







阿里通义qwen团队近日推出了全新一代基础模型架构qwen3-next,并正式开源了基于此架构的qwen3-next-80b-a3b系列模型。

据悉,该架构在前代Qwen3的MoE结构基础上实现了多项关键升级,主要包括:
- 引入混合注意力机制
- 采用高稀疏度的MoE结构
- 集成多项有助于训练稳定的优化技术
- 加入提升推理效率的多token预测能力
Qwen3-Next被视为即将发布的Qwen3.5模型的前瞻版本,致力于增强大模型在超长上下文处理和大规模参数扩展下的训练与推理表现。这一新架构充分体现了未来大模型发展的两大核心方向:上下文长度扩展(Context Length Scaling)与总参数量扩展(Total Parameter Scaling)。
其核心模型结构为“Gated DeltaNet + Gated Attention”:
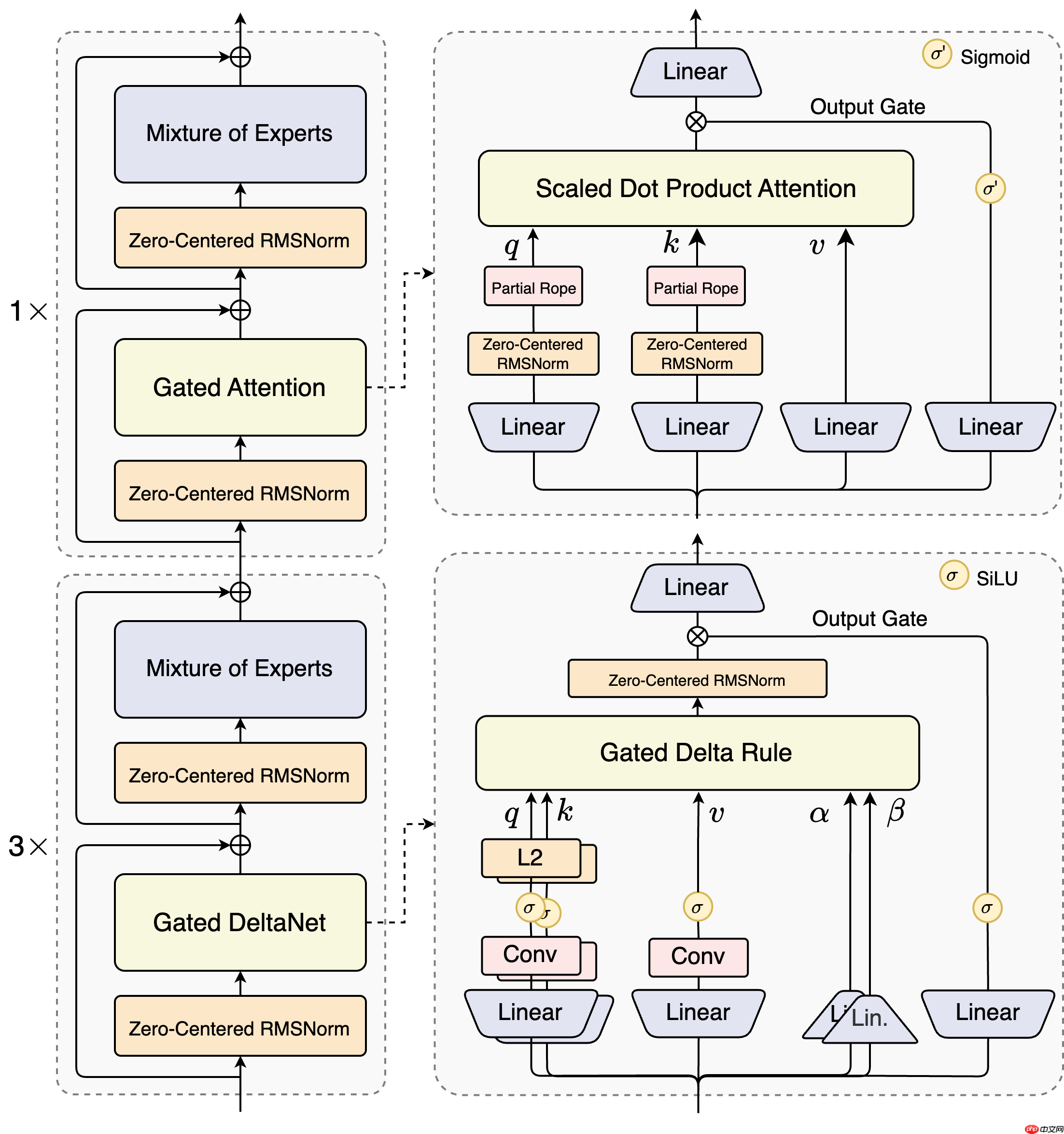

其中,Qwen3-Next-80B-A3B-Base模型具备800亿总参数,但每次推理仅激活约30亿参数,在性能上已达到甚至略微超越Qwen3-32B的dense模型水平,而训练成本却不到后者的十分之一。


快速体验入口:https://www.php.cn/link/6a12f708b55e1bfdd870fc3ed6292b1b
GitHub项目地址:https://www.php.cn/link/ee955e252af3c85e66e15864e31174fe
HuggingFace资源页:https://www.php.cn/link/ada67ce42f7e51433fdc45e523f90ff7
ModelScope魔搭平台:https://www.php.cn/link/66ecb6b5c02ae7cd2d14d4da82e54feb
阿里云百炼平台:https://www.php.cn/link/1f2733934120eee94d6f3a7df9ed85b1 搜索Qwen3-Next即可使用
源码下载地址:点击获取




























