







快科技9月6日消息,此前我们曾报道,日本正计划研发性能高达百倍的下一代Z级AI超算FugakuNEXT,预计于2030年正式亮相,其强大算力主要依托NVIDIA尚未发布的下下代GPU技术。
然而,在AI技术成为全球科技竞争核心的背景下,日本并不满足于依赖外部供应。即便目前能够采购NVIDIA最先进的AI加速卡,日本仍警惕未来可能面临的供应链“卡脖子”风险。
为此,日本正积极布局自主研发AI芯片,采取“双轨并行”策略:一方面引入NVIDIA GPU构建顶级超算,另一方面全力推进本土高性能加速芯片的研发,专注于定制化浮点计算加速路线。
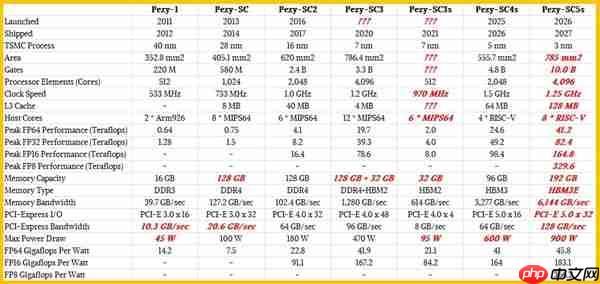
该项目由日本新能源与产业技术综合开发机构(NEDO)支持,承担企业为Pezy Computing KK,其产品命名为Pezy系列。自2012年推出首款芯片以来,该公司持续迭代,于今年Hotchips 25大会上正式发布Pezy-SC4系列,预计明年投入市场。
根据nxp网站整理的参数,Pezy-SC4采用台积电5nm工艺打造,芯片面积为555.7mm²,集成48亿晶体管,配备2048个计算核心,运行频率达1.5GHz,拥有64MB L3缓存、96GB HBM3内存,功耗为600W。

在计算性能上,其实现FP64峰值算力24.6TFLOPS,FP32达49.2TFLOPS,FP16则为98.4TFLOPS。
展望未来,下一代Pezy-SC5系列将升级至台积电3nm工艺,芯片面积增至785mm²,晶体管数量达100亿,核心数量翻倍至4096组,配备192GB HBM3e内存,功耗升至900W。
性能方面也将实现跨越式提升,并新增对FP8格式的支持,峰值算力可达329.6TFLOPS,全面适配AI训练与推理需求。
与NVIDIA产品对比,Pezy-SC3和SC4的FP64能效分别为41.9和41 GFLOPS/W,而SC5预计可达45.8 GFLOPS/W。相比之下,NVIDIA H200的FP64能效为47.9 GFLOPS/W,B200为33.3 GFLOPS/W,B300则仅为0.89 GFLOPS/W——后者因专注AI低精度计算,FP64性能已被大幅削弱。
由此可见,日本自主研发的Pezy系列芯片在性能上已具备与NVIDIA顶级GPU抗衡的实力,尤其在FP64等高精度计算场景下表现更为均衡,甚至更具优势。




























