
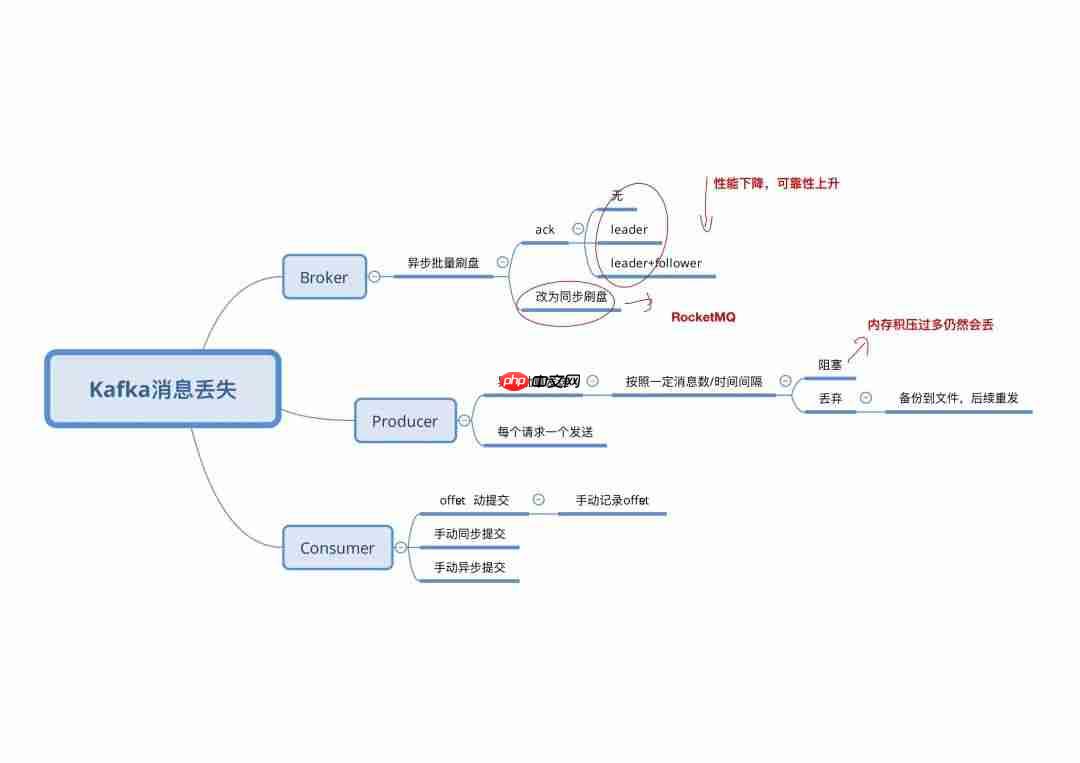
broker丢失消息是由于kafka本身的原因造成的,kafka为了得到更高的性能和吞吐量,将数据异步批量的存储在磁盘中。消息的刷盘过程,为了提高性能,减少刷盘次数,kafka采用了批量刷盘的做法。即,按照一定的消息量,和时间间隔进行刷盘。这种机制也是由于linux操作系统决定的。将数据存储到linux操作系统种,会先存储到页缓存(page cache)中,按照时间或者其他条件进行刷盘(从page cache到file),或者通过fsync命令强制刷盘。数据在page cache中时,如果系统挂掉,数据会丢失。
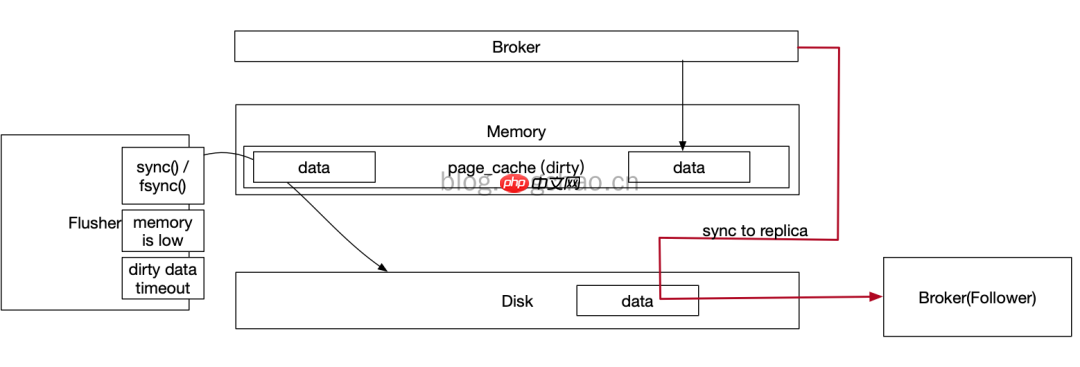
Broker在linux服务器上高速读写以及同步到Replica
上图简述了broker写数据以及同步的一个过程。broker写数据只写到PageCache中,而pageCache位于内存。这部分数据在断电后是会丢失的。pageCache的数据通过linux的flusher程序进行刷盘。刷盘触发条件有三:
主动调用sync或fsync函数可用内存低于阀值dirty data时间达到阀值。dirty是pagecache的一个标识位,当有数据写入到pageCache时,pagecache被标注为dirty,数据刷盘以后,dirty标志清除。Broker配置刷盘机制,是通过调用fsync函数接管了刷盘动作。从单个Broker来看,pageCache的数据会丢失。
Kafka没有提供同步刷盘的方式。同步刷盘在RocketMQ中有实现,实现原理是将异步刷盘的流程进行阻塞,等待响应,类似ajax的callback或者是java的future。下面是一段rocketmq的源码。
代码语言:javascript代码运行次数:0运行复制GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes());service.putRequest(request);boolean flushOK = request.waitForFlush(this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout()); // 刷盘
也就是说,理论上,要完全让kafka保证单个broker不丢失消息是做不到的,只能通过调整刷盘机制的参数缓解该情况。比如,减少刷盘间隔,减少刷盘数据量大小。时间越短,性能越差,可靠性越好(尽可能可靠)。这是一个选择题。
为了解决该问题,kafka通过producer和broker协同处理单个broker丢失参数的情况。一旦producer发现broker消息丢失,即可自动进行retry。除非retry次数超过阀值(可配置),消息才会丢失。此时需要生产者客户端手动处理该情况。那么producer是如何检测到数据丢失的呢?是通过ack机制,类似于http的三次握手的方式。
以上就是Kafka丢消息?必看的高频面试题!的详细内容,更多请关注php中文网其它相关文章!

Kafka Eagle是一款结合了目前大数据Kafka监控工具的特点,重新研发的一块开源免费的Kafka集群优秀的监控工具。它可以非常方便的监控生产环境中的offset、lag变化、partition分布、owner等,有需要的小伙伴快来保存下载体验吧!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 419
419





















