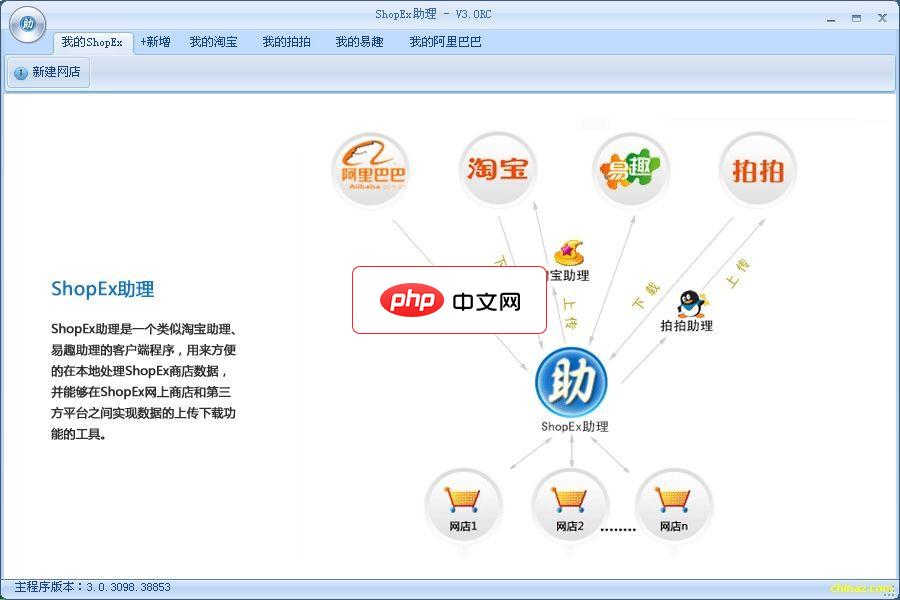
一个类似淘宝助理、ebay助理的客户端程序,用来方便的在本地处理商店数据,并能够在本地商店、网上商店和第三方平台之间实现数据上传下载功能的工具。功能说明如下:1.连接本地商店:您可以使用ShopEx助理连接一个本地安装的商店系统,这样就可以使用助理对本地商店的商品数据进行编辑等操作,并且数据也将存放在本地商店数据库中。默认是选择“本地未安装商店”,本地还未安
 0
0

在实际应用中,你可能会遇到需要处理认证的情况。requests库提供了多种认证方式,例如基本认证:
import requests
from requests.auth import HTTPBasicAuth
response = requests.get('https://api.github.com/user', auth=HTTPBasicAuth('username', 'password'))
print(response.json())这个例子展示了如何使用基本认证来访问GitHub的API。
使用requests库时,处理错误也是一个重要的话题。你可以使用try-except块来捕获可能的异常:
import requests
try:
response = requests.get('https://invalidurl.com')
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f'请求出错: {e}')这个代码片段展示了如何使用raise_for_status()方法来检查HTTP错误,并捕获任何可能的请求异常。
最后,我想分享一些使用requests库时的最佳实践和常见陷阱。首先,总是记得关闭连接,特别是在处理大量请求时:
import requests
with requests.Session() as session:
response = session.get('https://example.com')
# 使用session处理多个请求可以提高效率使用Session对象可以帮助你管理连接,提高性能。
其次,注意处理超时问题。设置合理的超时时间可以防止你的程序因为等待响应而陷入无限循环:
import requests
try:
response = requests.get('https://example.com', timeout=5)
except requests.exceptions.Timeout:
print('请求超时')最后,关于requests库的性能优化,我建议你考虑使用异步请求库如aiohttp,特别是在处理大量并发请求时。requests库虽然强大,但在高并发场景下可能不是最佳选择。
总的来说,requests库是Python中处理HTTP请求的首选工具。它的API简单易用,功能强大,能够满足大多数网络编程需求。希望这篇文章能帮助你更好地掌握requests库,并在实际项目中灵活运用。
以上就是Python中怎样使用requests库?的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 207
207






















