
作者:edison_g
 1、前言摘要
1、前言摘要
尽管AdderNet在图像分类任务中取得了成功,但将其直接应用于图像超分辨率任务却面临挑战。具体而言,加法器操作难以学习标识映射,这对于图像处理任务至关重要。此外,AdderNet无法保证高通滤波器的功能。
为此,研究人员深入探讨了加法器操作与标识映射之间的关系,并通过插入快捷方式来提升使用加法器网络的超分辨率(SR)模型的表现。随后,研究人员开发了一种可学习的power activation机制,以调整特征分布和细化细节。实验结果表明,基于加法网络的图像超分辨率模型在几个基准模型和数据集上实现了与其CNN基线相当的性能和视觉质量,同时能耗降低了约2倍。
 2、相关领域及回顾
2、相关领域及回顾
AdderNet加法网络此前已由“计算机视觉研究院”平台详细分析,并移植到目标检测任务中,具体链接如下:
CVPR2020最佳目标检测 | AdderNet(加法网络)含论文及源码链接
代码实践 | CVPR2020——AdderNet(加法网络)迁移到检测网络(代码分享)
现有高效的超分辨率方法旨在减少模型的参数或计算量。最近,[Hanting Chen, Yunhe Wang, Chunjing Xu, Boxin Shi, Chao Xu, Qi Tian, and Chang Xu. Addernet: Do we really need multiplications in deep learning? In CVPR, 2020]提出了一种通过用加法运算代替乘法来降低网络功耗的新方法。它在卷积层中不使用乘法,在分类任务上实现了边际精度损失。本研究的目标是提升加法网络在超分辨率任务中的性能。
Preliminaries and Motivation在此,我们首先简要介绍了使用深度学习方法进行单个图像超分辨率任务,然后讨论了直接使用AdderNet构建节能SR模型的困难。现有的超分辨率方法大致分为三类:基于插值的方法、基于字典的方法和基于深度学习的方法。在过去的十年里,由于其显著的表现,研究重点已经转移到深度学习方法上。[Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super-resolution. In ECCV, pages 184–199, 2014]首次引入了深度学习方法来实现超分辨率,并取得了比传统方法更好的性能。传统SISR任务的总体目标函数可以表述为:
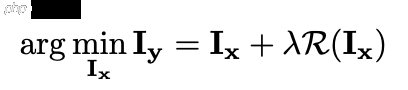 尽管下面的公式显示了类似的性能,但上面的公式定义了SISR问题。与传统的识别任务有很大不同。例如,我们需要确保输出结果保持X(即Iy)中的原始纹理,这是下面的公式难以学习的。因此,我们应该设计一个新的AdderNet框架来构建节能SISR模型。
尽管下面的公式显示了类似的性能,但上面的公式定义了SISR问题。与传统的识别任务有很大不同。例如,我们需要确保输出结果保持X(即Iy)中的原始纹理,这是下面的公式难以学习的。因此,我们应该设计一个新的AdderNet框架来构建节能SISR模型。
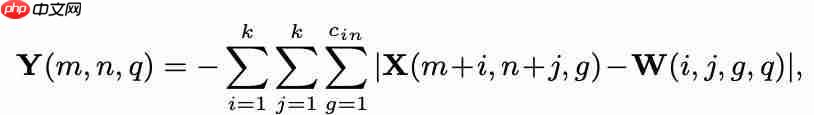 3、AdderNet for Image Super-Resolution
3、AdderNet for Image Super-Resolution
学习标识映射使用AdderNet 然后选择每个元素的合适值:
然后选择每个元素的合适值:
 可学习的power activation除了标识映射外,传统卷积滤波器还有另一个重要的功能,不能轻易通过加法滤波器来保证。SISR模型的目标是增强输入低分辨率图像的细节,包括颜色和纹理信息。因此,在现有的SISR模型中,高通滤波器也是一个非常重要的组成部分。可以在下图中找到,当网络深度增加时,输入图像的细节逐渐增强。
可学习的power activation除了标识映射外,传统卷积滤波器还有另一个重要的功能,不能轻易通过加法滤波器来保证。SISR模型的目标是增强输入低分辨率图像的细节,包括颜色和纹理信息。因此,在现有的SISR模型中,高通滤波器也是一个非常重要的组成部分。可以在下图中找到,当网络深度增加时,输入图像的细节逐渐增强。
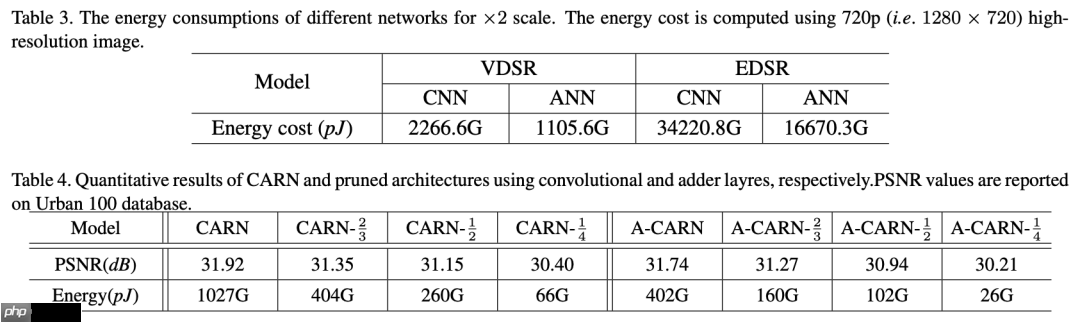
 4、实验
4、实验
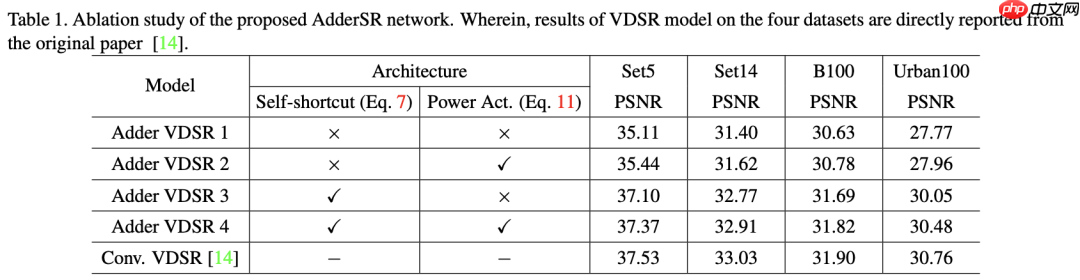
 在具有不同策略的AdderSR网络中加法层的输出特征图
在具有不同策略的AdderSR网络中加法层的输出特征图
 [14]:Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Accurate image super-resolution using very deep convolutional networks. In CVPR, pages 1646–1654, 2016.
[14]:Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Accurate image super-resolution using very deep convolutional networks. In CVPR, pages 1646–1654, 2016.
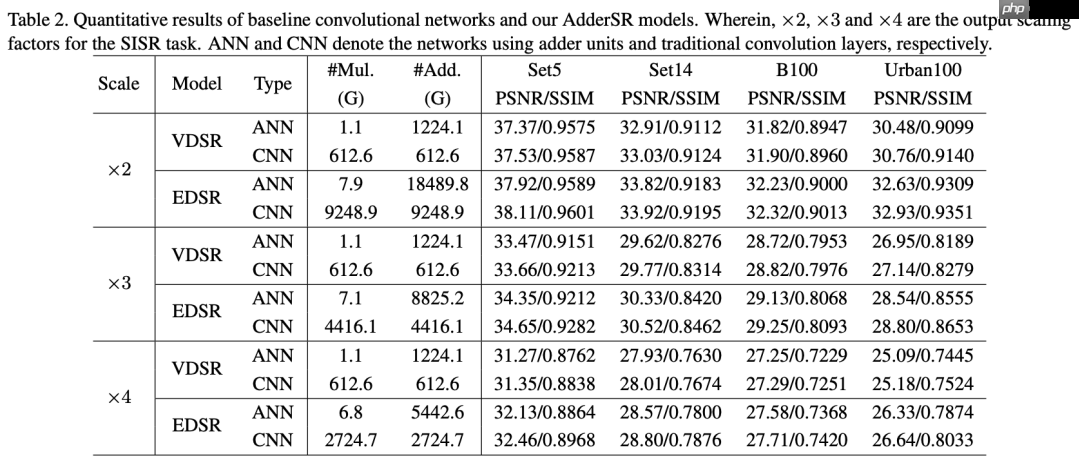
 AdderSR网络与CNN在×3缩放比例下的超分辨率图像可视化
AdderSR网络与CNN在×3缩放比例下的超分辨率图像可视化
 © The Endin
© The Endin
以上就是华为出品 | 加法网络应用于图像超分辨率(附github源码及论文下载)的详细内容,更多请关注php中文网其它相关文章!

 C++高性能并发应用_C++如何开发性能关键应用
C++高性能并发应用_C++如何开发性能关键应用
 Java AI集成Deep Java Library_Java怎么集成AI模型部署
Java AI集成Deep Java Library_Java怎么集成AI模型部署
 Golang后端API开发_Golang如何高效开发后端和API
Golang后端API开发_Golang如何高效开发后端和API
 Python异步并发改进_Python异步编程有哪些新改进
Python异步并发改进_Python异步编程有哪些新改进
 C++系统编程内存管理_C++系统编程怎么与Rust竞争内存安全
C++系统编程内存管理_C++系统编程怎么与Rust竞争内存安全
 Java GraalVM原生镜像构建_Java怎么用GraalVM构建高效原生镜像
Java GraalVM原生镜像构建_Java怎么用GraalVM构建高效原生镜像
 Python FastAPI异步API开发_Python怎么用FastAPI构建异步API
Python FastAPI异步API开发_Python怎么用FastAPI构建异步API
 C++现代C++20/23/26特性_现代C++有哪些新标准特性如modules和coroutines
C++现代C++20/23/26特性_现代C++有哪些新标准特性如modules和coroutines
Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 838
838

















