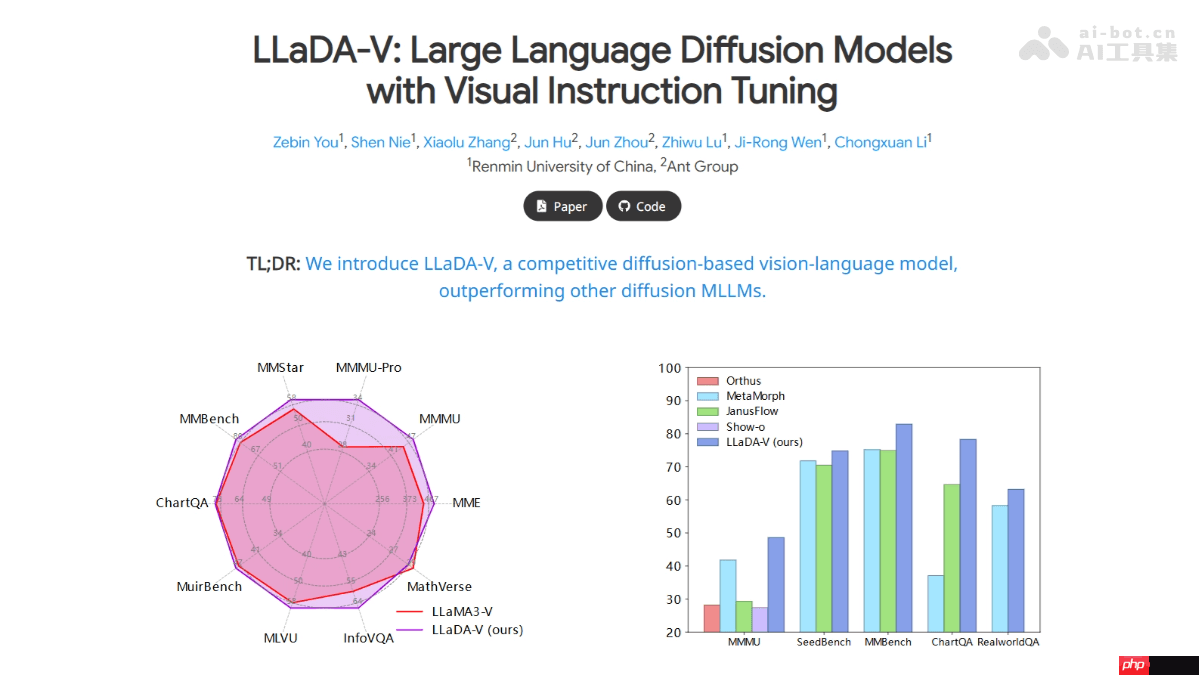
llada-v 是由中国人民大学高瓴人工智能学院与蚂蚁集团联合推出的一款多模态大语言模型(mllm),其架构完全基于纯扩散模型,并特别针对视觉指令进行了微调优化。该模型是在llada的基础上扩展而来,新增了视觉编码器以及mlp连接器,通过将视觉信息映射至语言嵌入空间,实现了高效的多模态对齐。llada-v 在多模态理解领域达到了当前的技术前沿,其性能超过了现有的混合自回归-扩散及纯扩散模型。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
LLaDA-V 的核心功能
-
图像描述生成:能够依据输入的图像生成详尽的描述文字。
-
视觉问答:针对图像中的内容提出并解答相关问题。
-
多轮多模态交互:在包含图像的情境下开展多轮对话,确保生成的回答既与图像相符又与对话历史保持连贯。
-
复杂推理任务:处理结合图像和文本的高级推理任务,比如解答基于图像的数学题或逻辑难题。
LLaDA-V 的技术基础
-
扩散模型(Diffusion Models):扩散模型通过逐步去除噪声来生成数据。LLaDA-V 利用了掩码扩散模型(Masked Diffusion Models),即在句子内随机遮蔽某些词汇(用特殊标记[M]代替),然后训练模型去预测这些被遮蔽词汇的原始内容。
-
视觉指令微调(Visual Instruction Tuning):此方法依赖于视觉指令微调框架,其中包括视觉塔(Vision Tower)和MLP连接器(MLP Connector)。视觉塔采用SigLIP 2模型将图像转化为视觉表征,而MLP连接器则负责将这些视觉表征映射到语言模型的词嵌入空间,从而实现视觉与语言特征的有效对齐与融合。
-
多阶段训练流程:首先,训练MLP连接器以确保视觉表征与语言嵌入之间的良好对齐;接着,在第二阶段对整体模型进行微调,使其具备理解和执行视觉指令的能力;最后,通过进一步强化训练提升模型的多模态推理水平,使其胜任更复杂的多模态推理任务。
-
双向注意力机制:在多轮对话过程中,LLaDA-V 运用双向注意力机制,使模型在预测遮蔽词汇时可以参考整个对话背景,这有助于提高模型对于对话整体逻辑与内容的理解能力。
LLaDA-V 的资源链接
LLaDA-V 的潜在应用
-
图像描述生成:自动创建图像的详细说明,便于用户理解图像含义。
-
视觉问答:回应与图像有关的问题,适合应用于教育、旅行等多个行业。
-
多轮对话:用于智能客服、虚拟助手等场景下的多轮多模态交流。
-
复杂推理:应对涉及图像和文本的复杂推理挑战,如数学问题求解。
-
多图像与视频解析:分析多幅图像或视频内容,可用于视频监控及其他监测应用场景。
以上就是LLaDA-V— 人大高瓴AI联合蚂蚁推出的多模态大模型的详细内容,更多请关注php中文网其它相关文章!



 广告
广告







 734
734






















