
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

“四年前刚开始创业时,我经常被问到一个问题:既然存算一体这么有前景,为什么别人不做?”后摩智能创始人兼CEO吴强回忆道,“现在情况完全不同了,不少上市公司甚至准备上市的企业都在宣布布局存算一体,没人再质疑它的价值。大家已经意识到,这种架构在支撑大模型方面具备天然优势。”
近年来,存算一体芯片领域热度持续攀升,国内已有十余家企业投身其中,探索不同技术路径与算力层级的解决方案。
那么,后摩智能的核心竞争力究竟在哪?吴强的回答很直接:“从论文出发做出一块验证性芯片,证明原理可行并不难。真正的挑战在于实现量产。过去四年,我们踩过无数坑,攻克了一个又一个工程化难题——这才是我们的真正壁垒。”
在世界人工智能大会2025(WAIC)前夕,后摩智能正式发布了即将于今年第四季度量产的端侧与边缘端大模型AI芯片——后摩漫界M50。这款基于存算一体架构的单芯片,能够本地运行百亿参数级别大模型,标志着国产AI芯片在能效与算力融合上的新突破。
吴强还透露,公司已启动下一代DRAM-PIM技术的研发布局。
率先出发,果断转型,构建真实护城河
2020年吴强创立后摩智能时,选择存算一体路线源于两个深层动因:其一是他的博士研究方向正是高能效计算芯片与编译器优化,致力于破解“功耗墙”和“存储墙”难题,而存算一体是唯一可行的技术路径;其二则是看到英伟达在传统架构下的统治地位,决心以创新架构实现弯道超车。
尽管学术界对存算一体已有多年研究,但将实验室成果转化为可量产、可商用的产品,中间存在巨大断层。
“论文可以展示理论可行性,但要走向量产,必须解决可靠性、可测性等一系列工程问题。”吴强坦言,“当时根本没有针对存算一体的DFT(可测性设计)方案,也没有成熟的BIST(内建自测试)方法。小面积下如何保证电源稳定?大算力如何不烧芯片?这些问题都没有现成答案。”
更严峻的是,产业链尚不成熟——既缺乏适配的制造工艺,也缺少专用的EDA工具。后摩团队只能在通用工艺和现有工具基础上,自行填补技术空白。
“我们非常欢迎更多同行加入,共同把存算一体的生态做起来。”吴强表示。
正是凭借团队一步步攻坚,2023年后摩推出了国内首款大算力存算一体智驾芯片鸿途H30,最高物理算力达256TOPS,典型功耗仅为35W。
此后虽有融资消息传出,但产品落地进展一度沉寂,直到2025年7月WAIC前夕才再度引发关注。

对此,吴强向PHP中文网(公众号:PHP中文网)解释,2023年下半年自动驾驶赛道竞争白热化,市场格局趋于固化,新进入者机会渺茫。
“我们的第一代芯片为了突出存算优势,追求高算力,成本也相应较高。但当时整车厂普遍强调低成本方案,导致我们的产品与市场需求出现错配。”吴强坦承,“那段时间我们很纠结,是否要放弃汽车赛道?转型非常痛苦,但我们清楚地知道,这条路走不通。”
“最终,生存压力战胜了执念。2023年下半年,我们决定转向。”他说,“我们发现了端边大模型这一新兴市场——这里没有巨头垄断,且对高能效、低功耗的AI芯片需求强烈,恰好契合存算一体的优势。”
2024年初,后摩迅速调整第一代芯片设计,针对大模型推理优化,推出漫界M30。在中国移动的支持下,该芯片亮相2024年世界移动通信大会(MWC),成功运行60B参数模型,极大增强了团队信心。
此后,后摩坚定聚焦端边大模型芯片赛道,历时近两年打磨,推出基于第二代IPU架构的量产芯片——漫界M50。

无论是将存算一体从学术推向产业,还是在应用场景选择上的试错与调整,这些经历积累下来的实战经验,构成了后摩在激烈竞争中难以复制的壁垒。

这份壁垒,也成为后摩设计第二代芯片的重要支撑。
单芯片160TOPS,本地运行百亿参数不再是梦
后摩漫界M50采用自研第二代IPU架构“天璇”,实现160TOPS@INT8、100TFLOPS@bFP16的物理算力,配备最大48GB内存和高达153.6GB/s的带宽,典型功耗仅10W——相当于一部手机快充的功率,即可驱动PC、智能语音设备、机器人等终端高效运行1.5B至70B参数的本地大模型。
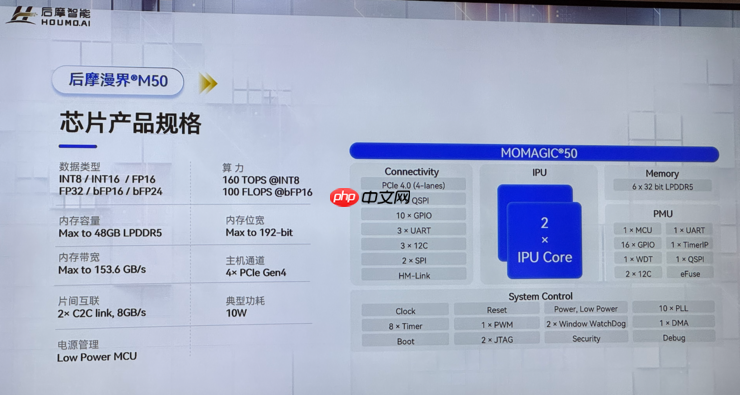
得益于存算一体将计算与存储单元深度融合、就近处理数据的特性,M50从根本上缓解了传统架构中“数据搬运慢、能耗高”的瓶颈。相比传统方案,能效提升可达5~10倍,完美契合端边设备“算得快、吃得少”的核心诉求。
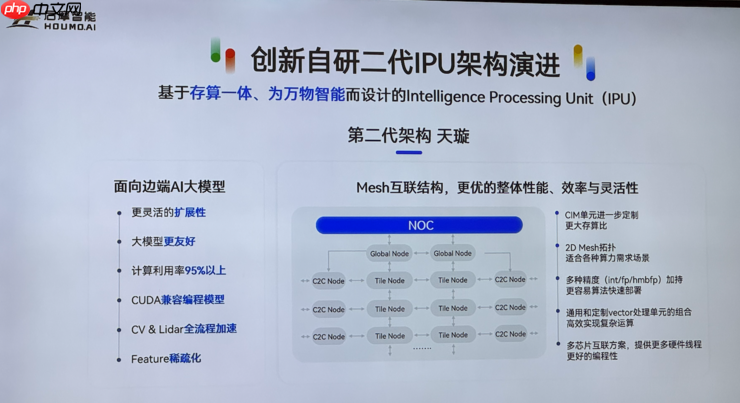
为充分发挥架构优势以高效支撑大模型运行,后摩智能在软硬件层面进行了多项关键优化。吴强重点介绍了两项核心技术。
其一是“弹性加速”技术,类似GPU的稀疏加速,但更具灵活性。GPU通常只在权重为严格“0”时跳过计算,现实中难以大规模触发。而SRAM存算一体采用逐比特串行计算方式,使得后摩可以在更细粒度上识别无效计算。
“我们不需要整个权重为零,只要某个bit为0,就可能实现加速。”吴强解释道,这大幅提升了加速机会,也让量化更加灵活,支持7bit、6bit甚至5bit的超低精度压缩,在几乎不损失精度的前提下,将性能压榨至极限。
据披露,天璇架构最高可实现160%的加速增益。

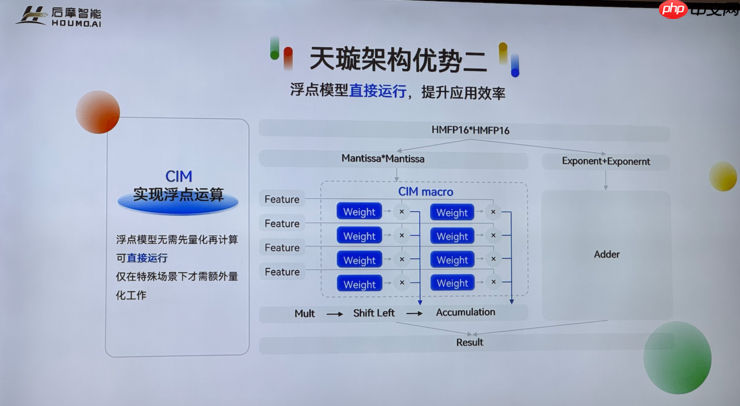
另一项突破是直接支持浮点运算。“基于存算架构实现浮点计算并成功量产,我们在业内应该是首家。”吴强强调,芯片原生支持浮点意味着开源模型或FP16格式的大模型可直接部署,无需额外量化转换,显著提升适配效率。仅在特殊场景下才需进行精度调整,极大降低了应用门槛。
对用户而言,易用性最终体现在上层软件体验,尤其是编译器。
“第一代编译器我们沿用传统方案,很多潜力无法释放,后来彻底推倒重来,从零构建。”吴强说,“这个过程完全是自主摸索,外界看不到,正是我们积累的独特壁垒。”
传统N
以上就是热闹的存算一体芯片赛道里,后摩的竞争壁垒是什么? |WAIC 2025的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 413
413
























