
进程切换,也称为任务切换、上下文切换或任务调度,本文将探讨linux内核中进程切换的实现。我们首先理解几个关键概念。
每个进程都有自己的地址空间,但所有进程共享CPU寄存器。因此,在恢复进程执行前,内核必须确保挂起时的寄存器值被重新加载到CPU寄存器中。
这些需要加载到CPU寄存器中的值称为硬件上下文。硬件上下文是进程执行上下文的一个子集,包含进程执行所需的所有信息。在Linux中,进程的硬件上下文部分存储在进程描述符中,另一部分存储在内核态栈中。
在下文中,我们假设prev指向旧进程,next指向新进程。因此,进程切换就是保存prev进程的硬件上下文,然后加载next进程的硬件上下文。由于进程切换非常频繁,缩短保存和加载硬件上下文的时间至关重要。
旧版本的Linux利用x86架构提供的硬件支持,通过远程跳转指令(GNU-ljump;Intel-jmp far)进行进程切换,跳转到下一个进程的任务状态段(TSS)描述符。执行这条跳转指令时,CPU会自动执行硬件上下文切换,保存旧的硬件上下文,加载新的硬件上下文。然而,Linux 2.6版本以后,通过软件进行进程切换,原因如下:
通过一系列的mov指令逐步执行切换,可以更好地控制加载数据的合法性。特别是ds和es段寄存器的值,可能会被恶意用户篡改。使用远程跳转指令无法进行数据检查。新旧方法所需的时间大致相同。但是,优化硬件上下文切换是不可能的,因为这是由CPU完成的,而Linux使用软件替代硬件上下文切换,因此有优化的空间,以提高执行时间。进程切换只能在内核态发生。在进程切换之前,用户态进程使用的所有寄存器内容都已经包含在内核态栈中,其中包括指定用户态进程栈指针地址的ss和esp寄存器内容。
x86架构包含一个特殊的段寄存器,称为任务状态段(TSS),用来保存硬件上下文内容。尽管Linux不使用硬件上下文切换,但还是为每个不同CPU建立一个TSS。这么做的原因有两个:
当用户态进程执行in或out指令时,I/O控制单元会检查eflags寄存器中的IOPL位(2位)。如果等于3,也就是超级用户权限,进程对于该I/O端口来说就是一个超级用户,直接执行I/O指令。否则,继续执行检查。访问tr寄存器,确定当前的TSS,以及正确的I/O访问权限。它检查I/O端口对应的访问权限位。如果清零,指令被执行;否则,控制单元发出常规保护的异常。内核中使用tss_struct结构体描述TSS。init_tss数组为系统中的每一个CPU包含一个tss_struct结构。每一次进程切换,内核更新TSS相关内容,使CPU控制单元能够安全地检索自己想要的信息。因此,TSS反映了当前运行在CPU上的进程的特权级别,但当进程不运行时,无需维护这些信息。
每个TSS具有8个字节长度的任务状态段描述符(TSSD)。这个描述符包含一个32位的基地址,指向TSS的起始地址,以及20位的Limit域,表示页的大小。TSSD的S标志被清零,说明这是一个系统段(参见第2章的段描述符)。
Type域设置为9或11都可以,表明该段是一个TSS段即可。Intel最初的设计中,系统中的每个进程都应该引用自己的TSS:Type域的低第2个有效位称为Busy位,如果被设为1,进程正在CPU上执行;设为0,没有执行。在Linux的设计中,每个CPU只有一个TSS,所以,Busy位总是设为1。换句话说,Linux中Type域一般为11。
创建的这些TSSD存储在全局描述符表(GDT)中,该表的基地址存储在CPU的gdtr寄存器中。每个CPU的tr寄存器包含对应TSS的TSSD选择器,还包含两个隐藏的、不可编程的域:TSSD的Base和Limit域。使用这种方法,CPU可以直接寻址TSS,而不必非得访问GDT中TSS的地址。
每当进程切换时,将要被替换掉的进程硬件上下文内容都应该被保存到某个地址。显然不能保存在TSS中,因为Linux为每个CPU建立了一个TSS,而不是为每个进程建立TSS。
因此,进程描述符中添加了一个类型为thread_struct的结构,通过它,内核保存旧进程的硬件上下文。后面我们会看到,该数据结构包含了大部分的CPU寄存器,除了通用目的寄存器,比如eax、ebx等,它们被存储在内核态栈中。
进程切换的时机:在中断处理程序中直接调用schedule()函数,实现进程调度。内核线程是一个特殊的进程,只有内核态没有用户态。因此既可以主动调用schedule()函数进行调度,也可以被中断处理程序调用。内核态进程无法直接主动调度,因为schedule()是一个内核函数,不是系统调用。因此只能在中断处理程序中进行调度。关键代码梳理如下:
首先,schedule()函数会调用next = pick_next_task(rq, prev);,根据调度算法策略,选取要执行的下一个进程。其次,根据调度策略得到要执行的进程后,调用context_switch(rq, prev, next);,完成进程上下文切换。其中,最关键的switch_to(prev,next, prev);切换堆栈和寄存器的状态。我们假设prev指向被切换掉的进程描述符,next指向将要执行的进程描述符。我们将会在第7章发现,prev和next正是schedule()函数的局部变量。
switch_to宏进程硬件上下文的切换是由宏switch_to完成的。该宏的实现与硬件架构息息相关,要想理解它需要下一番功夫。下面是基于X86架构下的该宏实现的汇编代码:
#define switch_to(prev, next, last) \
do { \
/* 进程切换可能会改变所有的寄存器,所以我们通过未使用的输出变量显式地修改它们。 */ \
/* EAX和EBP没有被列出,是因为EBP是为当前进程访问显式地保存和恢复的寄存器, */ \
/* 而EAX将会作为函数__switch_to()的返回值。 */ \
unsigned long ebx, ecx, edx, esi, edi; \
\
asm volatile("pushfl\n\t" /* save flags */ \
"pushl %%ebp\n\t" /* save EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
"movl %[next_sp],%%esp\n\t" /* restore ESP */ \
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \
"pushl %[next_ip]\n\t" /* restore EIP */ \
__switch_canary \
__retpoline_fill_return_buffer \
"jmp __switch_to\n" /* regparm call */ \
"1:\t" \
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* 输出参数 */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* 列出所有可能会修改的寄存器 */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* 输入参数 */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* 为函数__switch_to()设置寄存器参数 */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while (0)首先,该宏具有3个参数,prev、next和last。prev和next这两个参数很容易理解,分别指向新旧进程的描述符地址;last是一个输出参数,用来记录是从哪个进程切换来的。为什么需要last参数呢?当进程切换涉及到3个进程的时候,3个进程分别假设为A、B、C。假设内核决定关掉A进程,激活B进程。在schedule函数中,prev指向A的描述符,而next指向B的描述符。只要switch_to宏使A失效,A的执行流就会冻结。后面,当内核想要重新激活A,必须关掉C进程,就要再执行一次switch_to宏,此时prev指向C,next指向A。当A进程想要继续执行之前的执行流时,会查找原先的内核态栈,发现prev等于A进程描述符,next等于B进程描述符。此时,调度器失去了对C进程的引用。保留这个引用非常有用,我们后面再讨论。图3-7分别展示了进程A、B和C内核态栈的内容,及寄存器eax的值。还展示了last的值,随后被eax中的值覆盖。
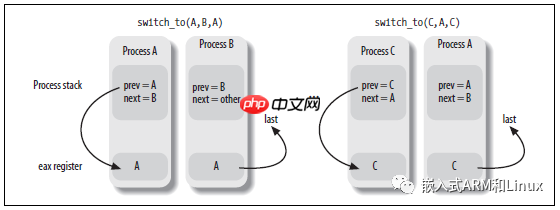
switch_to宏的处理过程如下:
eflags和ebp寄存器的内容。esp到prev->thread.esp中。484(%eax)表明目的地址是寄存器eax中的地址加上484。esp寄存器中。movl 484(%edx), %esp
1的地址->prev->thread.eip。movl $1f, 480(%eax)
__switch_to()函数执行,是一个C函数。至此,进程A被进程B取代:开始执行B进程的指令。第一步应该是先弹出eflags和ebp寄存器的值。
eax寄存器的内容(第一步加载的)到last变量中。也就是说,last记录了被取代的进程。__switch_to()函数实际上,大部分的进程切换工作是由__switch_to()函数完成的,它的参数是prev_p和next_p,分别指向旧进程和新进程。这个函数和普通的函数有些差别,因为__switch_to()函数从eax和edx寄存器中获取prev_p和next_p这两个参数(在分析switch_to宏的时候已经讲过),而不是像普通函数那样,从栈中获取参数。为了强制函数从寄存器中获取参数,内核使用__attribute__和regparm进行声明。这是gcc编译器对C语言的一个非标准扩展。__switch_to()函数定义在include/asm-i386/system.h文件中:
__switch_to(struct task_struct *prev_p, struct task_struct *next_p) __attribute__((regparm(3)));
这个函数执行的内容:
__unlazy_fpu()宏,保存旧进程的FPU、MMX和XMM寄存器。smp_processor_id()宏,获取正在执行代码的CPU的ID。从thread_info结构的cpu成员中获取。next_p->thread.esp0到当前CPU的TSS段中的esp0成员中。通过调用sysenter汇编指令从用户态切换到内核态引起的任何特权级别的改变都会导致将这个地址拷贝到esp寄存器中。tls_array数组中。fs和gs段寄存器的内容到旧进程的prev_p->thread.fs和prev_p->thread.gs中。汇编指令如下:寄存器esi指向prev_p->thread结构。gs寄存器用来存放TLS段的地址。fs寄存器实际上Windows使用。
fs或gs寄存器内容。数据来源是新进程的thread_struct描述符中对应的值。汇编语言如下:ebx寄存器指向next_p->thread结构。
__switch_to()函数结束。相应的汇编语言就是:
因为switch_to总是假设eax寄存器保存旧进程的进程描述符的地址。所以,这里把prev_p变量再次写入到eax寄存器中。
以上就是Linux内核13-进程切换的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 405
405



















