NVIDIA Nemotron Nano 2是什么
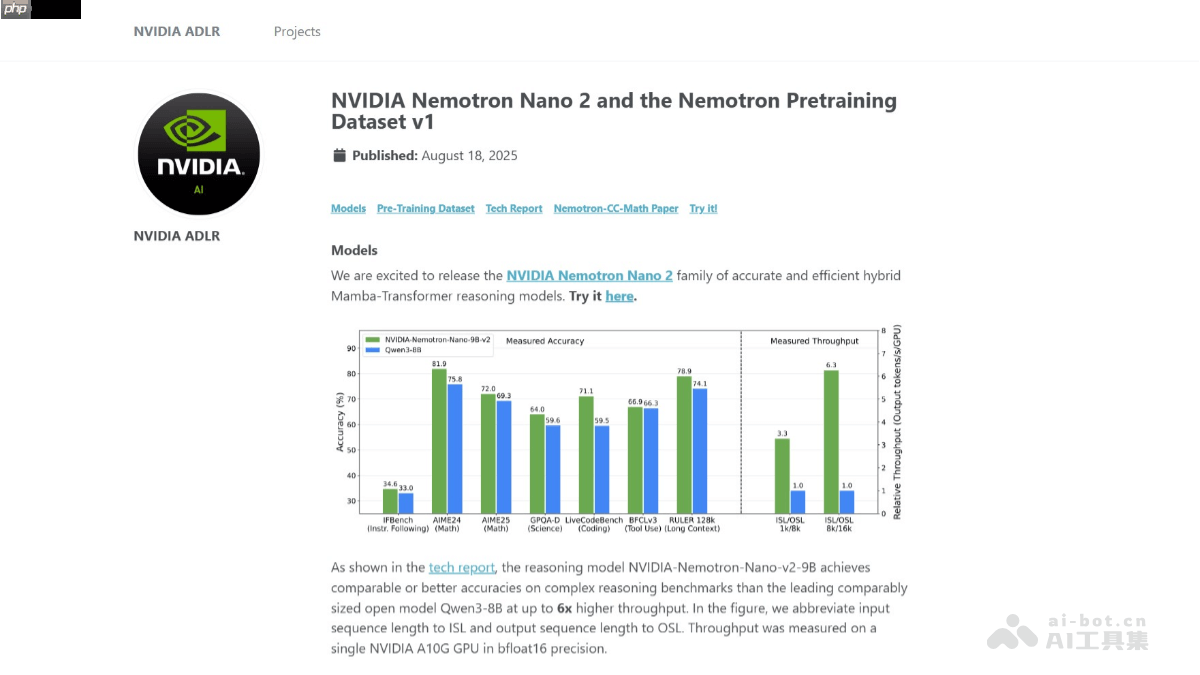
nvidia nemotron nano 2 是英伟达发布的一款高效能推理专用模型,参数规模为9b。该模型采用创新的混合mamba-transformer架构,经过20万亿token的大规模预训练,支持高达128k的上下文长度。在性能方面,相较qwen3-8b模型,其推理速度最高可提升6倍,同时保持相当甚至更优的准确率。模型引入“思考预算”控制机制,允许用户设定推理过程中使用的token数量,灵活平衡效率与精度。英伟达已开源该模型的基础版本及大部分预训练数据集,旨在推动开发者在推理模型领域的深入研究与实际应用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
NVIDIA Nemotron Nano 2的主要功能
-
超高吞吐性能:在处理复杂推理任务时,吞吐量可达Qwen3-8B的6倍,显著提升响应效率。
-
超长上下文支持:支持128k长度的输入上下文,可在单张NVIDIA A10G GPU上完成推理,适用于长文档分析与复杂逻辑任务。
-
可解释性推理路径:模型在输出最终结果前会生成中间推理过程(reasoning trace),增强结果透明度。
-
动态推理控制:用户可自定义“思考”预算,控制模型推理深度,并选择是否跳过中间步骤直接获取答案。
-
多语言理解能力:预训练数据涵盖多种语言,具备出色的跨语言推理与理解能力。
-
广泛领域覆盖:训练数据涉及数学、编程、学术写作、STEM等领域,适用于多样化专业场景。
NVIDIA Nemotron Nano 2的技术原理
-
混合Mamba-Transformer架构:采用Mamba-2结构替代传统Transformer中的多数自注意力层,大幅提升长序列生成效率;同时保留部分Transformer层以维持模型表达能力与精度。
-
大规模预训练:基于20万亿token进行训练,使用FP8精度和Warmup-Stable-Decay学习率策略。通过持续的长上下文扩展训练,实现128k上下文支持而不影响其他任务表现。
-
后训练优化流程:包括监督微调(SFT)提升任务表现;策略优化增强指令遵循能力;结合人类反馈的强化学习(RLHF)优化对话质量与偏好对齐。
-
模型压缩技术:利用剪枝与知识蒸馏方法,将原始12B参数模型压缩至9B,保持性能的同时降低部署门槛,支持在单个A10G GPU上运行128k上下文推理。
-
推理预算机制:通过截断式训练实现动态推理控制,用户可指定最大推理步数,避免资源浪费,灵活适配不同应用场景。
NVIDIA Nemotron Nano 2的项目地址
NVIDIA Nemotron Nano 2的应用场景
-
教育辅助:帮助学生拆解数学与科学难题,通过逐步推理讲解公式推导与物理原理,提升学习理解能力。
-
科研支持:协助研究人员生成详细的分析逻辑与推理报告,支持论文撰写、实验设计与数据解读。
-
代码生成:为开发者提供高质量代码建议,加速程序开发与调试过程。
-
编程教学:在编程教学中提供清晰的代码示例与逻辑解释,助力初学者掌握编程思维。
-
智能客服:作为多语言对话引擎,部署于客服系统,提供快速、精准的自动化客户响应服务。
以上就是NVIDIA Nemotron Nano 2— 英伟达推出的高效推理模型的详细内容,更多请关注php中文网其它相关文章!











 946
946























