

前言✦
对于 mmpose 我是慕名已久,一直以来跟不少做 pose 的大佬交流时也常常提起,说同样的模型用 mmpose 跑出来点数会高不少,然而 mm 系列的封装逻辑和学习门槛让我一再搁置,终于最近才下定决心要把它啃下来。
本系列将记录我第一次接触 MMPose 系列的学习轨迹,学习思路,以及过程中的一些心得体会。
由于我目前主要研究领域是轻量级的手部姿态估计,据我初步观察,MMPose 复现的工作主要集中在 Heatmap-based 方法,因此我也希望之后有机会给 MMPose 做一些 PR,将我复现的近期的一些 Regression-based 方法加入其中,这算是我为本次学习立的一个小目标。
初步计划✦
由于是第一次接触,我给自己粗略列出了一个学习计划,依次进行完成,以对 MMPose 的基本功能有一个直观的感受:
· 基于预训练模型,在自己的图片上进行推理测试
· 编写一个脚本,在本地摄像头上进行实时推理
· 导出 ONNX 格式文件,测试转 MNN 流程,校验转换后的模型精度损失
我希望通过以上内容让我搞清楚:
· MMPose 代码运行的参数含义和逻辑
· 数据处理流程和封装逻辑
· 模型导出和部署验证
· MMPose 推理阶段的数据处理流程
在后续的笔记中我会继续以这样一种学习计划的形式层层递进,这些计划是我在学习之前列出的,因此可能有一些计划是在学习之后发现不必自己实现的,但我依然这样列出来,记录自己的整个思维过程。
预训模型推理✦
在 fork+clone 到本地后,我打开了 MMPose 的文档,进行最简单的预训练模型推理实验。
文档地址如下:
https://mmpose.readthedocs.io/zh_CN/latest/demo.html
通过目录可以看到,MMPose 对于市面上大部分的关键点人物数据集都有支持,并编写了对应的 demo 示例,我在简单浏览后选择测试在 onehand10k 数据集上预训练的,基于 deeppose 方法的 res50 模型。
所谓 deeppose 方法其实就是最原始的 Regression-based 方法,即直接用全连接层回归得到关键点坐标值。
我注意到 MMPose 对于 3D Hand 数据集并没有 Regression-based 方法支持,这将是我之后会尝试添加的内容(挖坑待填)。
来到 Model Zoo 页面,下载我所需要的 deeppose_resnet_50 模型的 ckpt 文件,我在 MMPose 本地目录中创建了一个 models 目录用于存放预训练模型。
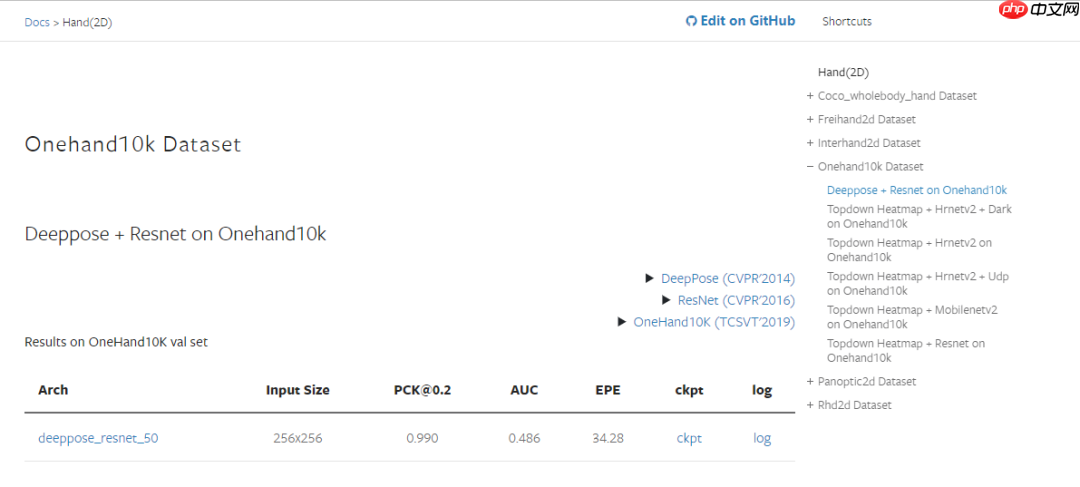
随后找到示例页面 2D Hand Image Demo,发现推理 demo 给了两个版本,分别是直接推理和带检测器的推理,出于简便考虑,我尝试了带检测器的版本,因此额外安装了 MMDetection 库,目前 MMPose 和 MMDetection 都对 Windows 进行了支持,可以很容易地通过 pip 进行安装:
pip install mmdet
带检测器的 demo 说明上也给出了 det model 的参数下载界面:
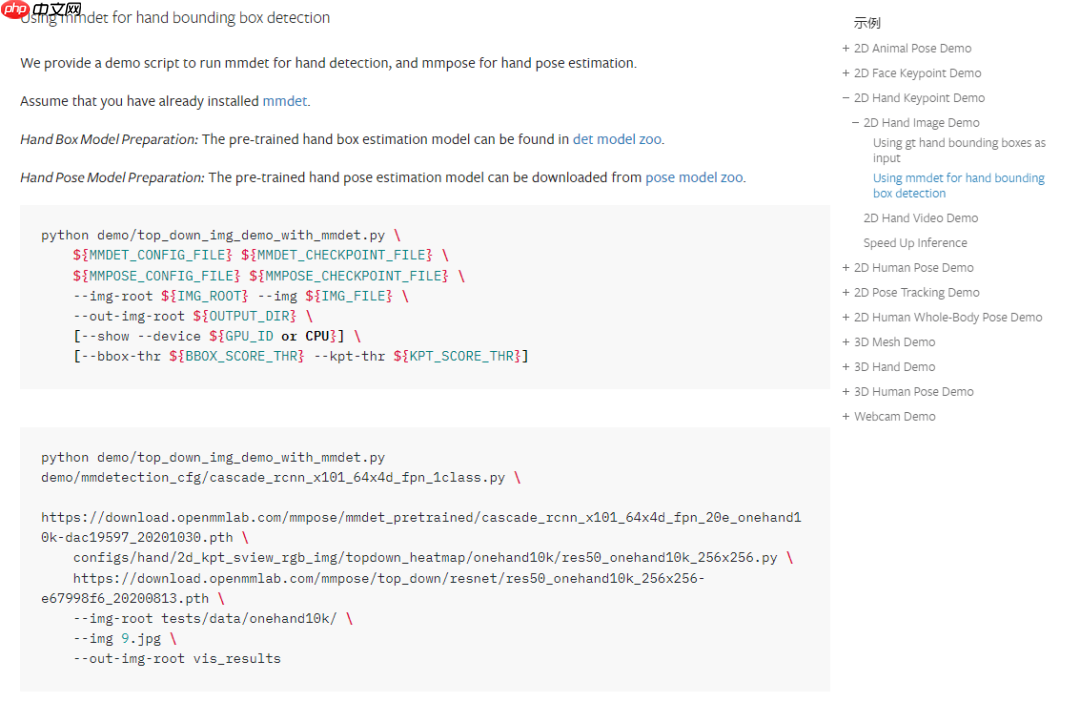
将检测器所需要的 cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth 文件也放到 models 目录下后,终于可以正式进行推理了。
可以看到运行代码样例给得非常完整,并且 demo 支持本地文件和远程下载两种方式获取模型权重,由于我已经下载到本地了,因此只需要对参数进行稍微的修改:
python demo/top_down_img_demo_with_mmdet.py \
demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \
models/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \
configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/res50_onehand10k_256x256.py \
models/deeppose_res50_onehand10k_256x256-cbddf43a_20210330.pth \
--img-root tests/data/onehand10k/ \
--img 9.jpg \
--out-img-root vis_results
运行结果保存到了自动新建的 vis_results 目录下:
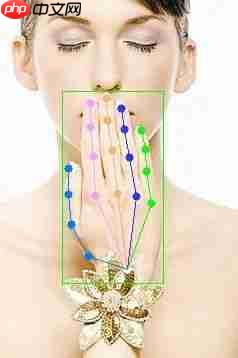
看来结果还是不错的,但这毕竟是 onehand10k 数据集有的图片,而且作为 demo 样例效果好是很正常的,于是我又自己找了一张图片进行测试:

果然对于真实场景下的图片表现就不那么让人满意了,可以看到大拇指指尖的位置明显错了,不过这是在意料之中的,只使用 onehand10k 一个数据集训练得到的模型在这种业务数据上表现不佳很正常。
此时我突然灵光一闪,Regression-based 方法表现不佳,那么 Heatmap-based 方法训练出来的模型是否泛化性能会更好呢?毕竟直接监督高斯热图的方式,按理来说对于局部特征的捕捉泛化能力是会强于回归方法的,所以我又实验了 Topdown Heatmap + Resnet50 模型。
从 Model Zoo 的结果上显示,Heatmap 训练的 Resnet50 模型 AUC 达到了 0.555,而回归方法训练的 AUC 只有 0.486,高斯热图果然名不虚传,那么实际表现怎么样呢:
python demo/top_down_img_demo_with_mmdet.py \
demo/mmdetection_cfg/cascade_rcnn_x101_64x4d_fpn_1class.py \
models/cascade_rcnn_x101_64x4d_fpn_20e_onehand10k-dac19597_20201030.pth \
configs/hand/2d_kpt_sview_rgb_img/topdown_heatmap/onehand10k/res50_onehand10k_256x256.py \ https://download.openmmlab.com/mmpose/top_down/resnet/res50_onehand10k_256x256-e67998f6_20200813.pth \
--img-root tests/data/cchand/ \
--img test.jpg \
--out-img-root vis_results

很容易看出,出来的结果更烂(狗头),我真不是故意要黑它的,图片我都是随机选的(摊手)。
但分析一下这结果其实也不意外,这张图片中手指根部受到了遮挡,对于 Heatmap-based 方法而言,如果训练时没有加入 AID 之类的随机擦除数据增强,对于遮挡的鲁棒性其实是不如 Regression-based 方法的,毕竟回归方法连超出 bbox 以外的关键点都能直接回归出来。
本地摄像头实时推理✦
使用本地摄像头进行模型推理来感受模型性能是非常直观的,在进一步查看了说明文档后,我了解到 MMPose 已经提供了这样的脚本,并且还提供了两个版本:一旧一新。
旧版本的脚本是:/demo/webcam_demo.py
这个脚本提供了包括身体、面部、手部,甚至动物姿态在内的全部内容,通过命令行参数的形式进行各个模块的开关,缺乏使用文档说明,在后续被 MMPose Webcam API 所替代。
新版本的脚本在 /tools/webcam 下,有专门的文档进行使用说明。
按照说明把
/tools/webcam/configs/examples/pose_estimation.py 中,DetectorNode 和 PoseEstimatorNode的model_config和model_checkpoint 改为了我所使用的手部检测的模型,再把 clas_names 改为 ['hand'] 后,就可以运行了:
python tools/webcam/run_webcam.py --config
tools/webcam/configs/examples/pose_estimation.py
说巧不巧的是,不知道是不是因为 Webcam API 是新推出的脚本,代码还不够完善,第一次尝试我就发现了一个 MMPose 的代码 bug:
File"E:\project\mmpose\tools\webcam\webcam_apis\nodes\mmdet_node.py", line 52
, in process
det_result = self._post_process(preds)
File"E:\project\mmpose\tools\webcam\webcam_apis\nodes\mmdet_node.py", line 65
, in _post_process
assert len(dets) == len(self.model.CLASSES)
AssertionError
一番检查之后发现错误是因为 MMDeteciton 预训练参数中保存的 CLASSES 字段是一个 string,
'hand'
而这里脚本中需要的是一个 tuple。
('hand', )
但毕竟刚接触 MMPose,我不确定是不是自己哪里弄错了,先提了一个 issue 询问,很快就得到了回复,并与维护者交流了一下修改方案,在他的帮助下对代码逻辑有了更清晰的了解,在我的方案得到认可后提交了我的 PR。
想不到这么快就实现了给 MMPose 提 PR 的小目标,有点意外,但也让我有了更多成为 contributor 的信心,MM 系列虽然名声在外,但其中仍然存在很多我们可以贡献一份力量的地方。
假如各位小伙伴在看到这篇笔记时,运行的这个 demo 脚本,其中就已经有我 PR 的代码了。
相比于旧版的 demo/webcam_demo.py 而言,新版的摄像头推理 demo 还是要强大和方便不少的。MMPose 提供的 Webcam API 中集成了检测、姿态估计,通过底层代码的阅读我发现还做了多线程优化来提升推理效率,感觉基于这套工具开发一些简单的摄像头应用应该会很方便。
在文档里还给出了几个应用开发的示例,有兴趣的小伙伴也可以去玩一下:
mmpose/example_cn.md at d66c4445c979e24685153c1cf73f2f3bb905279f · open-mmlab/mmpose (github.com)github.com/open-mmlab/mmpose/blob/d66c4445c979e24685153c1cf73f2f3bb905279f/tools/webcam/docs/exa
导出 ONNX 转 MNN✦
目前的部署框架大都需要把 pytorch 训练的模型先转成 ONNX,这个过程中常常因为各种代码或算子的实现存在问题而无法部署,因此在开始学习之初,验证 MMPose->ONNX->MNN 这一流程的通畅是很有必要的。
我跟随官方教程导出 onnx 模型:
python tools/deployment/pytorch2onnx.py \
configs/hand/2d_kpt_sview_rgb_img/deeppose/onehand10k/res50_onehand10k_256x256.py \
https://download.openmmlab.com/mmpose/hand/deeppose/deeppose_res50_onehand10k_256x256-cbddf43a_20210330.pth \
--shape 1 3 256 256
得到 tmp.onnx 模型后习惯性地用 onnxsimpler 进行了简化:
python -m onnxsim tmp.onnx tmp-sim.onnx
对比之后可以发现,对于 MMPose 转换出来的模型,onnxsimpler 还是可以起到优化作用的。
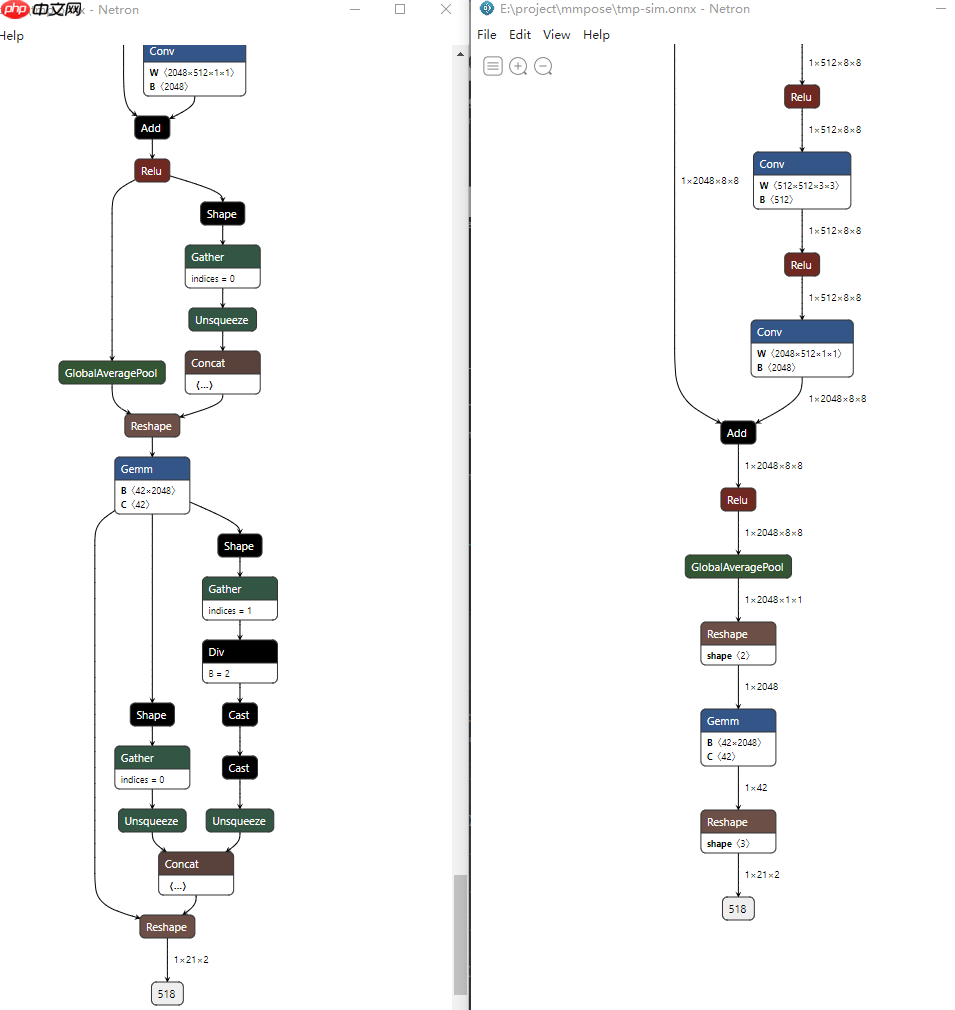
之后转 MNN 也没有遇到任何问题:
python -m MNN.tools.mnnconvert -f ONNX --modelFile tmp-sim.onnx --MNNModel model.mnn --fp16 --bizCode mnn
随后我写了一个简单的 python 端的 MNN 推理代码来验证模型结果:
代码语言:javascript代码运行次数:0运行复制class Hand(): def __init__(self, model_path, joint_num=21, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]): self.model_path = model_path self.joint_num = joint_num self.mean = np.array(mean).reshape(1, -1, 1, 1) self.std = np.array(std).reshape(1, -1, 1, 1) self.interpreter = MNN.Interpreter(model_path) self.model_sess = self.interpreter.createSession({ 'numThread': 1 }) def preprocess(self, img): input_shape = img.shape assert len(input_shape) == 4, 'expect shape like (1, C, H, W)' img = (np.transpose(img, (0, 3, 1, 2)) / 255. - self.mean) / self.std return img.astype(np.float32) def inference(self, img): input_shape = img.shape assert len(input_shape) == 4, 'expect shape like (1, C, H, W)' input_tensor = self.interpreter.getSessionInput(self.model_sess) tmp_input = MNN.Tensor(input_shape, MNN.Halide_Type_Float, img.astype(np.float32), MNN.Tensor_DimensionType_Caffe) input_tensor.copyFrom(tmp_input) self.interpreter.runSession(self.model_sess) output_tensor = self.interpreter.getSessionOutputAll(self.model_sess) joint_coord = np.array(output_tensor['518'].getData()) return joint_coord def predict(self, img): img = self.preprocess(img) joint_coord = self.inference(img) return joint_coord实验后发现,导出的 MNN 模型推理的结果跟 MMPose 提供的 inference_top_down_pose_model() 方法出来的结果完全对不上,MNN 得到的结果全是小数,于是我很快意识到模型输出的结果应该是归一化过的,MMPose 提供的推理方法中应该还包含了预处理和后处理代码。
顺着 inference_top_down_pose_model() 一路走下去,可以发现 MMPose 会先基于 bbox 和 image_size 对坐标进行归一化,计算出 scale 和 center 参数用于后处理时计算原图坐标:
代码语言:javascript代码运行次数:0运行复制# mmpose/apis/inference.py batch_data = [] for bbox in bboxes: center, scale = _box2cs(cfg, bbox) # prepare data data = { 'center': center, 'scale': scale, 'bbox_score': bbox[4] if len(bbox) == 5 else 1, 'bbox_id': 0, # need to be assigned if batch_size > 1 'dataset': dataset_name, 'joints_3d': np.zeros((cfg.data_cfg.num_joints, 3), dtype=np.float32), 'joints_3d_visible': np.zeros((cfg.data_cfg.num_joints, 3), dtype=np.float32), 'rotation': 0, 'ann_info': { 'image_size': np.array(cfg.data_cfg['image_size']), 'num_joints': cfg.data_cfg['num_joints'], 'flip_pairs': flip_pairs } } if isinstance(img_or_path, np.ndarray): data['img'] = img_or_path else: data['image_file'] = img_or_path data = test_pipeline(data) batch_data.append(data) batch_data = collate(batch_data, samples_per_gpu=len(batch_data)) batch_data = scatter(batch_data, [device])[0] # forward the model with torch.no_grad(): result = model( img=batch_data['img'], img_metas=batch_data['img_metas'], return_loss=False, return_heatmap=return_heatmap) return result['preds'], result['output_heatmap']可以注意到的是,模型推理时除了图片以外,还传入了数据信息以及是否计算 loss 和返回 heatmap 的参数,这些都是在自己进行模型推理时需要注意的。
接下来进入模型的推理代码:
找到 /mmpose/models/detectors/ 下的 top_down.py
代码语言:javascript代码运行次数:0运行复制# /mmpose/models/detectors/top_down.py@auto_fp16(apply_to=('img', ))def forward(self, img, target=None, target_weight=None, img_metas=None, return_loss=True, return_heatmap=False, **kwargs): if return_loss: return self.forward_train(img, target, target_weight, img_metas, **kwargs) return self.forward_test( img, img_metas, return_heatmap=return_heatmap, **kwargs)可以看到是否打开 return_loss 开关是会影响推理流程的,并且默认的参数是 True,因此在手动进行 torch 推理时需要关掉它。
代码语言:javascript代码运行次数:0运行复制# /mmpose/models/detectors/top_down.pydef forward_test(self, img, img_metas, return_heatmap=False, **kwargs): """Defines the computation performed at every call when testing.""" assert img.size(0) == len(img_metas) batch_size, _, img_height, img_width = img.shape if batch_size > 1: assert 'bbox_id' in img_metas[0] result = {} features = self.backbone(img) if self.with_neck: features = self.neck(features) if self.with_keypoint: output_heatmap = self.keypoint_head.inference_model( features, flip_pairs=None) if self.test_cfg.get('flip_test', True): img_flipped = img.flip(3) features_flipped = self.backbone(img_flipped) if self.with_neck: features_flipped = self.neck(features_flipped) if self.with_keypoint: output_flipped_heatmap = self.keypoint_head.inference_model( features_flipped, img_metas[0]['flip_pairs']) output_heatmap = (output_heatmap + output_flipped_heatmap) * 0.5 if self.with_keypoint: keypoint_result = self.keypoint_head.decode( img_metas, output_heatmap, img_size=[img_width, img_height]) result.update(keypoint_result) if not return_heatmap: output_heatmap = None result['output_heatmap'] = output_heatmap return result从 forward_test() 中就可以清晰看出,模型的输出会在 keypoint_head 定义的 decode() 进行后处理,将模型输出的结果还原为原图坐标,而这部分想必是不会写进模型里的,毕竟我们知道 heatmap-based 方法中常用的后处理都是不可导的。
找到 decode() 验证一下我们的想法:
代码语言:javascript代码运行次数:0运行复制# /mmpose/models/heads/deeppose_regression_head.pydef decode(self, img_metas, output, **kwargs): batch_size = len(img_metas) if 'bbox_id' in img_metas[0]: bbox_ids = [] else: bbox_ids = None c = np.zeros((batch_size, 2), dtype=np.float32) s = np.zeros((batch_size, 2), dtype=np.float32) image_paths = [] score = np.ones(batch_size) for i in range(batch_size): c[i, :] = img_metas[i]['center'] s[i, :] = img_metas[i]['scale'] image_paths.append(img_metas[i]['image_file']) if 'bbox_score' in img_metas[i]: score[i] = np.array(img_metas[i]['bbox_score']).reshape(-1) if bbox_ids is not None: bbox_ids.append(img_metas[i]['bbox_id']) preds, maxvals = keypoints_from_regression(output, c, s, kwargs['img_size']) all_preds = np.zeros((batch_size, preds.shape[1], 3), dtype=np.float32) all_boxes = np.zeros((batch_size, 6), dtype=np.float32) all_preds[:, :, 0:2] = preds[:, :, 0:2] all_preds[:, :, 2:3] = maxvals all_boxes[:, 0:2] = c[:, 0:2] all_boxes[:, 2:4] = s[:, 0:2] all_boxes[:, 4] = np.prod(s * 200.0, axis=1) all_boxes[:, 5] = score result = {} result['preds'] = all_preds result['boxes'] = all_boxes result['image_paths'] = image_paths result['bbox_ids'] = bbox_ids return result这里发现里面原来还封装了一层,模型输出的结果 output 还通过了一个 keypoints_from_regression() 来取得返回值,而这个返回值的命名 preds, maxvals 就非常眼熟了,常见的开源代码中无论是 DARK 还是别的 heatmap-based 工作,都会有这么一个函数来获取 heatmap 对应的坐标点。
代码语言:javascript代码运行次数:0运行复制# /mmpose/core/evaluation/top_down_eval.pydef keypoints_from_regression(regression_preds, center, scale, img_size): N, K, _ = regression_preds.shape preds, maxvals = regression_preds, np.ones((N, K, 1), dtype=np.float32) preds = preds * img_size # Transform back to the image for i in range(N): preds[i] = transform_preds(preds[i], center[i], scale[i], img_size) return preds, maxvals# /mmpose/core/post_processing/post_transforms.pydef transform_preds(coords, center, scale, output_size, use_udp=False): assert coords.shape[1] in (2, 4, 5) assert len(center) == 2 assert len(scale) == 2 assert len(output_size) == 2 # Recover the scale which is normalized by a factor of 200. scale = scale * 200.0 if use_udp: scale_x = scale[0] / (output_size[0] - 1.0) scale_y = scale[1] / (output_size[1] - 1.0) else: scale_x = scale[0] / output_size[0] scale_y = scale[1] / output_size[1] target_coords = np.ones_like(coords) target_coords[:, 0] = coords[:, 0] * scale_x + center[0] - scale[0] * 0.5 target_coords[:, 1] = coords[:, 1] * scale_y + center[1] - scale[1] * 0.5 return target_coords
再又经过了两层封装后我才终于见到了最底层的后处理逻辑,即利用预处理时计算得到的 bbox 的 center 和 scale 将模型的结果还原为原图坐标。
弄清楚所有处理流程后,我给 MNN 推理代码增加了一段后处理:
代码语言:javascript代码运行次数:0运行复制# 加到Hand()里def post_process(self, coords, bbox): w = bbox[2] - bbox[0] h = bbox[3] - bbox[1] target_coords = coords * np.array([w, h]) target_coords += np.array([bbox[0], bbox[1]]) return target_coords
最终推理结果对比,精度损失还是有的,不过还能接受,平均每个点的偏移误差在 4 个像素左右。
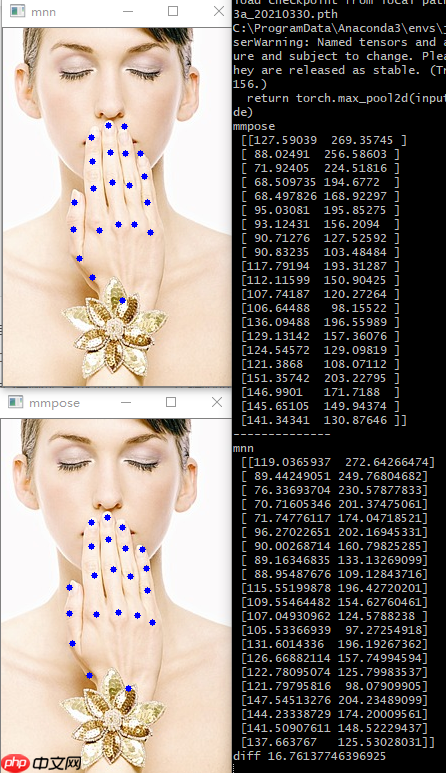
结语✦
作为第一次接触和学习 MMPose 的记录,这个过程比我想象中要长,也遇到了不少曲折,好在最终一一进行了解决。接下来我会学习 MMPose 的训练、自定义数据、加入新模块,也会对 MMPose 的封装逻辑进行总结。
以上就是一学就会!快来查收这份 MMPose 学习指南的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 819
819

























