
在单细胞rna测序中,细胞数量过多会导致双细胞比例的增加,但实际情况往往是其他指标表现不佳。例如:
尽管如此,许多研究者仍然倾向于测序更多的细胞,约1万个细胞左右通常是可以接受的。但如果实验环节出现问题,测序2万个或更多的单细胞可能会带来麻烦。
在《Single-Cell RNA Sequencing of Peripheral Blood Mononuclear Cells From Pediatric Coeliac Disease Patients Suggests Potential Pre-Seroconversion Markers》这篇文章中,单个样品测序了近2万个单细胞,总共分析了19,663个单细胞。然而,通过严格的质量控制步骤,过滤后剩余的细胞数不到1万个,这是一个不错的结果。具体的过滤参数并不严苛,主要是确保每个细胞至少检测到200个基因,这是单细胞转录组数据处理中的常规设置(min.features = 200)。以下是相关代码:
library(Seurat) # https://cf.10xgenomics.com/samples/cell/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz ## Load the PBMC dataset pbmc.data
通过这样的过滤,可以看到作者的策略是有效的。下图展示了过滤前后的效果:
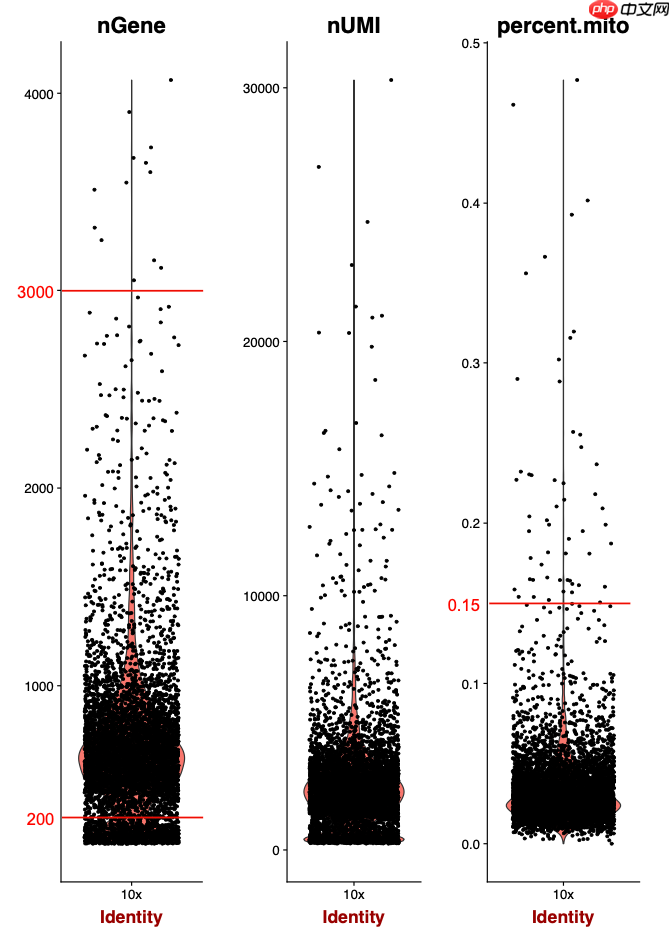
对于这篇文章的附件中提供的表达量矩阵,尽管质量略有瑕疵,但进行降维聚类分群和生物学命名时问题不大:
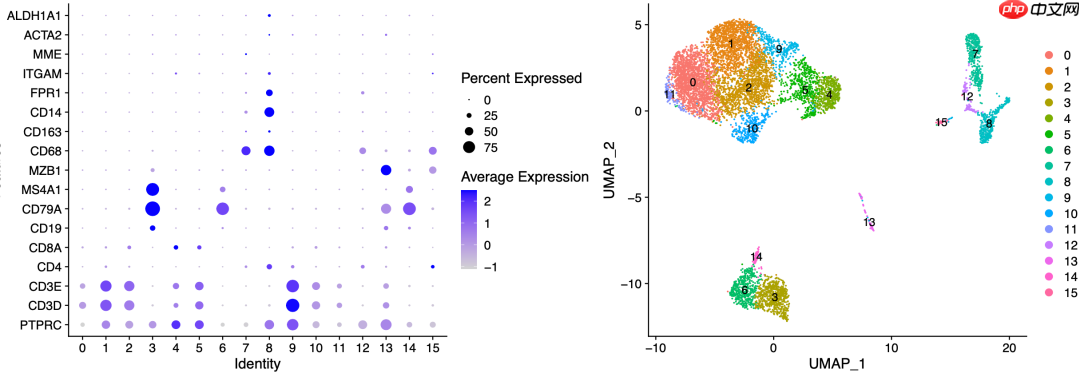
从降维聚类分群图中可以清楚地看到不同免疫细胞的分群。以下是用于定义细胞亚群的代码:
#定义细胞亚群 celltype[celltype$ClusterID %in% c(7,8,12,15),2]='Myeloids' celltype[celltype$ClusterID %in% c(0,1,2,9,10,11),2]='CD4' celltype[celltype$ClusterID %in% c(4,5),2]='CD8' celltype[celltype$ClusterID %in% c(3,6,14),2]='Bcells' celltype[celltype$ClusterID %in% c(13),2]='plasma'
大部分文章都会进一步细分免疫细胞亚群,包括淋巴系(T、B、NK细胞)和髓系(单核、树突、巨噬、粒细胞)两大类。文章通常选择进行大量的差异分析和注释来讲述故事。基础的单细胞转录组数据处理步骤包括:
最基础的步骤往往是降维聚类分群,参考前面的例子,可以帮助大家掌握单细胞聚类分群注解的基本方法。
以上就是单个样品测序了近2万个单细胞怎么办的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 214
214





















