
字节跳动数字人团队推出了 omnihuman-1.5。
作为其前身OmniHuman-1的升级版本,OmniHuman-1.5延续了其前身的核心技术,通过单张图像和音频生成生动的人物视频。相比上一代,OmniHuman-1.5在真实感和泛化能力上实现了显著提升。得益于字节跳动团队优化后的多模态运动条件混合训练策略,生成的视频在动作自然度、唇形同步以及情感表达上更加细腻逼真。无论是真人形象还是动漫角色,OmniHuman-1.5都能生成与音频内容高度匹配的动态效果,展现出极高的视觉质量。
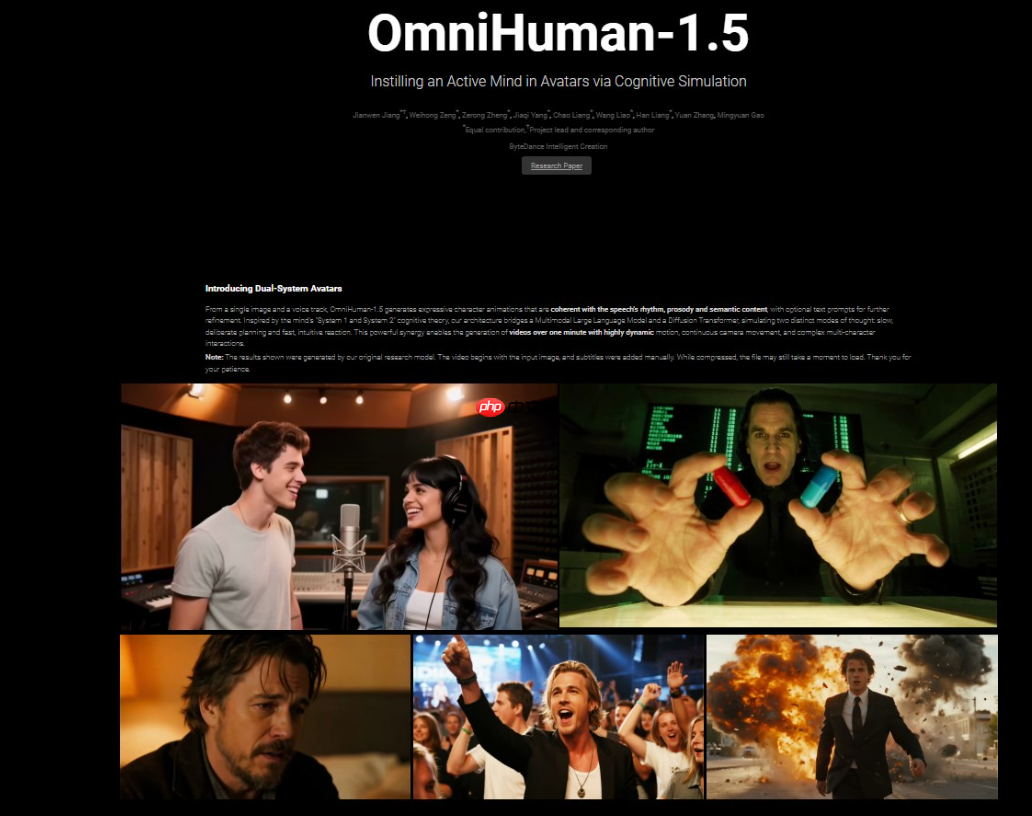
支持双人音频驱动是OmniHuman-1.5的一大亮点。传统AI视频生成技术多局限于单人场景,而OmniHuman-1.5首次实现了基于双人音频输入的视频生成,能够精准捕捉多角色间的交互动作与表情,为多人场景表演提供了技术支持。此外,该技术支持生成超过一分钟的视频,通过帧间连接策略确保长时间视频的连贯性和身份一致性,满足了更复杂的应用需求,如演讲视频、音乐MV等。
OmniHuman-1.5不仅局限于机械的动作生成,还能感知音频中的情感并通过视频表现出来。例如,根据音频的语调和情绪,系统可自动调整人物的面部表情和肢体动作,使视频更具感染力。同时,新增的文本提示词功能允许用户通过文字描述进一步定制视频内容,例如指定场景风格或动作细节,为创作者提供了更大的灵活性。
除了真人形象,OmniHuman-1.5在处理非真人形象(如动漫角色、3D卡通形象)方面表现尤为出色。系统能够保持不同艺术风格下动作的自然一致性,确保唇形和动作与音频完美同步。
在影视制作领域,它可用于角色动画和特效制作,快速生成与音频同步的虚拟演员视频;在虚拟主播与娱乐场景中,创作者可利用其生成生动的人物形象,增强直播互动性;在教育与培训中,OmniHuman-1.5能生成具有生动肢体语言的教学视频,提升内容的吸引力和易懂性;在广告与营销中,定制化的虚拟人物可助力品牌宣传,显著提升转化率。
尽管OmniHuman-1.5在技术上取得了重大突破,但仍面临一些挑战。例如,音频与动作之间的关联随机性可能导致部分动作不够自然,物体交互的真实性也需进一步优化。
此外,高计算资源需求可能限制其在普通设备上的普及。字节跳动团队表示,未来将通过引入更细粒度的动作控制、增强物理约束建模以及模型压缩等技术,进一步提升系统性能和用户体验。
以上就是字节 OmniHuman-1.5 发布,一张图+音频秒变超真实视频的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 569
569























