
线上 node.js 业务流量异常增长问题定位
问题现象
某天,通过我们自建的监控系统,发现部门下属所有业务的 notFound 页面性能上报量出现了显著的异常增长,进而影响了单一页面以及整体性能指标。
问题分析
面对流量突然激增的情况,我们从两个角度进行分析:业务自身的正常增长和来自爬虫的异常增长。
从正常增长的角度来看:
增长的流量全部来自于没有实际内容的 notFound 页面。与业务方沟通后,无法找到合法的流量来源,这些流量不带 referrer 以及合法用户的 cookie。通过以上三点,我们基本可以确定异常流量来源于爬虫。
定位爬虫
要解决爬虫问题,首先需要定位爬虫的特征,比如相同的 UA、相似的 IP段等。
我们在服务端日志中进行分析,发现 IP 和 UA 特征并不明显。这是由于业务特性导致的。我们业务的 notFound 页面一直承担部分爬虫流量的职责,因此整体服务调用量一直较高。在大量服务日志中,爬虫的部分 IP 并不特别显眼。
我们换个角度,从前端性能日志进行分析。虽然 notFound 页面服务调用量较高,但由于大部分请求都是直接爬取页面,没有在浏览器中进行渲染,所以前端性能上报量一直比较稳定,可以作为突破口。
在分析前端性能日志时,我们借助了集团内部共建的 TAM 平台的多维度分析视图来进一步定位。
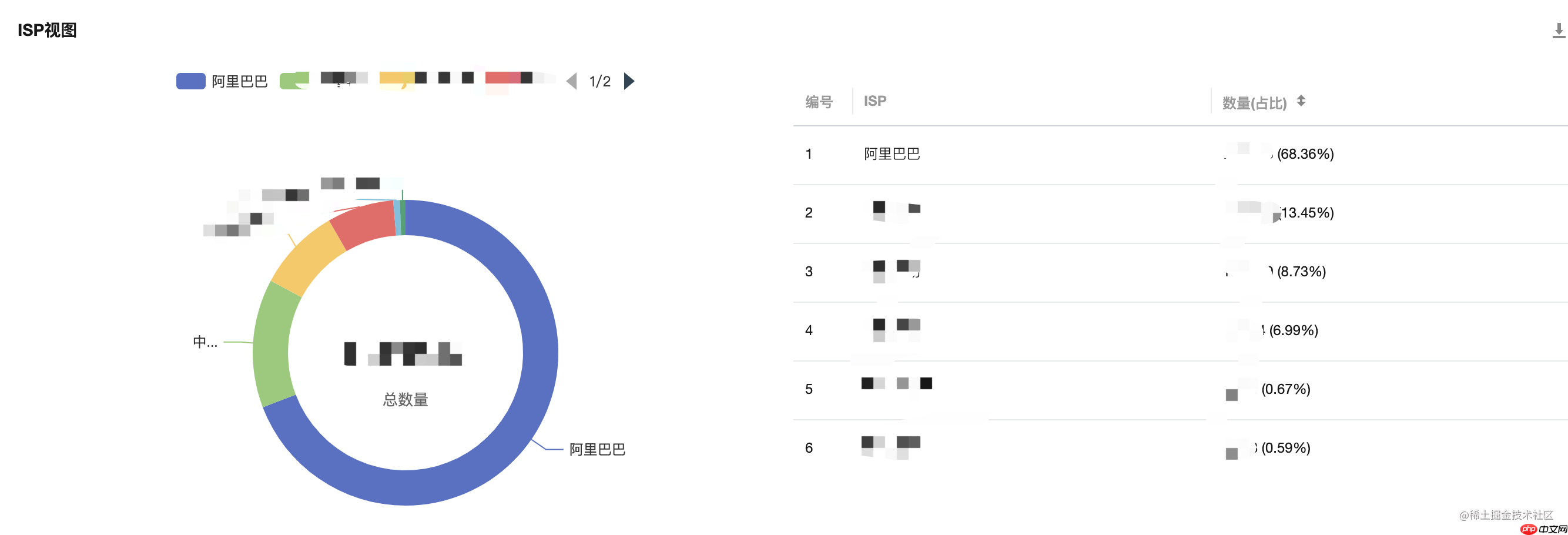 如图所示,在 ISP 分析视图中,来自阿里巴巴的流量占比接近70%,这是一个非常明显的异常聚集。
如图所示,在 ISP 分析视图中,来自阿里巴巴的流量占比接近70%,这是一个非常明显的异常聚集。
根据这一特征,我们在前端性能上报的原始日志中进行过滤,发现阿里巴巴的请求 IP 都在一个网段中,再使用 awk 拆解日志进行聚合分析,来自阿里巴巴的网段在头部呈现聚集态势,如图:

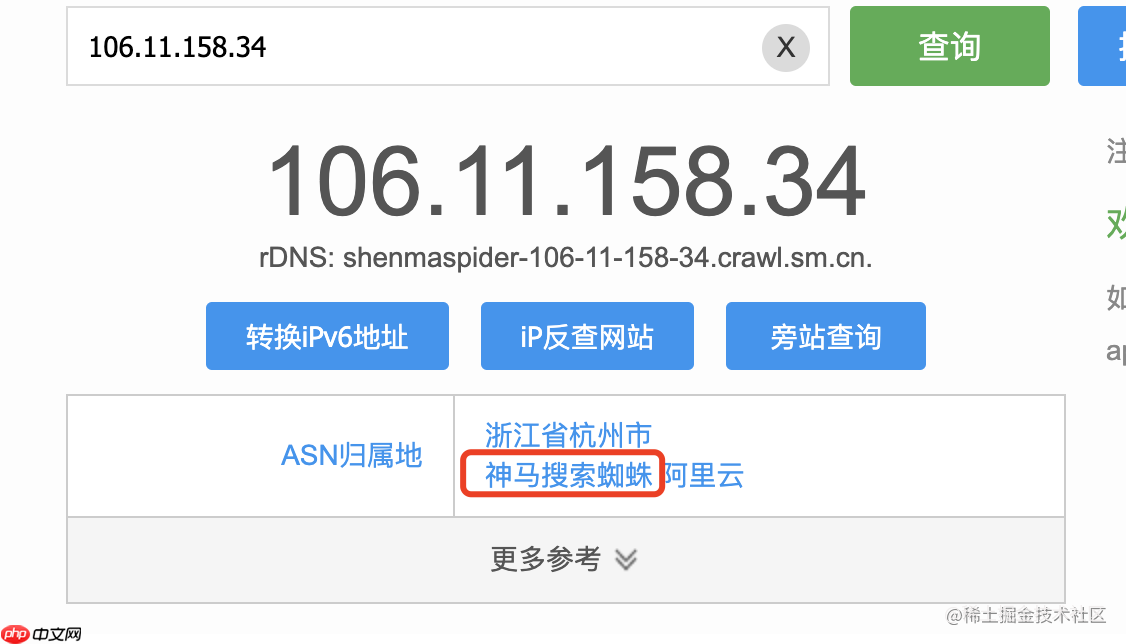 现在我们可以得出结论:异常增长的流量来自于阿里巴巴神马搜索的爬虫。
现在我们可以得出结论:异常增长的流量来自于阿里巴巴神马搜索的爬虫。
问题解决
能够定位到爬虫的特征,我们就可以根据具体的特征施加不同维度的封禁手段。
问题总结
通过本次异常流量问题的定位和解决,我们应该学会:
通过 UA、IP段、运营商等多个维度来定位爬虫特征,并学会借助平台功能熟悉整个服务端请求链条,遇到问题应该从整个链条逐步细化定位环节。前端性能日志与服务端日志结合分析能更快地定位问题。熟练使用 awk / sort / uniq 等 Linux 文本分析工具。
以上就是一次线上 Node.js 业务流量异常增长问题定位过程的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号







 641
641





















