
全民k歌:歌房舞台效果开启指南
腾讯出品的全民K歌,以其智能打分、修音、混音和专业音效等功能,深受K歌爱好者喜爱。本教程将详细指导您如何在全民K歌歌房中开启炫酷的舞台效果。

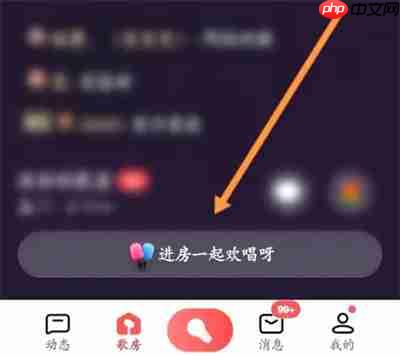
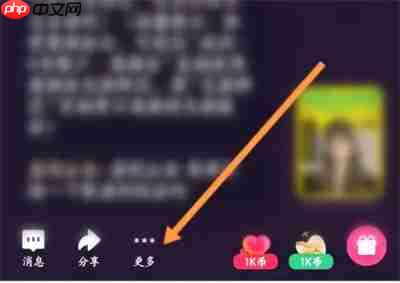
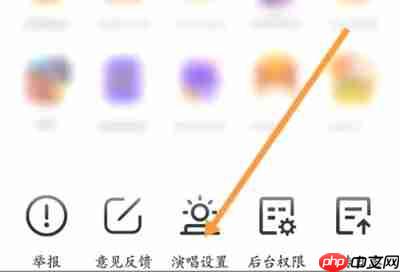
步骤:

立即学习“Java免费学习笔记(深入)”;
微信小程序公众号SaaS管理系统是一款完全开源的微信第三方管理系统,为中小企业提供最佳的小程序集中管理解决方案。可实现小程序的快速免审核注册(免300元审核费),可批量发布小程序模板,同步升级版本等功能。基础版本提供商城和扫码点餐两种小程序模板。商户端可以实现小程序页面模块化设计和自动生成小程序源代码并直接发布。
 0
0

以上就是Java注解处理器的代码生成案例的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 657
657
























