







worldvla是由阿里巴巴达摩院与浙江大学联合开发的一种自回归动作世界模型。该模型将视觉-语言-动作(vla)模型与世界模型融合于同一框架中,通过图像和动作的预测来理解环境的基本物理规律,从而提升动作生成的质量。动作模型根据图像观察生成后续动作,辅助视觉理解,并反过来增强世界模型的视觉生成能力。worldvla在性能上优于单独的动作模型或世界模型,体现了二者之间的相互增强效果。为了解决自回归方式生成连续动作时可能出现的性能下降问题,模型引入了一种注意力掩码策略,在生成当前动作时选择性地屏蔽之前动作的影响,显著提升了动作块生成的效果。

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
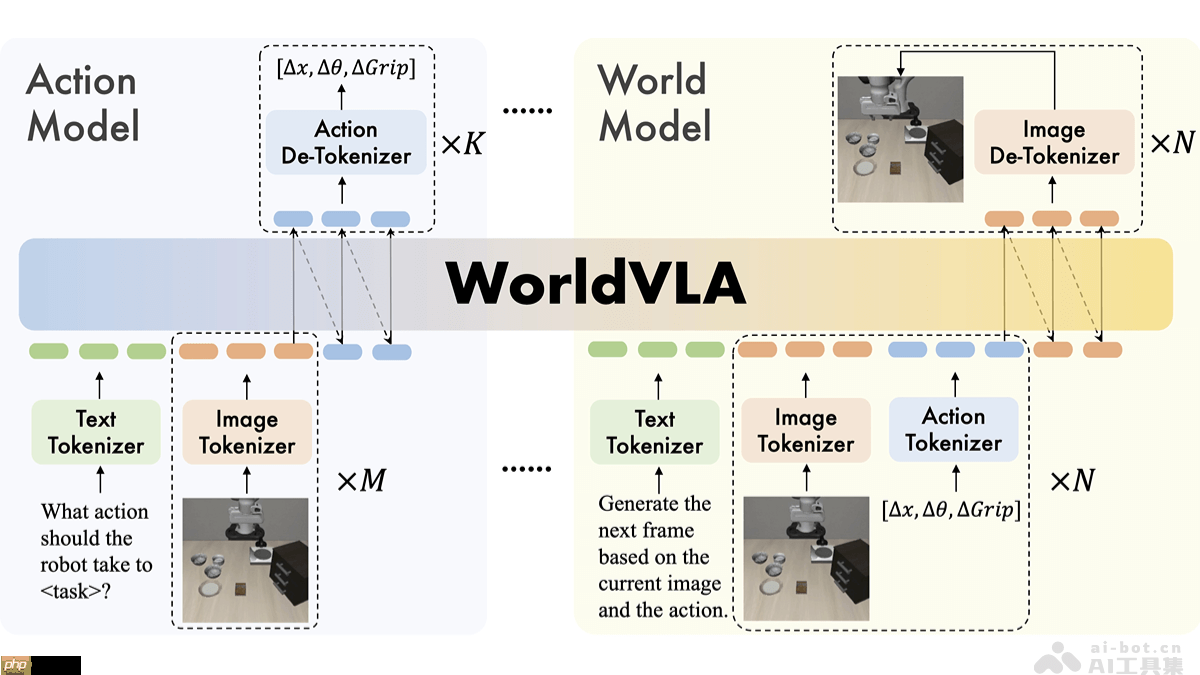 WorldVLA的核心功能
WorldVLA的核心功能
- 动作规划:依据图像和语言指令生成相应的后续动作,支持连续动作的生成。
- 图像状态预测:基于当前图像和执行的动作预测未来的图像状态,提高视觉预测的准确性。
- 环境建模能力:通过学习环境中的物理规律,增强对视觉信息和动作的理解。
- 双向协同机制:动作模型与世界模型之间形成互动增强关系,整体提升系统表现。
WorldVLA的技术实现
- 统一架构设计:WorldVLA整合了视觉-语言-动作(VLA)模型与世界模型,使用三个独立编码器(图像、文本与动作编码器)将多模态数据转换为统一词汇表中的标记,实现跨模态处理。
- 自回归建模方式:采用自回归机制进行动作与图像的生成。动作模型根据历史图像和语言输入生成动作序列,世界模型则依据历史图像和动作预测未来图像状态。
- 注意力掩码机制:针对自回归模型在长序列生成中可能出现的性能衰退问题,提出一种注意力掩码策略,在生成当前动作时有选择地忽略先前动作的影响,降低误差传播,提升动作块生成质量。
- 双向增强机制:模型利用世界模型与动作模型之间的反馈关系实现互惠增强。世界模型通过预测未来状态帮助动作模型理解环境动态,而动作模型生成的动作又能反哺世界模型,提升其图像预测精度。
- 混合训练方法:在训练过程中同时使用动作模型与世界模型的数据,使模型能够在统一结构下掌握多种能力,如动作生成与图像预测。
WorldVLA的项目资源
- GitHub仓库:https://www.php.cn/link/a0164cbfe882aa11e433a6b503cb62db
- HuggingFace模型页面:https://www.php.cn/link/2af209a360a2217e0838147bc405aeff
- 技术论文链接:https://www.php.cn/link/210bcb6b2b91bc12683f9f87e7c45d6c
WorldVLA的典型应用
- 机器人任务执行:协助机器人根据视觉与语言指令完成目标导向操作,例如物体搬运等。
- 复杂环境下的精细控制:在杂乱或受限环境中生成适应性强的动作,完成高精度操作。
- 人机协作场景:理解人类行为意图,生成匹配的协作动作,提升合作效率。
- 未来状态模拟:预测未来图像状态,辅助机器人提前评估动作后果,如用于自动驾驶的道路场景预判。
- 教育与科研平台:作为教学与研究工具,促进学生和研究人员深入理解机器人控制与视觉预测技术。




























