
对比学习的概念最早由sumit chopra等人于2005年提出。这种学习方法从相似或不相似的数据对中学习相似或不相似的特征表示。常用的损失函数是infonce,如下图所示:
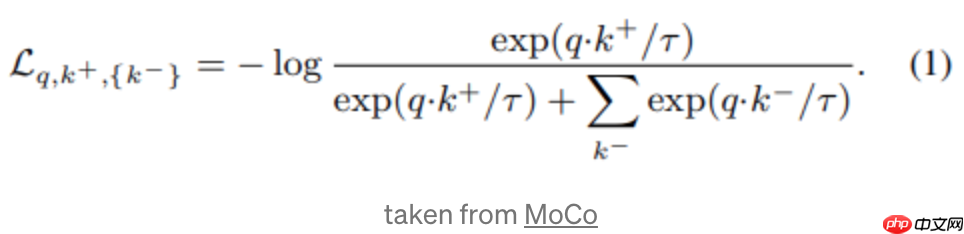 其中,q是查询样本的表达,k+和k-分别是正例和负例的表达。通常,q和k是同一张图片的增强样本。最后,温度超参数tau用于调整敏感度,这在许多对比学习论文中都是常见的思路。
其中,q是查询样本的表达,k+和k-分别是正例和负例的表达。通常,q和k是同一张图片的增强样本。最后,温度超参数tau用于调整敏感度,这在许多对比学习论文中都是常见的思路。
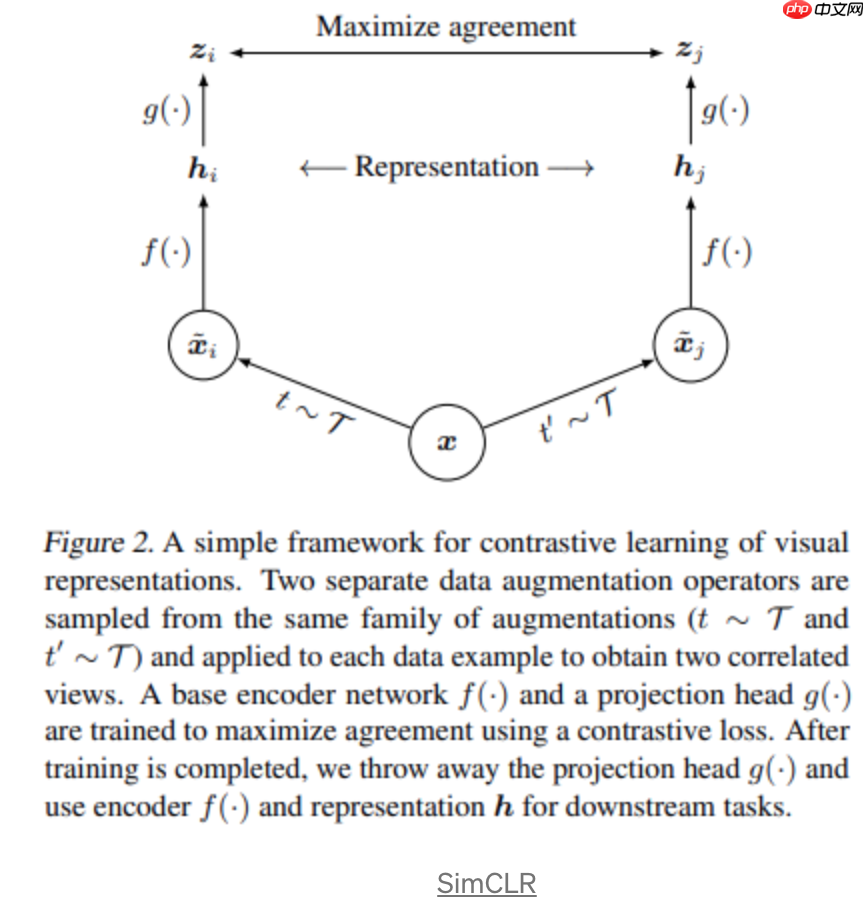
对比学习的简单框架中,最著名的当属Ting Chen等人提出的SimCLR。
 首先,我们通过对一个mini-batch进行增强,以获得正样本对。然后,将相同的编码器f和投影g(MLP)应用于增强样本。最后,我们使用上面定义的对比损失来最大化相同样本图像的正样本对之间的一致性,最小化距离。需要注意的是,batchsize越大,对比学习框架中的负样本就越多,这带来了计算复杂度。
首先,我们通过对一个mini-batch进行增强,以获得正样本对。然后,将相同的编码器f和投影g(MLP)应用于增强样本。最后,我们使用上面定义的对比损失来最大化相同样本图像的正样本对之间的一致性,最小化距离。需要注意的是,batchsize越大,对比学习框架中的负样本就越多,这带来了计算复杂度。
 Pretext-Invariant Representations
Pretext-Invariant Representations
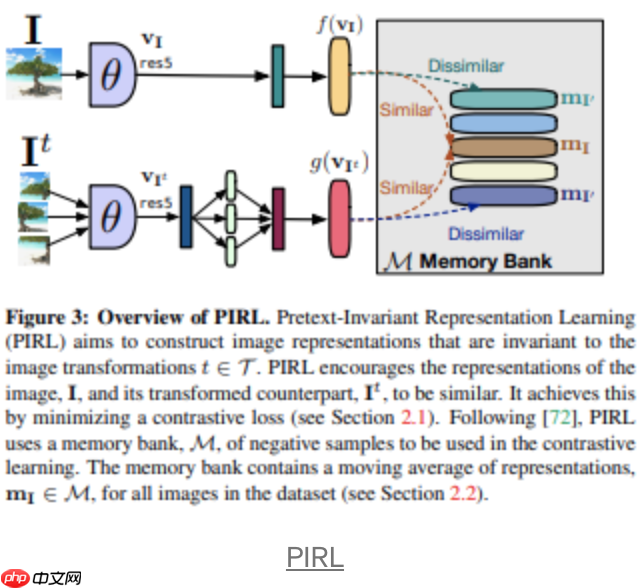 Ishan Misra等人提出了PIRL,上图展示了PIRL框架的概述。I_t是原始样本图像I的增强样本,而θ表示主编码器(ResNet)的权重,f和g是两个独立的投影(全连接层)。正如我们所看到的,我们需要获得9个变换/增强的图像块,并连接它们的表示。最后使用下式进行对比学习:
Ishan Misra等人提出了PIRL,上图展示了PIRL框架的概述。I_t是原始样本图像I的增强样本,而θ表示主编码器(ResNet)的权重,f和g是两个独立的投影(全连接层)。正如我们所看到的,我们需要获得9个变换/增强的图像块,并连接它们的表示。最后使用下式进行对比学习:
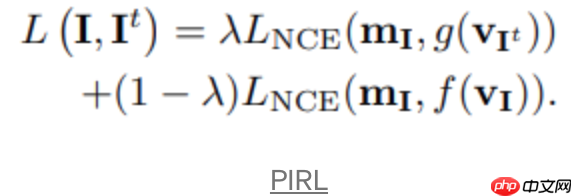 m_I是原始图像的特征向量,使用后会存储在memory bank M中,因此上式的目标是最大化特征向量m_I和来自两个分支的相应投影之间的一致性。需要注意的是,负样本是从memory bank中随机抽取的。
m_I是原始图像的特征向量,使用后会存储在memory bank M中,因此上式的目标是最大化特征向量m_I和来自两个分支的相应投影之间的一致性。需要注意的是,负样本是从memory bank中随机抽取的。
Momentum Contrast
Kaiming He等人提出了MoCo,如下图所示:
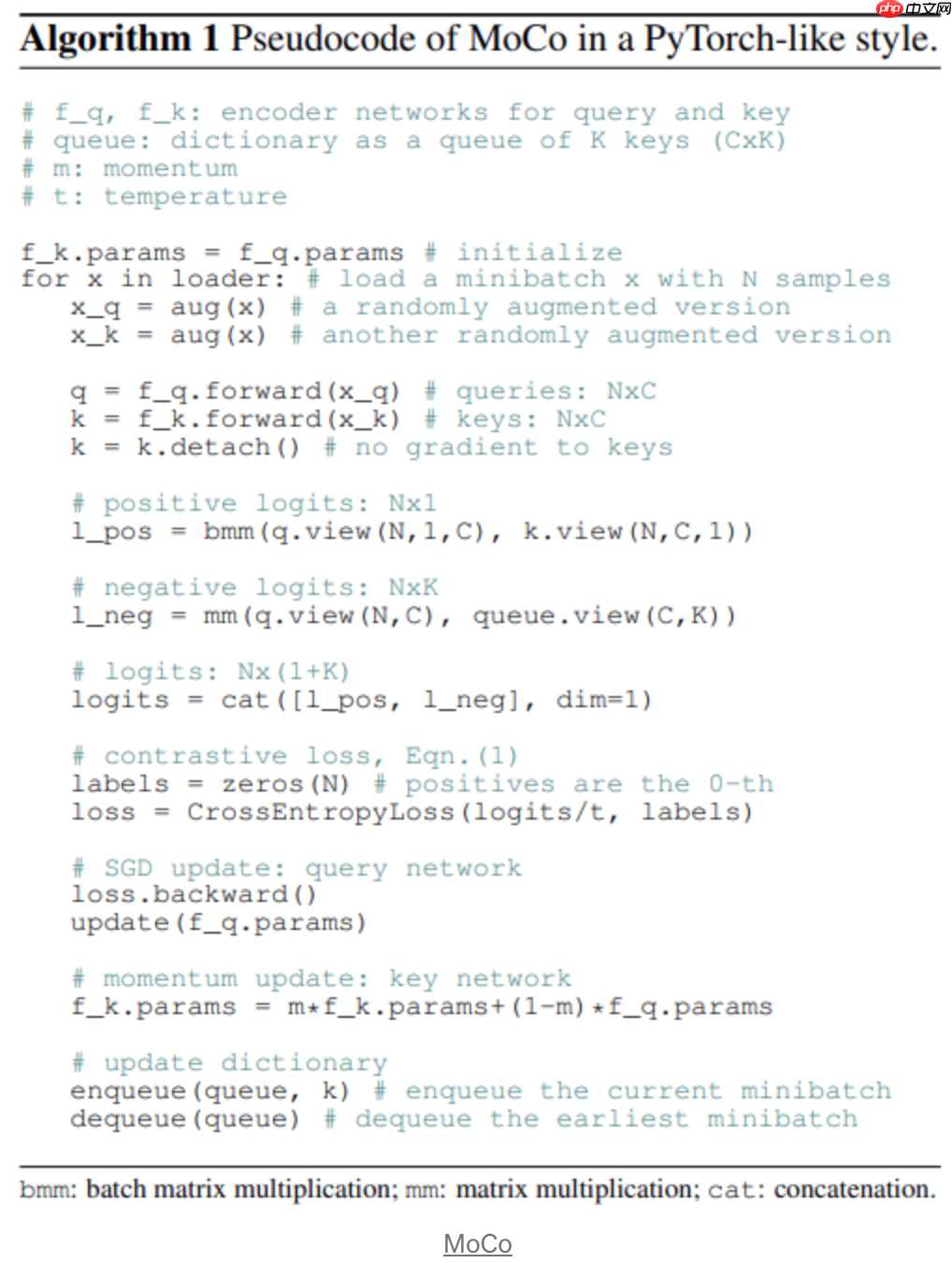
 如图所示,作者放弃了在整个训练过程中存储特征表示的memory bank,因为它在训练中会带来内存开销。相反,他们引入了一个momentum encoder,该编码器被更新为主要在线编码器的移动平均值。此外,他们提出字典作为队列结构(先进先出),它还存储特征表示。它比内存库小得多,因为作者认为不需要存储过去epoch获得的特征向量。如图中所示,对比损失是通过最小化来自两个网络的图像增强pair对的表示距离和最大化从字典中随机抽样的表示距离来实现的。有趣的是,有很多研究表明,由memory实现的表示平均与momentum encoder非常相似。然而,动量编码器显著降低了内存成本。
如图所示,作者放弃了在整个训练过程中存储特征表示的memory bank,因为它在训练中会带来内存开销。相反,他们引入了一个momentum encoder,该编码器被更新为主要在线编码器的移动平均值。此外,他们提出字典作为队列结构(先进先出),它还存储特征表示。它比内存库小得多,因为作者认为不需要存储过去epoch获得的特征向量。如图中所示,对比损失是通过最小化来自两个网络的图像增强pair对的表示距离和最大化从字典中随机抽样的表示距离来实现的。有趣的是,有很多研究表明,由memory实现的表示平均与momentum encoder非常相似。然而,动量编码器显著降低了内存成本。
伪代码如下:
 MoCo V2 & MoCo V3
MoCo V2 & MoCo V3
 MoCo v2对原始框架进行了一些修改。根据上图,总结如下:
MoCo v2对原始框架进行了一些修改。根据上图,总结如下:
1、两个encoder增加了mlp作为最终模块,如下代码所示。我们可以看到,我们只是用一对全连接层替换了最后一个完全连接的层,中间有ReLU激活(隐藏层2048-d,带有ReLU)。
 2、更强的数据增强方式(blur augmentation)
2、更强的数据增强方式(blur augmentation)
3、学习率(cosine learning rate scheduler)
MoCo v3伪代码如下:
 总结就是所有mlp都有BN,并且batch size在4096效果足够好,伪代码中的backbone可以尝试用ViT做替换。
总结就是所有mlp都有BN,并且batch size在4096效果足够好,伪代码中的backbone可以尝试用ViT做替换。
BYOL
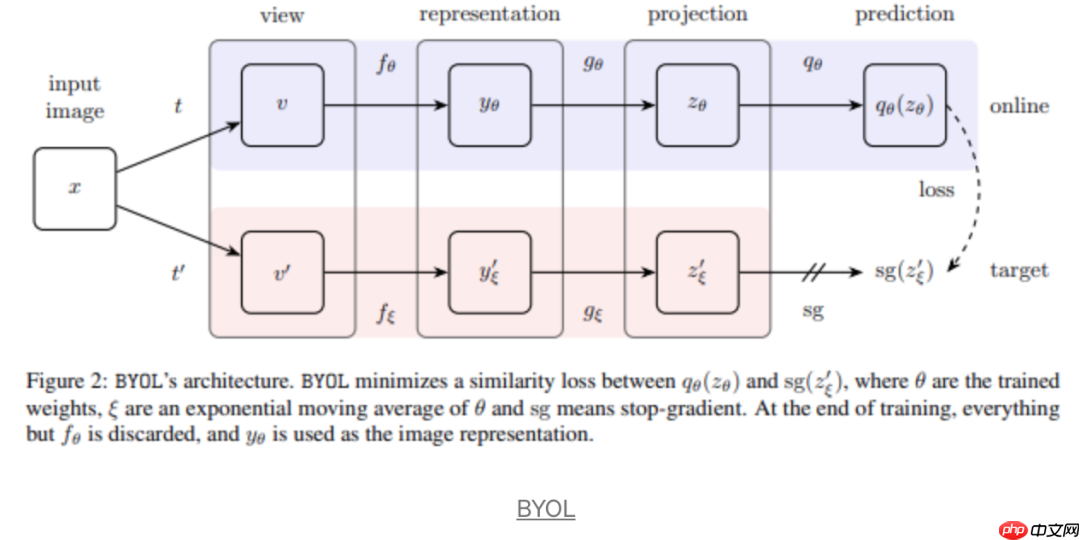 BYOL完全放弃了MoCo和PIRL使用的字典和Memory Buffer的方式,提出了prediction head。上图中,我们可以看到prediction head是作为在线encoder的,并且尝试去预估momentum encoder的投影,prediction head的存在就是避免所有representation都是一样的。
BYOL完全放弃了MoCo和PIRL使用的字典和Memory Buffer的方式,提出了prediction head。上图中,我们可以看到prediction head是作为在线encoder的,并且尝试去预估momentum encoder的投影,prediction head的存在就是避免所有representation都是一样的。
作者完全放弃使用阴性样本,并提出如下损失:
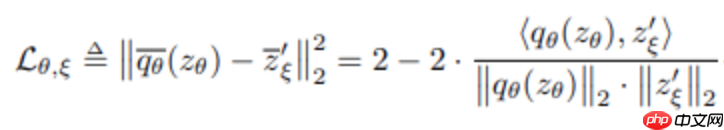 此外还有Siamese和RAFT。以下参考文献中的论文都推荐大家详细阅读。
此外还有Siamese和RAFT。以下参考文献中的论文都推荐大家详细阅读。
参考文献
1、Learning a Similarity Metric Discriminatively, with Application to Face Verification
https://www.php.cn/link/f2013aa6b8488641df6c34959d797e15
2、A Simple Framework for Contrastive Learning of Visual Representations
https://www.php.cn/link/642ad51faa492de9795844a2d0c6142f
3、Self-Supervised Learning of Pretext-Invariant Representations
https://www.php.cn/link/3e0ce87560cc1e32353de7d1eedb58f9
4、Momentum Contrast for Unsupervised Visual Representation Learning
https://www.php.cn/link/0f49d14c2bfc523456225589dc27b6db
5、Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
https://www.php.cn/link/386bb25138d5c75aaf86b0a6d4d8f772
6、An Empirical Study of Training Self-Supervised Vision Transformers
https://www.php.cn/link/0d6e3d4f4acc0e9bda9ac92a85810ad3
7、Exploring Simple Siamese Representation Learning
https://www.php.cn/link/413610d3d97250aabb9ffb2683e07922
8、RUN AWAY FROM YOUR TEACHER: UNDERSTANDING BYOL BY A NOVEL SELF-SUPERVISED APPROACH
https://www.php.cn/link/15a31d27f7897f1c0e786e05e0007cc6
以上就是一文看清这些年自监督和无监督的进展的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 446
446
























