







微软研究院近期推出了renderformer,这是一种全新的纯机器学习神经网络架构,致力于用ai模型彻底取代传统图形渲染中的计算流程,实现无需依赖光栅化或光线追踪技术的全功能3d渲染。


RenderFormer的核心结构包含以下关键设计:
- 双分支Transformer架构:系统分为两个阶段——视角无关(View-Independent)与视角相关(View-Dependent)。前者利用自注意力机制提取如阴影、漫反射等不随观察角度变化的全局光照特征;后者则通过交叉注意力机制处理可见性、镜面反射等依赖视角的视觉效果。
- 基于3D几何的相对位置编码:引入改进版旋转位置编码(RoPE),直接依据三角形在三维空间中的实际坐标进行编码,而非依赖序列顺序,从而确保模型对场景平移具有不变性。
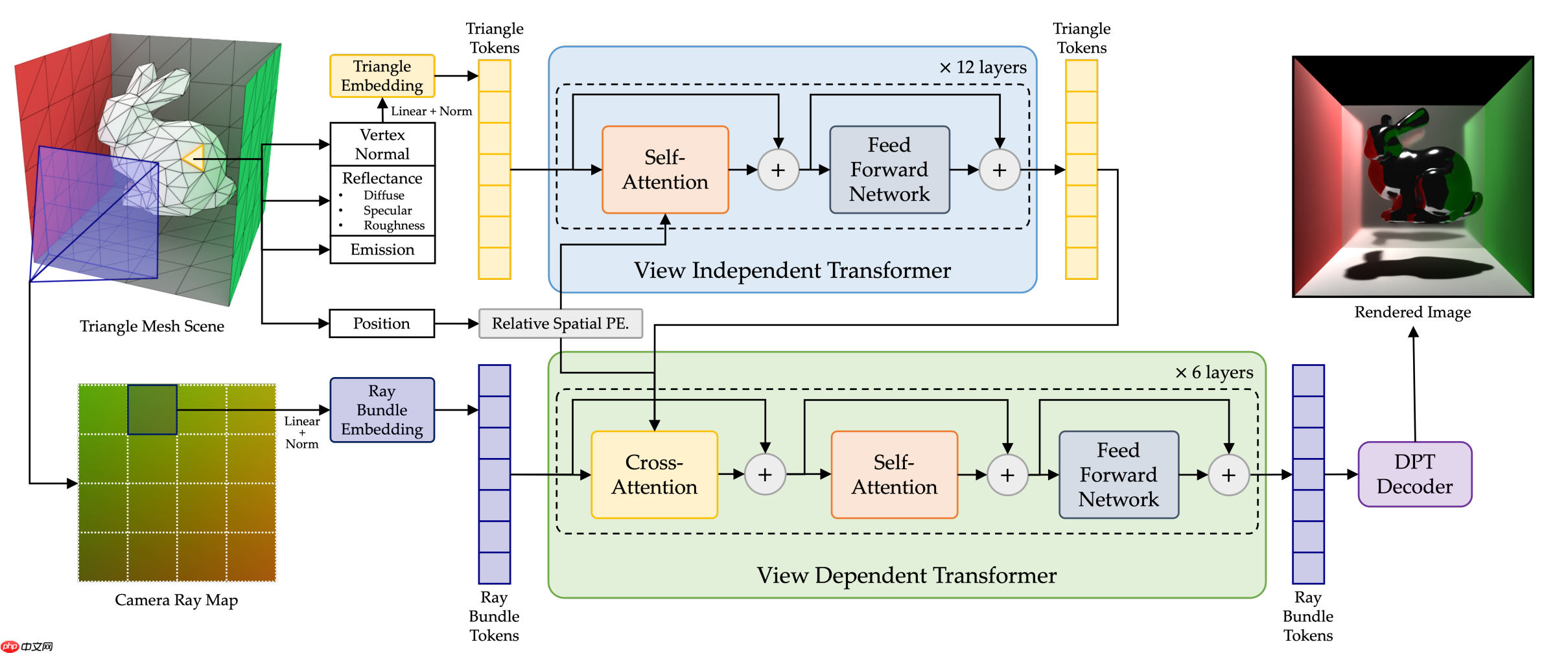

据项目介绍,RenderFormer是首个成功验证神经网络可完整学习传统图形渲染管线的模型。它能够处理任意复杂度的3D场景,并模拟多种全局光照现象。该模型以“三角形令牌”(triangle tokens)表示场景几何结构,包含位置、法线和材质信息,同时结合“光线束令牌”(ray bundle tokens)来建模观测视角,最终实现端到端的图像生成。此项研究已被SIGGRAPH 2025录用,并已公开代码与模型。




























