

Hadoop的MapReduce任务执行流程可以概括为以下主要环节:
借助上述步骤,Hadoop的MapReduce能够有效地处理和分析大量数据。
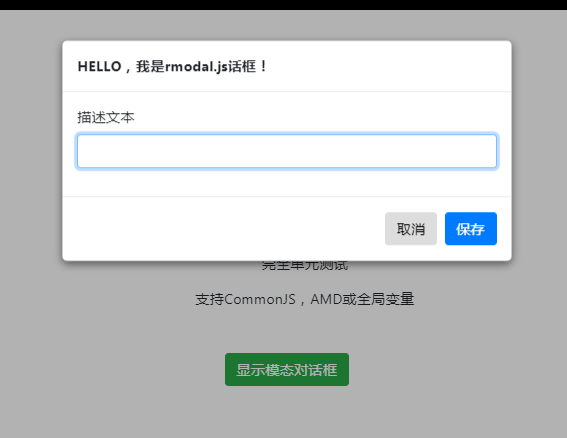
rmodal.js是一款带动画效果的js模态对话框插件。rmodal.js模态对话框插件压缩版本仅1.2kb,没有任何外部依赖,可以制作出带动画特效的模态对话框效果。它的特点还有: 使用简单,执行效率高。 纯js编写,没有任何外部依赖。 支持包括IE9+的所有现代浏览器。 可以和bootstrap和animate.css结合使用。 支持CommonJS AMD 或 globals。
 36
36

以上就是Hadoop的MapReduce任务是如何执行的的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 451
451
























