
graphembedding实战系列:node2vec原理与代码实战
论文:《node2vec: Scalable Feature Learning for Networks》
基本介绍:node2vec是一种半监督算法,用于网络中的可扩展特征学习。它通过SGD优化一个定制的基于图的目标函数。这种方法返回特征表示,针对d维空间中的节点,最大化其网络邻节点的似然。
node2vec的关键贡献在于为顶点的网络邻节点定义了一个灵活的概念。通过选择合适的概念,node2vec可以学习到基于网络角色或社群的网络表示。论文通过开发一种有偏的随机游走族谱,有效探索给定顶点的邻居分布。结果算法非常灵活,提供可调参数来控制搜索空间,而不是进行严格搜索。因此,论文的方法可以建模网络等价物。这些参数管理着搜索策略,具有直观解释,使walk偏向不同的网络搜索策略。在半监督学习中,这些参数仅使用少量带标注数据即可直接学习。
我们也展示了如何将单个节点的特征表示扩展到节点对(比如:边)。为了生成边的特征表示,我们将学到的特征表示与简单的二元操作相结合。这种组合性将node2vec引入到关于节点(或边)的预测任务上。
该论文的主要贡献包括:
特征学习框架 为了使最优化可处理,论文做出了两个标准假设:
为了使最优化可处理,论文做出了两个标准假设:
条件独立性。我们通过假设:给定源节点的特征表示,观察到一个邻节点的似然,与观察到其他邻节点是独立的: 特征空间的对称性。一个源节点和它的邻节点在特征空间中具有对称性的相互影响。因此,我们建模每个(源节点-邻节点)对的条件似然为一个softmax单元,由它们的特征点积参数化:
特征空间的对称性。一个源节点和它的邻节点在特征空间中具有对称性的相互影响。因此,我们建模每个(源节点-邻节点)对的条件似然为一个softmax单元,由它们的特征点积参数化: 有了以上假设,等式一的目标可以简化为:
有了以上假设,等式一的目标可以简化为:
 每个节点的分区函数:
每个节点的分区函数:
 ,对于大网络来说计算开销很大,可以使用负采样来进行近似。
,对于大网络来说计算开销很大,可以使用负采样来进行近似。
基于skip-gram的特征学习方法,最早源自于NLP上下文学习。文本本身是线性的,一个邻词可以很自然地使用一个在连续词汇上的滑动窗口进行定义。而对于网络,是非线性的,因此需要更丰富。为了解决这一点,论文提出了一种随机过程,它会对给定源节点u抽样许多不同的邻节点。
 不局限于它的立即邻节点,具体取决于抽样策略S,有不同的结构。
不局限于它的立即邻节点,具体取决于抽样策略S,有不同的结构。
经典搜索策略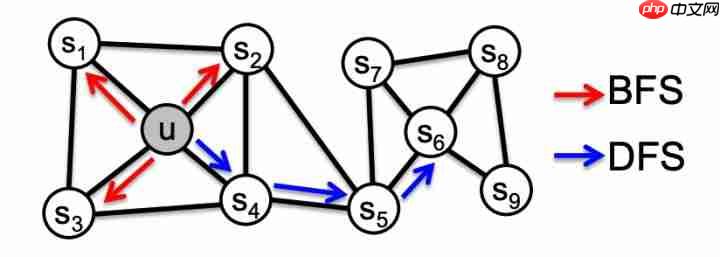
 BFS和DFS表示了根据搜索空间进行探索的两种极限情况。
BFS和DFS表示了根据搜索空间进行探索的两种极限情况。
特别的,在网络上的节点的预测任务通常会是两种类型相似度的混合:同质等价和结构等价。在同质假设下,节点高度交错连接,并且属于同网络聚类或社群,在embedding上更紧密(例如:图中的节点
 和u属于相同的网络社群)。相反的,结构等价假设下,在网络上具有相似结构角色的节点,应该在embedding上更紧密(例如:节点u和
和u属于相同的网络社群)。相反的,结构等价假设下,在网络上具有相似结构角色的节点,应该在embedding上更紧密(例如:节点u和
 在图上扮演着相应社群中心的角色)。更重要的是,不同于同质等价,结构等价不强调连通性;在网络中的节点可以离得很远,但它们仍具有相近的网络结构角色。在真实世界中,这些等价概念并不是排斥的;网络通常具有两者的行为。
在图上扮演着相应社群中心的角色)。更重要的是,不同于同质等价,结构等价不强调连通性;在网络中的节点可以离得很远,但它们仍具有相近的网络结构角色。在真实世界中,这些等价概念并不是排斥的;网络通常具有两者的行为。
我们观察到,BFS和DFS的策略在处理表示时扮演着重要角色,它影响着上述两种等价。特别的,BFS抽样的邻节点会导致embedding与结构等价更紧密。直觉上,我们注意到,为了探明结构等价,通常会对局部邻节点进行精准的描述。例如,基于网络角色(桥接:bridges、中心:hubs)的结构等价可以通过观察每个节点的立即邻节点观察到。通过将搜索限制到邻近节点,BFS达到了这种描述,并且获得了关于每个节点的邻近点的微观视角。另外,在BFS中,在抽样邻节点上的节点趋向于重复多次。这很重要,对于。
node2vec基于上述观察,论文设计了一种灵活的邻节点抽样策略,它允许我们在BFS和DFS间进行平衡。论文通过开发一种灵活的有偏随机游走过程,它可以以BFS和DFS的方式来探索邻节点。
随机游走

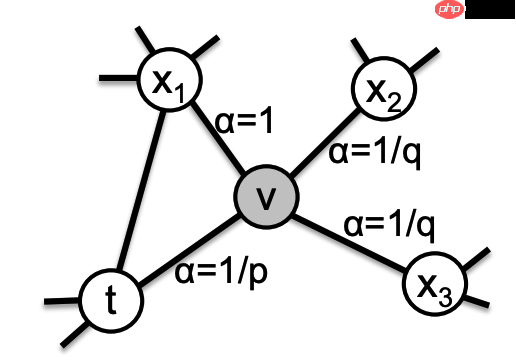
 直觉上,参数p和q控制着该walk从起始节点u进行探索和离开邻节点的快慢。特别的,该参数允许我们的搜索过程(近似)在BFS和DFS间进行插值,从而影响不同节点等价的紧密关系。
直觉上,参数p和q控制着该walk从起始节点u进行探索和离开邻节点的快慢。特别的,该参数允许我们的搜索过程(近似)在BFS和DFS间进行插值,从而影响不同节点等价的紧密关系。
返回(Return)参数:p。参数p控制着在walk中立即访问一个节点的似然。将它设置成一个高值(> max(q,1)),可以确保在接下来的两步内对一个已经访问节点进行抽样的可能性变得很小。(除非在walk内的下一个节点没有其它邻居)。这种策略鼓励适度探索,避免在抽样时存在二跳内重复。另一方面,如果p很小(< min(q,1)),则鼓励在walk中重复访问已经访问过的节点,从而保持在局部区域内进行搜索。
入出(In-out)参数:q。参数q允许搜索在“inward”和"outward"节点间区分。如果q>1, 随机游走会偏向于更接近节点t的节点。这样的walk会根据在walk中各自的起始节点获得一个关于底层graph的局部视图,近似的BFS行为感觉上我们的抽样在一个小的局部内的节点组成。
作为对比,如果 q < 1,随机游走会倾向于更远离节点t的节点,从而鼓励更广泛的探索,近似DFS行为。这使得我们的抽样能够捕捉到更广泛的网络结构。
设置成关于一个在walk t内前继节点的函数,随机游走是2-order markovian。

node2vec实战
node2vec算法
node2vec代码
代码语言:javascript
代码运行次数:0
运行 复制from gensim.models import Word2Vec
from gensim import __version__ as gensim_version
import numpy as np
from numba import njit
from tqdm import tqdm
<p>@njit
def set_seed(seed):
np.random.seed(seed)</p><p>class Node2Vec(Word2Vec):
def <strong>init</strong>(
self,
graph,
dim,
walk_length,
context,
p=1.0,
q=1.0,
workers=1,
batch_walks=None,
seed=None,
<strong>args,
):
assert walk_length >= context
super(Node2Vec, self).<strong>init</strong>(
size=dim,
window=context,
min_count=0,
sg=1,
hs=0,
negative=5,
workers=workers,
seed=seed,
</strong>args
)
self.graph = graph
self.walk_length = walk_length
self.p = p
self.q = q
self.batch_walks = batch_walks
self.seed = seed</p><pre class="brush:php;toolbar:false;"><code>def _biased_walk(self, start_node):
walk = [start_node]
while len(walk) < self.walk_length:
cur = walk[-1]
cur_nbrs = list(self.graph.neighbors(cur))
if len(cur_nbrs) > 0:
if len(walk) == 1:
walk.append(np.random.choice(cur_nbrs))
else:
prev = walk[-2]
probs = []
for dst in cur_nbrs:
if dst == prev:
prob = 1 / self.p
elif self.graph.has_edge(prev, dst):
prob = 1
else:
prob = 1 / self.q
probs.append(prob)
probs = np.array(probs) / np.sum(probs)
walk.append(np.random.choice(cur_nbrs, p=probs))
else:
break
return walk
def _simulate_walks(self, num_walks):
walks = []
nodes = list(self.graph.nodes())
for _ in range(num_walks):
np.random.shuffle(nodes)
for node in nodes:
walks.append(self._biased_walk(node))
return walks
def train(self, epochs=1, batch_size=1000, total_examples=None, total_words=None, **kwargs):
if total_examples is None:
total_examples = len(self.graph.nodes()) * epochs
if total_words is None:
total_words = total_examples * self.walk_length
for epoch in range(epochs):
walks = self._simulate_walks(1)
if self.batch_walks is not None:
for i in range(0, len(walks), self.batch_walks):
batch = walks[i:i + self.batch_walks]
self.build_vocab(batch, update=True)
self.train(batch, total_examples=len(batch), total_words=len(batch) * self.walk_length, epochs=1, **kwargs)
else:
self.build_vocab(walks, update=True)
self.train(walks, total_examples=total_examples, total_words=total_words, epochs=1, **kwargs)调用方式
代码语言:javascript
代码运行次数:0
运行复制import networkx as nx <h1>生成图,df为数据集</h1><p>G = nx.Graph(df[["user_id", "item_id"]].values.tolist(), directed=False, weighted=False)</p><h1>调用Node2Vec</h1><p>model = Node2Vec(G, dim=16, walk_length=100, context=5, p=2.0, q=0.5, workers=20) model.train(epochs=5)
以上就是GraphEmbedding实战系列:Node2vec原理与代码实战的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 405
405



















