








本文介绍了如何使用 Pandas 和 NumPy 结合,针对 DataFrame 中的分组数据,将组内每行特定的数据信息添加到该组的每一行中。通过 NumPy 的滚动索引技巧,高效地实现了数据的广播和扩展,避免了低效的循环操作,并提供了详细的代码示例和解释。
在数据分析中,经常会遇到需要在分组数据中进行行间操作的场景。例如,在赛马数据集中,我们可能需要将每匹马的信息添加到同一场比赛的其他马匹的信息中,以便进行更深入的比较和分析。本文将介绍如何使用 Pandas 和 NumPy 来高效地实现这一目标。
解决方案
核心思路是利用 NumPy 的滚动索引功能,避免显式循环,从而提升性能。具体步骤如下:
bee餐饮点餐外卖小程序
下载
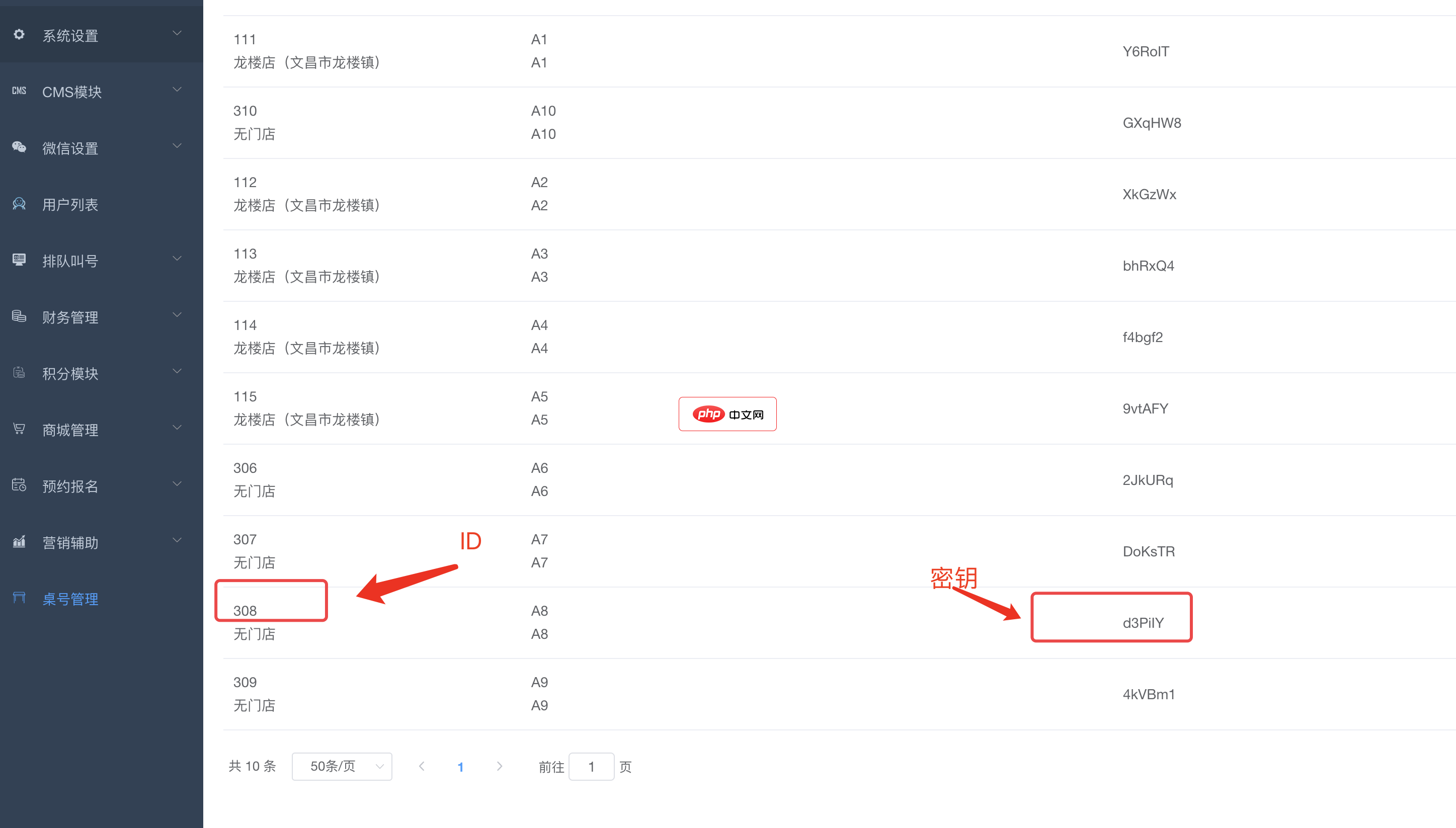
bee餐饮点餐外卖小程序是针对餐饮行业推出的一套完整的餐饮解决方案,实现了用户在线点餐下单、外卖、叫号排队、支付、配送等功能,完美的使餐饮行业更高效便捷!功能演示:1、桌号管理登录后台,左侧菜单 “桌号管理”,添加并管理你的桌号信息,添加以后在列表你将可以看到 ID 和 密钥,这两个数据用来生成桌子的二维码2、生成桌子二维码例如上面的ID为 308,密钥为 d3PiIY,那么现在去左侧菜单微信设置
- 定义滚动函数 roll(g): 该函数接收一个 DataFrame Group 作为输入,并使用 NumPy 的索引技巧来滚动和重塑数据。
- 将 DataFrame 转换为 NumPy 数组: g.to_numpy() 将 DataFrame Group 转换为 NumPy 数组,以便进行高效的数值操作。
- 创建索引数组: np.arange(len(a)) 创建一个索引数组,用于生成滚动索引。
- 生成滚动索引: ((x[:,None] + x)%len(a)).ravel() 使用 NumPy 的广播功能和模运算,生成滚动索引。这个表达式的核心在于 x[:,None] + x,它创建了一个二维数组,其中每一行都是 x 加上一个不同的偏移量。%len(a) 确保索引在数组长度范围内循环。ravel() 将二维数组扁平化为一维数组,用于索引。
- 使用滚动索引提取数据: a[((x[:,None] + x)%len(a)).ravel()] 使用生成的滚动索引从 NumPy 数组中提取数据。
- 重塑数据为 DataFrame: reshape(len(a), -1) 将提取的数据重塑为 DataFrame 的形状。
- 创建新的列名: [f'{c}_{i+1}' for i in x for c in g.columns] 为新的 DataFrame 创建列名,其中 c 是原始列名,i 是滚动索引。
- 分组并应用滚动函数: 使用 data_orig_df.groupby(cols).apply(lambda g: roll(g.drop(columns=cols))) 对 DataFrame 进行分组,并对每个组应用 roll 函数。cols 是用于分组的列名,例如 ['meetingId', 'raceId']。drop(columns=cols) 从 DataFrame Group 中删除分组列,以便 roll 函数只处理需要滚动的数据列。
- 重置索引: reset_index(cols) 将分组列重新添加到 DataFrame 中。
代码示例
import pandas as pd
import numpy as np
data_orig = {
'meetingId': [178515] * 6,
'raceId': [879507] * 6,
'horseId': [90001, 90002, 90003, 90004, 90005, 90006],
'position': [1, 2, 3, 4, 5, 6],
'weight': [51, 52, 53, 54, 55, 56],
}
data_orig_df = pd.DataFrame(data_orig)
def roll(g):
a = g.to_numpy()
x = np.arange(len(a))
return pd.DataFrame(a[((x[:,None] + x)%len(a)).ravel()].reshape(len(a), -1),
index=g.index,
columns=[f'{c}_{i+1}' for i in x for c in g.columns])
cols = ['meetingId', 'raceId']
out = (data_orig_df.groupby(cols)
.apply(lambda g: roll(g.drop(columns=cols)))
.reset_index(cols)
)
print(out)代码解释
- import pandas as pd: 导入 Pandas 库,用于数据处理。
- import numpy as np: 导入 NumPy 库,用于数值计算。
- data_orig: 包含原始数据的字典。
- data_orig_df = pd.DataFrame(data_orig): 将字典转换为 Pandas DataFrame。
- roll(g): 该函数是核心,它接收一个 DataFrame Group 作为输入,并使用 NumPy 的索引技巧来滚动和重塑数据。
- cols = ['meetingId', 'raceId']: 定义用于分组的列名。
- data_orig_df.groupby(cols): 根据 meetingId 和 raceId 列对 DataFrame 进行分组。
- .apply(lambda g: roll(g.drop(columns=cols))): 对每个组应用 roll 函数,并删除分组列。
- .reset_index(cols): 将分组列重新添加到 DataFrame 中。
- print(out): 打印结果 DataFrame。
注意事项
- 确保数据类型一致:在进行 NumPy 操作之前,确保 DataFrame 中的数据类型一致,避免出现类型错误。
- 处理大数据集:对于非常大的数据集,可以考虑使用更高效的 NumPy 函数或使用 Dask 等分布式计算框架。
- 内存占用:滚动操作可能会增加内存占用,需要根据数据集的大小进行调整。
总结
本文介绍了如何使用 Pandas 和 NumPy 结合,高效地将分组数据中每行的数据添加到该组的每一行中。通过 NumPy 的滚动索引技巧,避免了低效的循环操作,并提供了详细的代码示例和解释。掌握这种方法可以帮助你更高效地处理分组数据,进行更深入的数据分析。




























