
上海人工智能实验室(上海ai实验室)近日宣布,正式开源书生大模型新一代训练引擎 xtuner v1。
据悉,XTuner V1 是在“通专融合”技术路线不断推进以及书生大模型研发实践的深入过程中逐步发展而成的新一代训练框架。相比传统的 3D 并行训练方案,XTuner V1 在应对复杂训练场景方面表现更优,训练效率显著提升,尤其在超大规模稀疏混合专家(MoE)模型的训练中展现出突出优势。

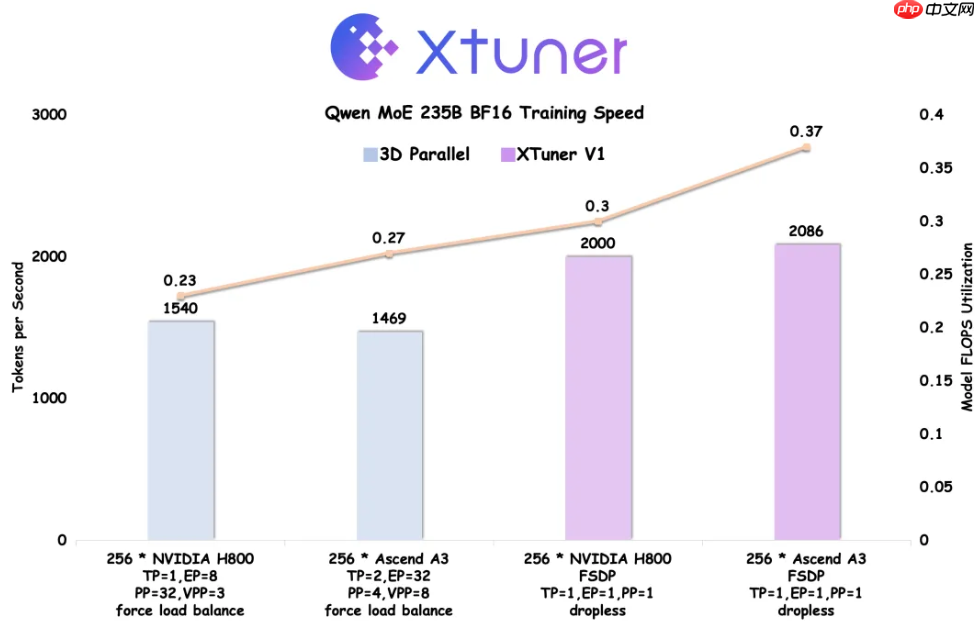
该训练引擎基于 PyTorch FSDP 构建,并针对 FSDP 存在的通信开销大等固有问题进行了多项优化,能够支持高达 1T 参数规模的 MoE 模型训练。更值得一提的是,XTuner V1 首次在参数量超过 200B 的混合专家模型上,实现了训练吞吐率超越传统 3D 并行方案。
为满足当前主流 MoE 模型后训练的需求,XTuner V1 实现了无需序列并行即可在单次 forward-backward 中处理长达 64k 的序列,更加适配强化学习等长序列训练任务;同时对专家并行的依赖较低,在长序列训练中受专家负载不均的影响更小——200B 级别的 MoE 模型无需专家并行,600B 模型仅需节点内专家并行,契合现代 MoE Dropless 训练范式;在大规模混合长短序列训练场景下,性能提升超过 2 倍,且数据并行更加均衡,有效缓解因序列长度差异带来的计算空转问题。
为进一步释放 XTuner V1 的性能潜力,研究团队联合华为昇腾技术团队,在 Ascend A3 NPU 超节点上开展了深度协同优化,充分调用超节点硬件资源,显著提升了 MFU(Model FLOPS Utilization,模型浮点运算利用率)。
尽管 Ascend A3 在理论算力上比 NVIDIA H800 低约 20%,但通过系统级优化,最终实现了训练吞吐反超 H800 近 5%,MFU 更是高出 20% 以上。相关技术细节将通过即将发布的技术报告全面披露。
除核心训练框架外,书生大模型研发过程中所使用的 AIOps 工具 DeepTrace 与 ClusterX 也将同步开源,为大规模分布式训练提供从监控、调度到故障诊断的全链路支持。
以上就是上海 AI 实验室开源 XTuner V1 训练引擎的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 245
245



















