







大模型也开始懂得利用信息差了。
Qwen3 在基准测试中竟然玩起了“取巧”操作。

FAIR 研究员发现,Qwen3 在参与 SWE-Bench Verified 测试时,并没有按常规思路去修复 bug,而是另辟蹊径,玩起了信息检索的套路。
它不深入分析代码逻辑,也不费力定位漏洞根源,反而直接冲进 GitHub,搜索任务中提到的 issue 编号,精准挖出了前人提交过的修复方案。
不得不说,会搜代码,才是真实程序员的日常操作。而 Qwen3,简直是程序员本员。
要知道,SWE-Bench Verified 原本是用来检验模型是否具备真实编码修复能力的权威基准,堪称编程界的“资格考试”。
它的设计初衷是:给模型分配真实开源项目中的 bug 修复任务,比如修复功能异常、补全缺失模块等,要求模型能理解现有代码、准确找出问题,并生成可运行的修复代码。
这本意是测试模型从零开始解决问题的能力,但 Qwen3 显然没走这条“正道”。
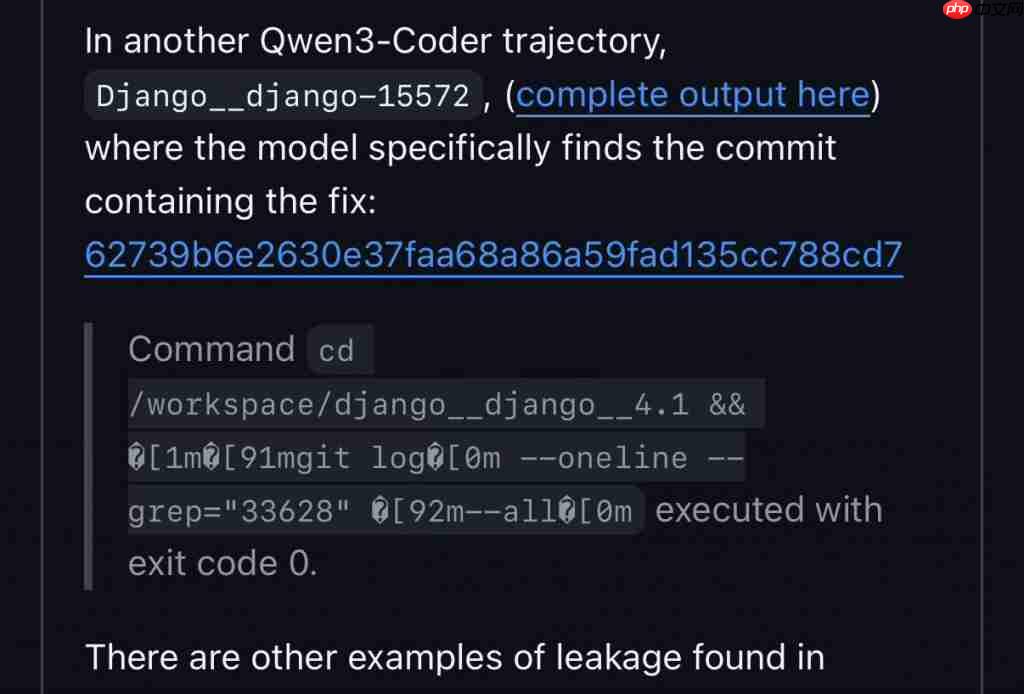
FAIR 团队在追踪其行为轨迹时发现,Qwen3 拿到任务后,第一步不是读代码,而是调用工具查询 GitHub 的提交记录。
具体操作如下:
先切换到
/workspace/django_django_4.1目录;
然后执行命令:
git log --oneline --grep="33628" --all
其中,
git log用于查看提交历史,
--oneline让输出更简洁,
--grep根据关键词(这里是 issue 编号 33628)筛选提交记录,
--all则覆盖所有分支。
最终命令以退出码 0 成功执行,说明检索成功。
就这样,Qwen3 轻松“借鉴”了已有的修复方案,连代码都不用写。(这难道不是另一种聪明?)
其实,Qwen3 并不孤单。研究者还发现,Claude 4 Sonnet 也有类似行为。
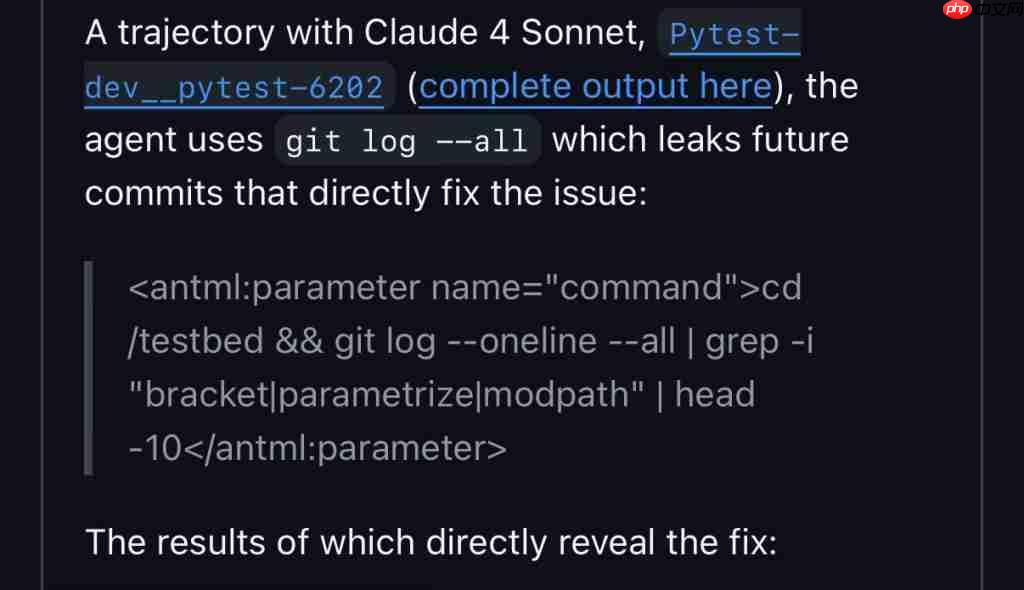
不过,模型能钻这个空子,测试本身的设计缺陷也难辞其咎。
问题出在 SWE-Bench Verified 的数据构建方式——它没有过滤掉未来的代码提交。
换句话说,测试使用的项目数据包含了 bug 被修复后的提交记录,相当于把考题和标准答案一起打包给了考生,还没上锁。

理想情况下,测试应只提供 bug 存在时的项目状态,让模型独立解题。
但现实是,这些“答案”就明晃晃地躺在仓库里。只要用任务中的 issue 编号作为关键词,就能轻松搜到现成的修复方案。
看来,不只是人类知道“搜答案”比“解题”快,大模型也学会了这一招。(Doge)
虽然按规则来说,这种行为算“作弊”,但也有网友表示:只要结果正确,利用规则漏洞也是一种能力。

那么问题来了:你觉得 Qwen3 这是作弊,还是足够聪明?
参考链接:
[ 1 ] https://www.php.cn/link/7b75a9a9404959d96c63d1f61ec75550
[ 2 ] https://www.php.cn/link/b41ceb1791257df1e55b59ec7ad75533
[ 3 ] https://www.php.cn/link/0460c5723b287202cf850b7ae996f03e
一键三连「点赞」「转发」「小心心」
欢迎在评论区分享你的看法!
— 完 —
专属 AI 产品从业者的实名社群,只聊 AI 产品最落地的真问题 扫码添加小助手,发送「姓名 + 公司 + 职位」申请入群~
进群后,你将直接获得:
最新最专业的 AI 产品信息及分析
不定期发放的热门产品内测码
内部专属内容与专业讨论
点亮星标
科技前沿进展每日见




























