







训练大模型时,适度“健忘”反而更聪明!
大语言模型若缺乏约束,容易直接照搬训练数据。为应对这一挑战,马里兰大学、图宾根大学与马普所的研究团队提出了一种新颖方法——金鱼损失(Goldfish Loss)。

顾名思义,金鱼损失旨在让模型像金鱼一样“记性差”,在计算损失函数时随机忽略一小部分 token。
这样一来,模型不再逐字记忆训练内容,但仍能掌握语言结构和规律。
实验结果显示,在应用金鱼损失后,LLaMA-2 模型:
显著减少记忆化行为:几乎不再复现原始训练文本
保持下游任务表现:文本生成依旧流畅自然
正如网友一针见血地评论:这就像 dropout,只不过作用在损失函数上!

在梯度更新过程中随机屏蔽部分 token
金鱼损失的核心思想十分直观:在训练阶段,随机剔除输入序列中的一些 tokens,使其不参与损失计算。
这样,当模型在推理时面对被“遗忘”的位置,只能依靠上下文进行推测,而非机械复述训练数据。
为了确保每次遇到相同文本时,被屏蔽的位置保持一致,研究者设计了一种基于哈希(hashing)的掩码机制。

那么,它与传统的正则化手段有何不同?
以 Dropout 为例,这类方法通过在神经网络中引入噪声,防止模型对特定参数过度依赖,从而提升泛化能力。
但问题在于:如果每次训练时随机丢弃的 token 位置不同,模型可能通过多次观察拼凑出完整句子,本质上仍是“死记硬背”。
而金鱼损失采用哈希控制的固定掩码模式,保证同一段落每次出现时被屏蔽的位置一致,从根本上阻断模型完整记忆的可能性。
接下来,我们看看金鱼损失的具体实现方式。
在标准的 next-token prediction 训练中,模型以真实下一个 token 为目标输出预测分布,并据此计算交叉熵损失。
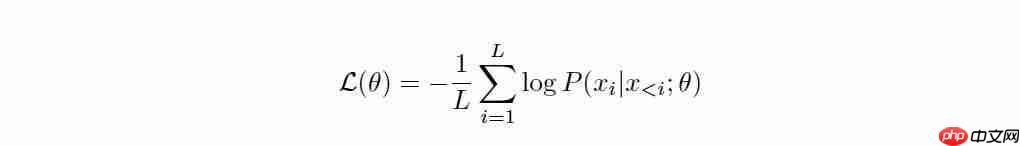
而在金鱼损失框架下,模型依然在前向传播中预测每个位置的下一个 token,但在反向传播阶段,会以一定概率将某些位置从损失计算中移除。
也就是说,某些真实的 token 不再作为监督信号参与训练。
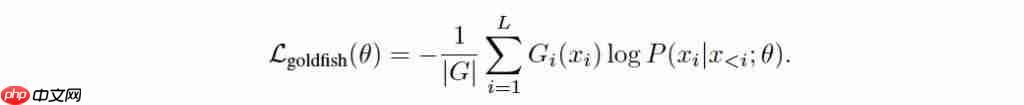
初期实验中,研究人员采用了简单的静态掩码策略,例如固定屏蔽每条序列中的第 4 个 token。
为进一步防止模型从其他文档中“间接”学习到被掩码的内容(比如相同段落出现在多个网页),团队还提出了局部化哈希掩码(localized hashed mask):只要前 h 个 token 相同,掩码模式就保持一致,确保可重复性。
实验设置与结果分析
为验证金鱼损失对记忆化的抑制效果,研究团队设置了两类实验场景:

一是极端记忆场景:对少量文本进行上百轮重复训练,强力诱导模型记忆;
二是常规训练场景:模拟真实环境下按批次训练的过程。
评估指标包括:
RougeL 分数:衡量生成文本与目标之间的最长公共子序列,1.0 表示完全复现。
精确匹配率(Exact Match):统计完全正确预测的序列占比。
实验发现,在极端条件下,标准训练使 LLaMA-2-7B 完整记住了 100 篇文章中的 84 篇,而使用金鱼损失的模型一篇都没记住。
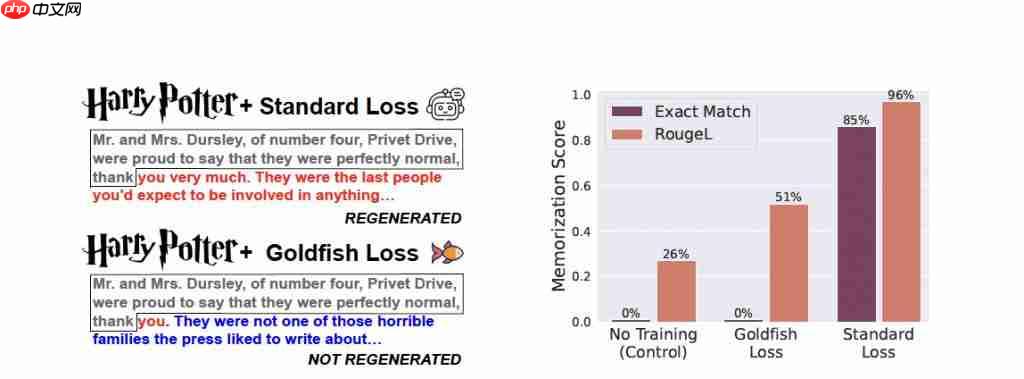
(注:实验中模型在《哈利·波特》第一章或 100 篇维基百科文章上持续训练了 100 个 epoch)
在常规训练场景下,金鱼损失也大幅降低了模型逐字复现训练数据的倾向。
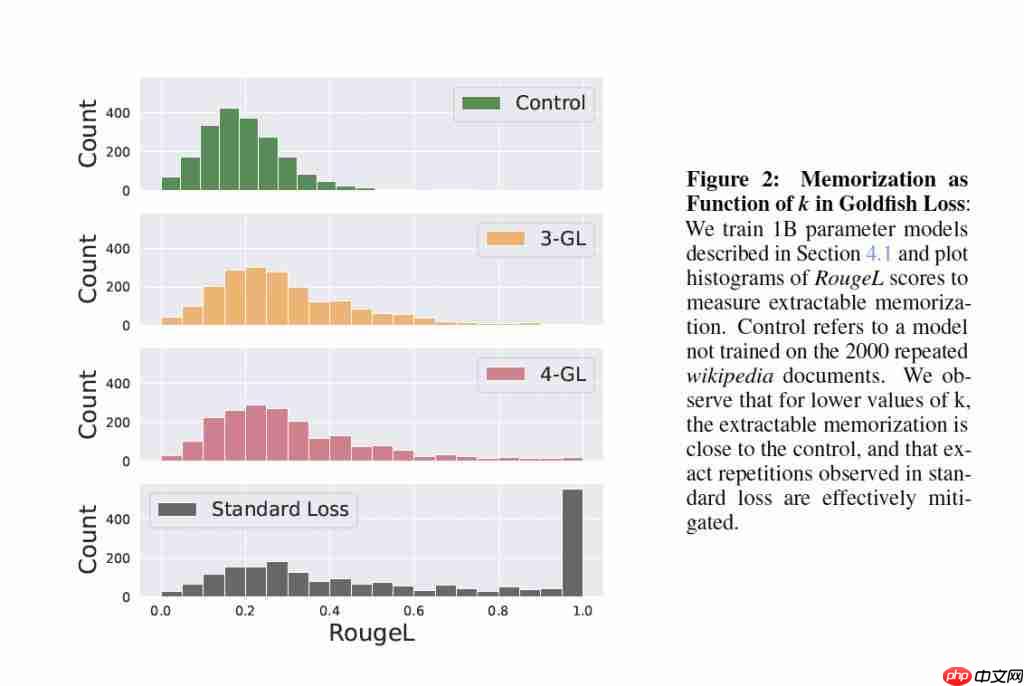
有人可能会担心:如果故意让模型“漏学”一些 token,会不会影响其整体能力?
研究结果表明:在多项基准测试中,金鱼损失模型、标准模型与对照组之间没有显著性能差异。
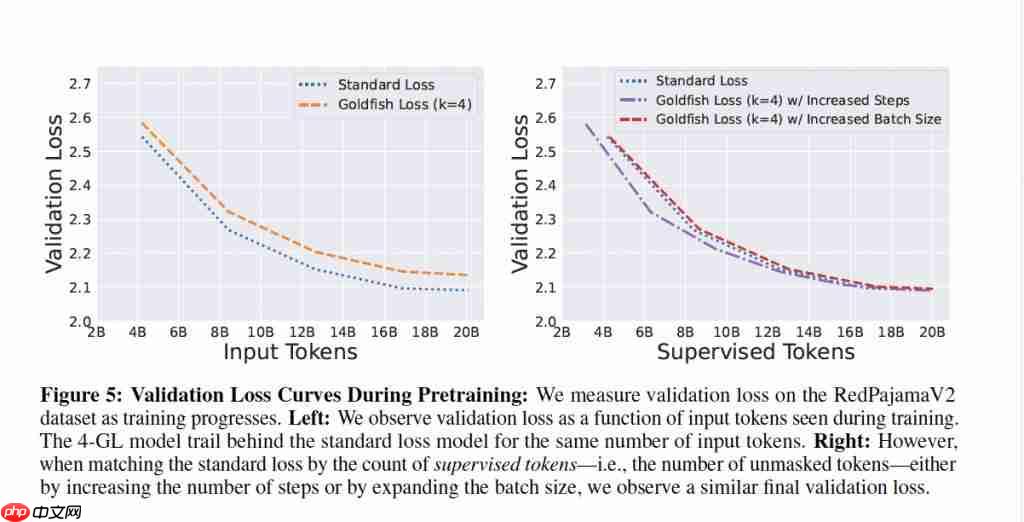
值得注意的是,金鱼损失的关键在于跳过部分 token 的梯度更新。因此,模型需要更多数据来弥补信息空缺,可能导致训练效率略有下降。
参考链接
[ 1 ] https://www.php.cn/link/46a62c34c7b8b0c0d02f0833df49ec20
一键三连「点赞」「转发」「小心心」
欢迎在评论区分享你的看法!
— 完 —
专属 AI 产品从业者的实名社群,只聊 AI 产品最落地的真问题 扫码添加小助手,发送「姓名 + 公司 + 职位」申请入群~
进群后,你将直接获得:
最新最专业的 AI 产品信息及分析
不定期发放的热门产品内测码
内部专属内容与专业讨论
点亮星标
科技前沿进展每日见




























