MiDashengLM是什么
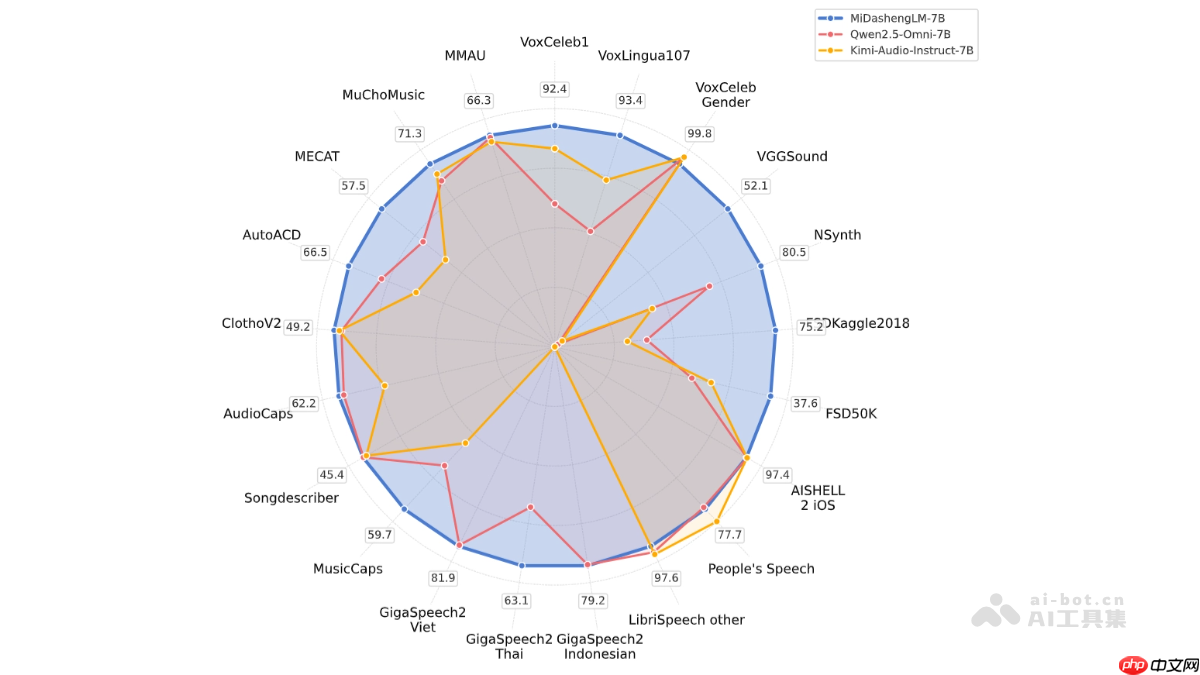
midashenglm是小米推出的高效音频理解大模型,具体型号为midashenglm-7b。该模型融合了xiaomi dasheng音频编码器与qwen2.5-omni-7b thinker解码器,采用通用音频描述对齐方法,实现对语音、环境音及音乐的统一语义理解。具备卓越的性能表现和极高的推理效率,首token延迟仅为当前主流先进模型的1/4,同时支持大规模并行处理。其训练数据全部开源,兼容学术研究与商业应用,广泛适用于智能座舱、智能家居等场景,助力多模态人机交互体验的全面升级。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
MiDashengLM的主要功能
-
音频描述(Audio Captioning):将各类音频内容(如人声、背景音、音乐等)转化为自然语言文本,帮助用户快速掌握音频核心信息。
-
音频分类(Audio Classification):精准识别音频类型(如语音、环境声、音乐等),可用于环境监测、声音分类等实际应用。
-
语音识别(Automatic Speech Recognition, ASR):将口语内容准确转录为文字,支持多语种识别,广泛应用于语音助手、车载系统等场景。
-
音频问答(Audio Question Answering):根据输入音频回答用户提出的问题,适用于座舱内环境音识别问答、音乐信息查询等任务。
-
多模态交互(Multimodal Interaction):融合音频与文本、图像等多种模态信息,提升智能设备的整体感知与交互能力。
MiDashengLM的技术原理
-
模型架构:
-
音频编码器:采用Xiaomi Dasheng音频编码器,将原始音频信号转化为高维语义特征。该编码器在非语音音频(如环境声和音乐)的理解上表现优异,能够捕捉深层次的声音语义。
-
解码器:基于Qwen2.5-Omni-7B Thinker自回归解码结构,将编码后的特征解码为连贯自然语言输出,支持多种下游任务,包括描述生成、问答和语音转写等。
-
训练策略:
-
通用音频描述对齐:摒弃传统ASR转录方式,采用非单调的全局语义映射机制,通过统一的描述性文本对齐音频内容,促使模型学习跨类型声音的深层语义关联。
-
多专家标注体系:利用多专家分析流程生成高质量训练数据,涵盖语音、人声、音乐与环境声的细粒度标签,并借助DeepSeek-R1大模型合成统一描述文本。
-
训练数据集:使用完全开源的海量音频数据进行训练,总时长超100万小时,覆盖多种音频类型。原始标签在预训练阶段被舍弃,仅保留丰富的人工合成文本描述,推动模型学习更全面的声音语义。
-
推理效率优化:
-
高效特征输出:优化编码器设计,将输出帧率由Qwen2.5-Omni的25Hz大幅降低至5Hz,显著减少计算开销,提升响应速度。
-
高吞吐并行处理:支持高达batch size=512的大批量推理,在80GB GPU上处理30秒音频并生成100个token时,吞吐量超过Qwen2.5-Omni-7B的20倍。
MiDashengLM的项目地址
MiDashengLM的应用场景
-
智能座舱:结合语音交互与环境音识别,增强驾驶过程中的安全性与智能化交互体验。
-
智能家居:通过语音指令控制家电,实时监测环境声音(如婴儿哭声、玻璃破碎声),实现自动化响应。
-
语音助手:提供高精度、多语言的语音识别与语义理解能力,满足多样化用户需求。
-
音频内容创作与标注:自动为音频生成描述性文字和标签,提升音视频内容制作与管理效率。
-
教育辅助:支持语言学习中的发音评估与音乐教学中的理论指导,提供个性化学习反馈。
以上就是MiDashengLM— 小米开源的高效声音理解大模型的详细内容,更多请关注php中文网其它相关文章!


 广告
广告








 299
299






















