
在日常生活中,我们经常会遇到pdf格式的文档资料。从网络上下载的pdf文件中,有些可以正常复制内容,但有些由于经过转曲处理(文字被转换成图片形式),导致无法直接复制,或者复制后只能得到图片。对于文字较多的pdf文档,手动重新输入非常耗时。此时,我们需要借助识别工具来解决问题。以下将详细介绍汉王pdf ocr的具体使用方法。
1、首先,启动已安装的汉王PDF OCR软件,如图所示。

2、依次点击文件菜单中的图像选项(或使用快捷键Ctrl+O),操作如图所示。

3、在弹出的打开图像文件窗口中,直接选择PDF文件,此时下方的pdf转换为TXT文件选项会从灰色变为可用的黑色。点击此选项即可导出txt文件。请注意,此方法适用于高质量的PDF文件,若文件质量较差,直接使用可能会导致较高的识别误差。


4、如果PDF文件质量较差,直接选中文件后点击打开,按照下图操作:

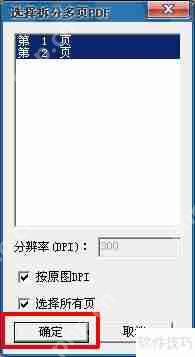
5、若PDF为多页,会弹出选择拆分多页PDF的窗口,选取需要复制文字的页码(也可以全选),点击确定。
Flash ActionScript3 高级教程 pdf,书籍部分目录: 第一章 高级 碰撞检测 不规则图形的检测碰撞 BitmapData.hitTest用于非位图 大量对象的碰撞检测 实现基于网格的碰撞检测 编写网格代码 测试并调整网格 使用此类 检测不只是为了碰撞 第二章 转向 行为 2D向量(Vector2D)类 机车(Vehicle)类 转向机车(SteeredVehicle)类 寻找行为 避开行为 到达行为
 0
0

6、打开后,文件栏会显示该文件,下方框内呈现PDF页面详情,如图所示。

7、选中需要转换的PDF文件页(或全选),点击工具栏中的识别选项,然后选择开始识别(或按F8)。

8、当前,界面上方会显示正在识别的提示,识别结束后,结果将显示在相同位置。如果PDF文件的清晰度不足,可能会出现部分错误,可以手动进行修改,如图所示:

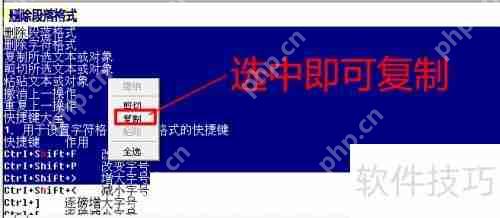
9、在界面顶部的识别结果框中,选中所需文字,右击鼠标选择复制,即可粘贴使用,如图所示。
以上就是汉王PDF OCR使用教程的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 773
773






















