

概述Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink通过数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统能够处理批处理和流处理程序。此外,Flink的运行时也支持迭代算法的执行。百度百科
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。Flink 设计为在所有常见的集群环境中运行,以内存中的速度和任何规模执行计算。Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架。
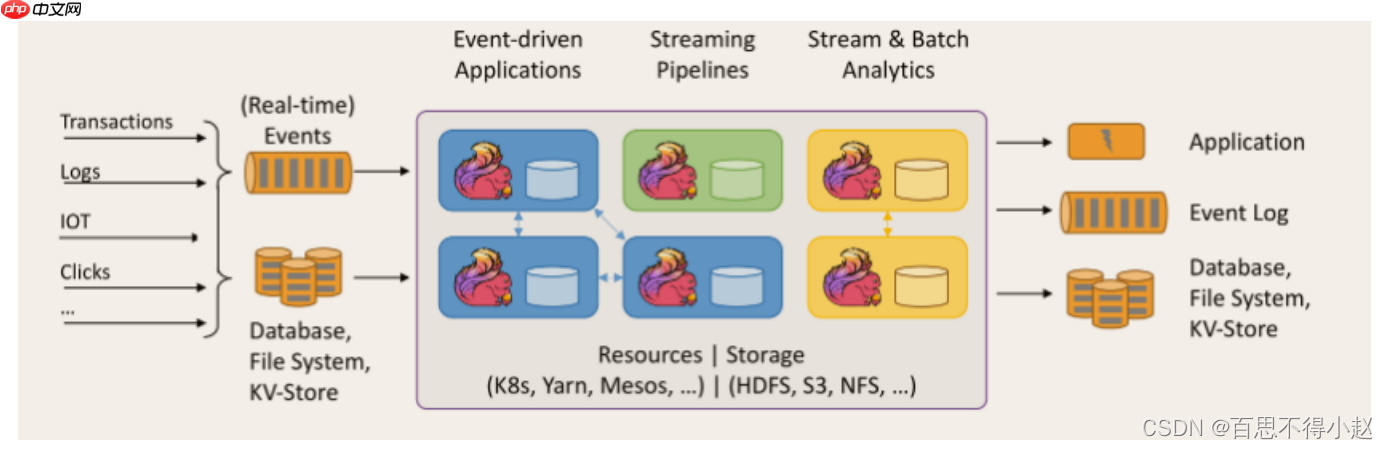
特点低延时实时流处理代码编写简单 Flink 是最近几代通用大数据框架之一,相较于一系列老前辈而言应用广泛、使用简便。支持大型、复杂的状态处理 允许有数百 GB 以上的状态存储。支持大规模分布式部署 自身有 Standalone 集群模式,也支持部署到 Yarn、K8S 上。迭代速度快结果准确性和良好的容错性使用的一般场景机器资源非常的多:能够提供至少 24 个 CPU 核心和百 GB 以上的内存,Flink 所在的机器硬盘必须为 SSD吞吐量大或未来扩展要求很大:每秒一万条只能勉强算大,十万条可以算大需求复杂:有大量复杂的清洗、去重、转换等操作 对低延时有极高要求:10秒以内的延迟才能算作低延迟,1 秒以内的延迟要求就需要非常仔细地处理事件驱动事件驱动类型的应用,它是一类有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以 kafka 为代表的消息队列几乎都是事件驱动型应用。
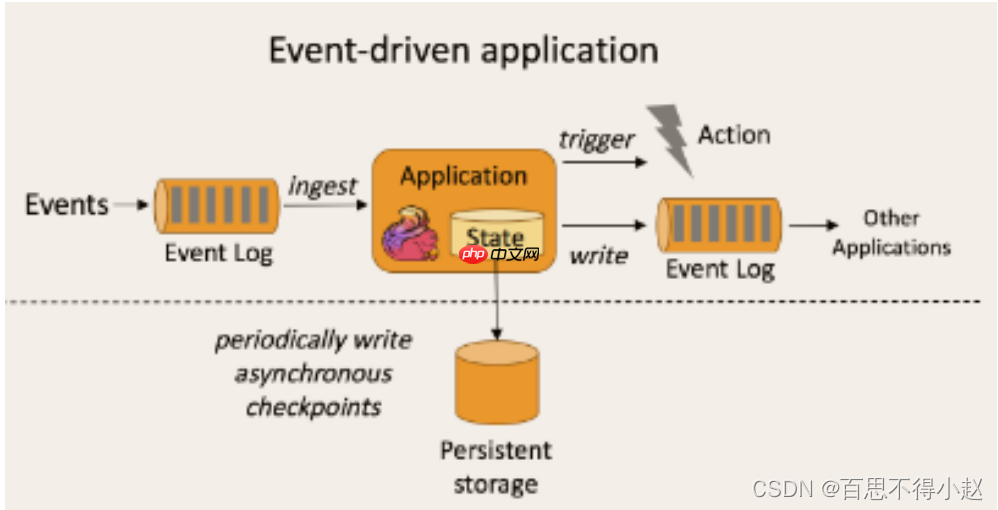
流处理和批处理流处理和批处理是两种不同处理数据的方式,接下来我们详细了解一下两者的不同之处。
批处理批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,通常用于离线统计。换句话说,批处理的触发点是数据无关的。可以是定时触发,也可以是一定数量触发,或者是一张表、一套文件导入后触发。
流处理流处理的特点是无界、实时,不需要针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,通常用于实时统计。换句话说,流处理的触发点是数据相关的。是由事件驱动的体系结构,其中任何一个部分都是收到一条数据后立刻分析与触发有关的信息并执行处理,例如 offset、例如 time、例如特定字段值满足要求。
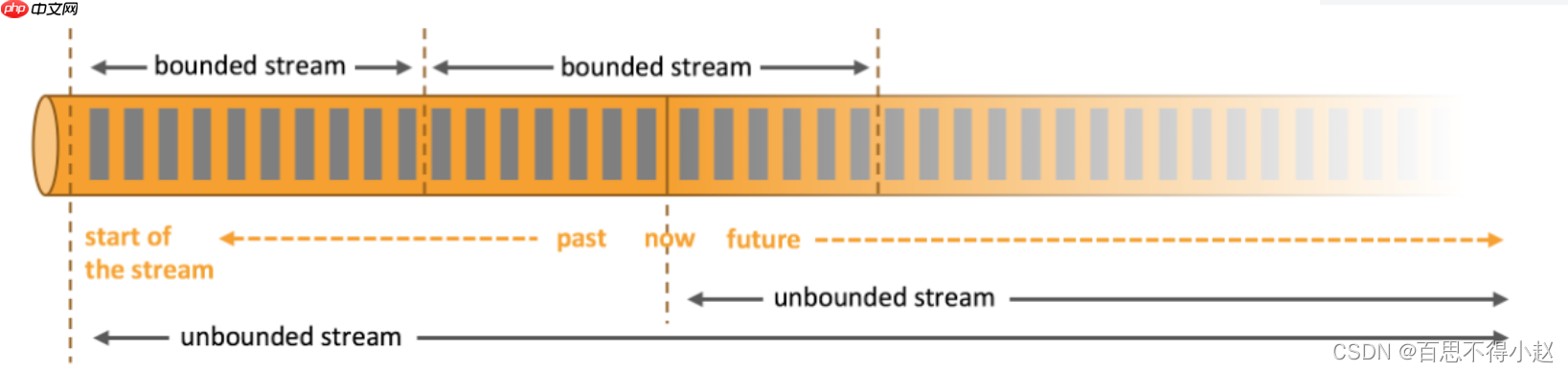
两者区别对比数据时效性数据特征应用场景运行方式处理效能Flink中的数据处理方式在Flink的世界里,一切数据都是由流组成的,任何类型的数据都是作为事件流产生的。信用卡交易、传感器测量、机器日志或网站或移动应用程序上的用户交互,所有这些数据都以流的形式生成,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。无界流
无界流有一个开始但没有定义的结束。它们不会终止并在生成数据时提供数据。必须连续处理无界流,即事件必须在被摄取后立即处理。不可能等待所有输入数据到达,因为输入是无界的并且不会在任何时间点完成。处理无界数据通常需要以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断结果的完整性。
无界数据流就是指有始无终的数据,数据一旦开始生成就会持续不断地产生新的数据,即数据没有时间边界。无界数据流需要持续不断地处理。
有界流有界流具有定义的开始和结束。可以通过在执行任何计算之前摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为始终可以对有界数据集进行排序。有界流的处理也称为批处理。
有界数据流就是指输入的数据有始有终。例如数据可能是一分钟或者一天的交易数据等等
Flink编程模型(API)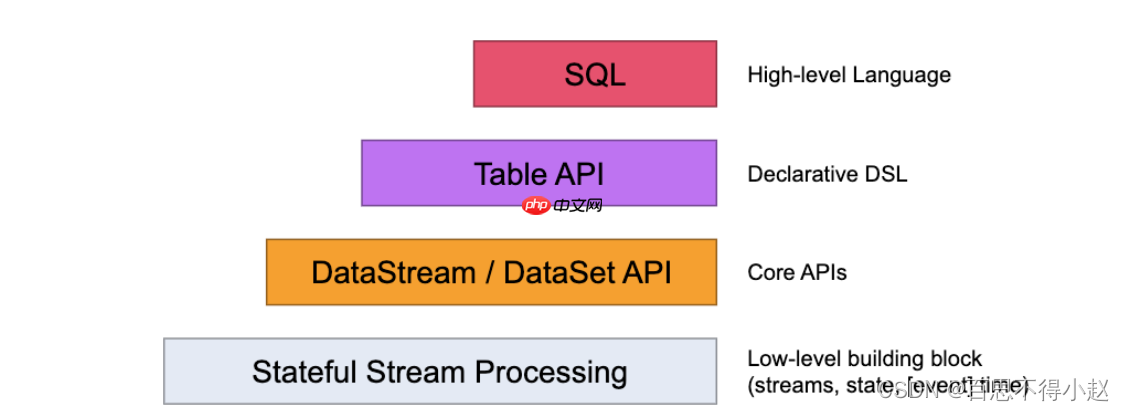 用于开发的是第三层,即DataStrem/DataSetAPI。用户可以使用DataStream API处理无界数据流,使用DataSet API处理有界数据流。同时这两个API都提供了各种各样的接口来处理数据。例如常见的map、filter、flatMap等等,而且支持python,scala,java等编程语言。
用于开发的是第三层,即DataStrem/DataSetAPI。用户可以使用DataStream API处理无界数据流,使用DataSet API处理有界数据流。同时这两个API都提供了各种各样的接口来处理数据。例如常见的map、filter、flatMap等等,而且支持python,scala,java等编程语言。
以上就是主流实时流处理计算框架Flink初体验的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 748
748
























