
前言:在当今这个数字化迅猛发展的时代,互联网已经成为连接全球信息与服务的桥梁。而在这浩瀚的网络海洋中,http(超文本传输协议)作为互联网上应用最广泛的一种协议,扮演着举足轻重的角色。无论是我们日常浏览的网页、观看的在线视频、还是进行的电子商务交易,背后都离不开http协议的默默支撑。
我们将从HTTP协议的历史沿革讲起,逐步深入到协议的报文结构、状态码含义、请求方法分类,先初步了解HTTP的大概,然后手动封装一个HTTP协议来加深对知识的理解,掌握HTTP协议的基础知识不仅是通往更高层次技术领域的必经之路。
让我们携手启程,探索HTTP协议在Linux网络世界中的无限可能!
?序列化和反序列化(JSON)序列化:
JSON序列化是指将数据结构或对象转换为JSON格式字符串的过程。这个字符串可以方便地存储到文件、数据库,或通过网络传输。我们在C++编程中想要使用JSON是需要链接外部库的,我们在编译时,需要加上-ljsoncpp
JSON序列化示例:
代码语言:javascript代码运行次数:0运行复制#include <iostream>#include <jsoncpp/json/json.h> //JSONint main(){ // Json::Value --- 万能类型 Json::Value root; root["k1"] = 100; root["k2"] = 200; root["k3"] = 300; root["k4"] = 400; root["k5"] = 500; Json::FastWriter writer; std::string s = writer.write(root); std::cout << s << std::endl; return 0;}反序列化:
JSON反序列化是指将JSON格式字符串转换回数据结构或对象的过程。这个过程是序列化的逆过程,它允许从存储或传输的JSON字符串中恢复出原本的数据结构或对象。
JSON反序列化示例:(伪代码)
代码语言:javascript代码运行次数:0运行复制#include <iostream>#include <jsoncpp/json/json.h> //JSONint main(){Json::Value root; Json::Reader reader; int x, y, z; bool res = reader.parse(in, root);if(res) {x = root["k1"].asInt(); y = root["k2"].asInt(); z = root["k3"].asInt(); }return 0;}HTTP(HyperText Transfer Protocol,超文本传输协议)是一种应用层协议,用于在Web服务器和客户端之间传输超文本(如HTML文档)和其他内容。它是构成现代Web的核心协议之一,为浏览器和服务器之间的通信提供了一种标准化的方式。
HTTP的基本工作原理:
HTTP协议基于请求-响应模型工作。当用户在浏览器中输入一个网址或点击一个链接时,浏览器会向服务器发送一个HTTP请求。服务器接收到请求后,处理该请求并返回相应的HTTP响应,其中包含了所需的资源(如HTML文档、图像、视频等)或状态信息。?认识URLURL可以看作是互联网世界中的地址,就像在现实生活中通过门牌号找到房子一样,通过URL,用户可以在互联网上找到特定的网页、文件、图像、视频等各种资源。

URL是互联网上资源位置的重要标识符,它允许用户准确地找到所需的资源,并方便地与他人共享这些资源。
urlencode和urldecode:
UrlEncode(URL编码)和UrlDecode(URL解码)是一对相反的操作,它们主要用于处理URL中的特殊字符。
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
urlencode和urldecode是一对相互配合的操作。urlencode用于编码URL中的特殊字符,而UrlDecodeurldecode用于解码已经被编码的URL。
?HTTP协议格式HTTP请求
首行: [方法] + [url] + [版本]Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度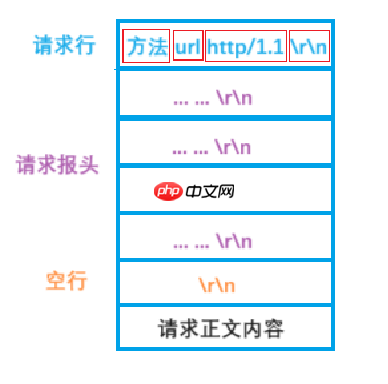

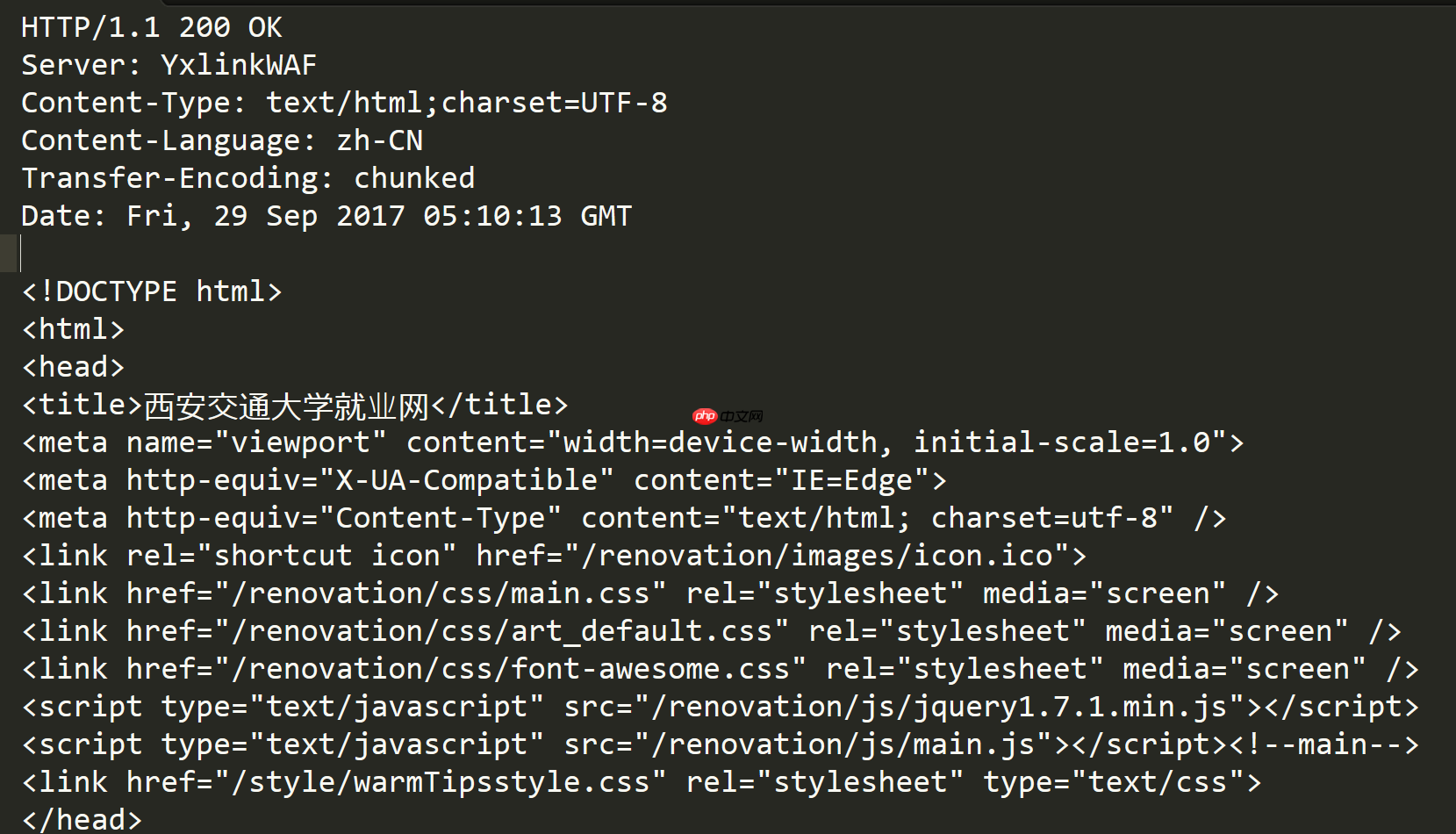
HTTP响应
首行: [版本号] + [状态码] + [状态码解释]Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中
HTTP(Hypertext Transfer Protocol,超文本传输协议)的方法,也称为“动作”或“命令”,是客户端(如浏览器)向服务器发送请求以执行特定操作的方式。以下是HTTP的主要方法:
方法
说明
支持的HTTP协议版本
GET
获取资源
1.0,1.1
POST
传输实体主体
1.0,1.1
PUT
传输文件
1.0,1.1
HEAD
获得报文首部
1.0,1.1
DELETE
删除文件
1.0,1.1
OPTIONS
询问支持的方法
1.1
TRACE
追踪路径
1.1
CONNECT

威博仿淘宝多用商城程序于4月底发布公测以来,得到了广大用户的关注和支持,陆续有很多意见和建议反馈到威博网络技术部。广泛的关注与支持,也是威博仿淘宝多用商城程序不断进步的一个重要原因。威博网络有这么多忠实的支持者才会有今天的成绩。经过一个多月的在线测试,威博仿淘宝多用商城程序有望于6月底正式对外发布销售!这套购物网站源代码/购物网站系统免费下载--威博网络是在多用户网上商城系统的基础上,全面整合仿淘
 0
0

要求用隧道协议连接代理
1.1
LINK
建立和资源间的联系
1.0
UNLINK
断开连接关系
1.0
虽然关于HTTP的方法有这么多种,但是我们最最常用的方法还是GET和POST方法,这两种方法足够我们使用了,它们不仅获取服务器上的资源,还可以将自己的资源传输到服务器
GET 用于请求指定的页面信息,并返回实体主体。 通常用于请求数据,而不是提交数据。请求的数据会附加在URL之后(即查询字符串)。
代码语言:javascript代码运行次数:0运行复制<form action="/dira/dirb/pxt.html" method="get">
当我们使用GET方法时,当我们输入账号和密码请求内容时,我们的网址会加上参数,从而传给服务器,带参的GET方法通过URL将参数传递给服务器,会将参数回显出来
代码语言:javascript代码运行次数:0运行复制http://121.37.255.241:8888/dira/dirb/pxt.html?myname=aaaa&mypasswd=123456
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据包含在请求体中。 POST请求可能会导致新的资源的创建或现有资源的修改。
代码语言:javascript代码运行次数:0运行复制<form action="/dira/dirb/pxt.html" method="post">
当我们使用POST方法时,我们在上传数据时,我们需要使用到参数,但是参数并不会直接通过url直接回显出来,而是存放在了请求行中
http://121.37.255.241:8888/dira/dirb/pxt.html
-
类别
原因短语
1XX
Informational(信息性状态码)
接受的请求正在处理
2XX
Success(成功状态码)
请求正常处理完毕
3XX
Redirection(重定向状态码)
需要进行附加操作以完成请求
4XX
Client Error(客户端错误状态码)
服务器无法处理请求
5XX
Server Error(服务器错误状态码)
服务器无法处理出错
最常见的状态码: 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
⭐HTTP常见HeaderContent-Type: 数据类型(text/html等)Content-Length: Body的长度Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上User-Agent: 声明用户的操作系统和浏览器版本信息referer: 当前页面是从哪个页面跳转过来的location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能Cookie:
不知道大家有没有注意过,我们在使用CSDN,除了第一次要登陆账号以外,后面每一次,都是自动登录账号,有这一层便利,还得多亏了Cookie,当我们在第一次登陆账号后,Cookie中就会保存我们的账号信息,然后当我们再次登录时,他会直接读取保存好的账号的信息,完成自动登录
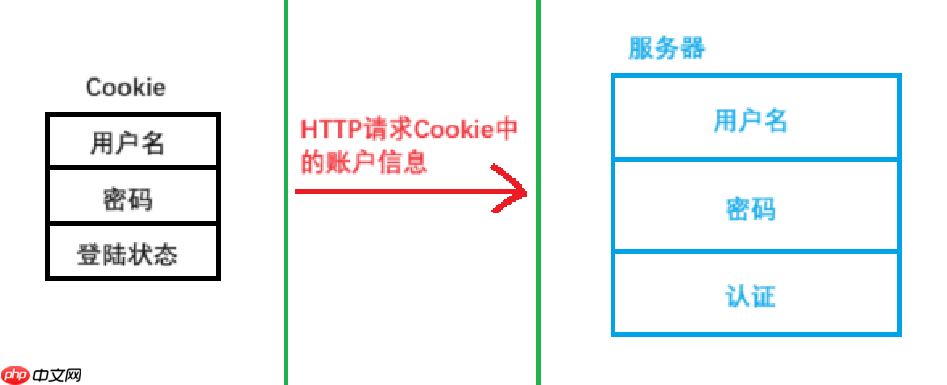
Cookie的类型:
会话Cookie: 仅在用户浏览网站期间存在,关闭浏览器后即会自动删除。持续性Cookie: 会在用户设备上存储一定期限,即使关闭浏览器也不会删除,除非用户手动清除。Session:
工作原理:
当客户端(如浏览器)首次请求服务器时,服务器会创建一个Session,并生成一个唯一的Session ID服务器将这个Session ID发送给客户端,通常是以Cookie的形式。客户端将这个Session ID存储在本地,以便后续请求时携带之后,每当客户端与服务器进行交互时,都会将这个Session ID包含在请求中。服务器通过Session ID找到对应的Session,从而识别出请求来自哪个客户端这里我们简单了解个大概就可以了,感兴趣的童鞋可以去深入了解一下,我这里就不过多展开了,最后我简单的实现了一下HTTP的封装,感兴趣的童鞋也可以去Gitee上面查看
Gitee:HTTP封装
?总结在探索Linux网络基础与HTTP协议的旅途中,我们不仅解锁了互联网通信的密钥,还深刻理解了这一技术基石如何支撑起现代数字世界的万维网,学习的每一步都揭示出网络通讯的复杂性与优雅。
正如HTTP协议本身,它虽简单却强大,能够适应并驱动着互联网的不断变革。在这个快速变化的时代,持续学习、勇于探索未知,是我们作为技术人的不变使命。让我们带着这份对技术的热爱与敬畏,继续在Linux网络世界的广阔天地中遨游,用代码编织更加智能、安全的网络未来。
以上就是【Linux网络】网络基础:HTTP协议的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 838
838

























