







在本文中,我们将探讨如何使用python中的pandas库将dataframe(以下简称df)数据转换为特定的格式,以便在前端的datatables中渲染。今天的重点是如何将df按行和按列进行转换。
目标
在网站开发过程中,经常需要将后端的Df数据转换成前端Datatables可识别的格式。这种格式通常是一个列表,其中每个元素是一个字典,字典的键对应前端表格的列名,值则对应表格的单元格值。以下是一个示例Df及其转换后的格式:
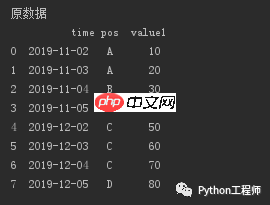
转换后的列表格式如下:
立即学习“Python免费学习笔记(深入)”;

代码
以下是实现上述转换的Python代码:
import pandas as pd
dict_1 = {"time": ["2019-11-02", "2019-11-03", "2019-11-04", "2019-11-05",
"2019-12-02", "2019-12-03", "2019-12-04", "2019-12-05"],
"pos": ["A", "A", "B", "B", "C", "C", "C", "D"],
"value1": [10, 20, 30, 40, 50, 60, 70, 80]}
df_1 = pd.DataFrame(dict_1, columns=["time", "pos", "value1"])
print("原数据", "\n", df_1, "\n")
print("\n按行输出")
list_fields = df_1.to_dict(orient='records')
print(list_fields)代码截图:
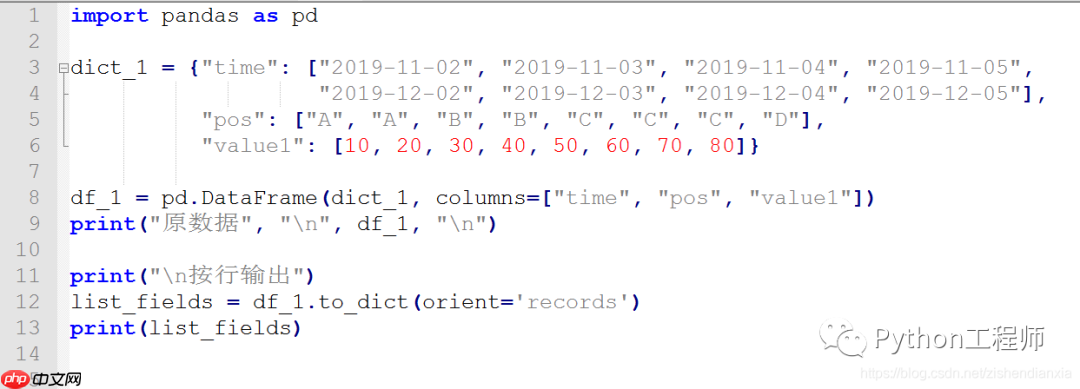

部分代码解读
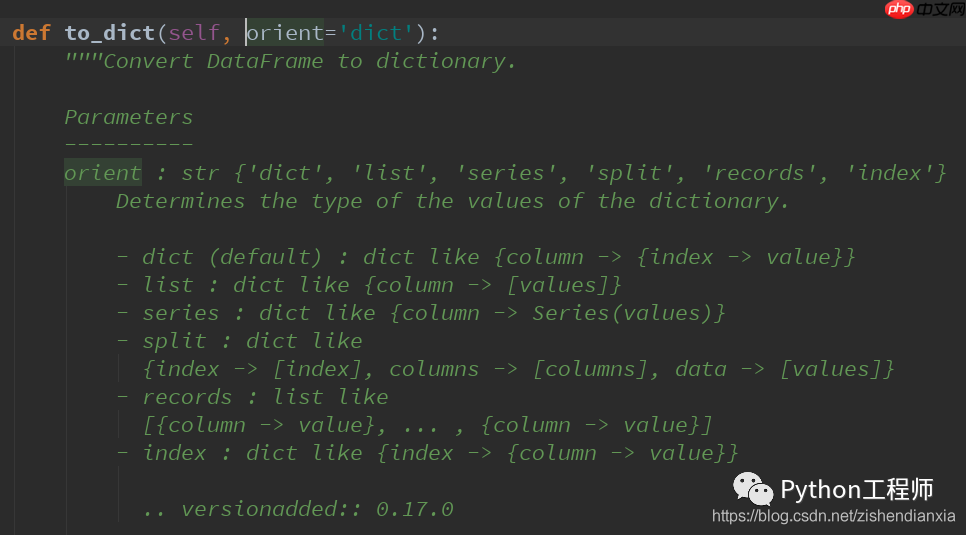
list_fields = df_1.to_dict(orient='records')这一行代码使用了
to_dict函数,其中
orient='records'参数表示按行输出。简单来说,
records表示记录,相当于数据库中的一行。
延伸
除了按行转换,pandas也支持按列转换。通过查阅
orient参数的可选值,发现
list可以满足按列转换的需求。按列转换的结果是一个字典,字典的键为列名,值为一个列表,该列表对应Df的一个列。以下是实现按列转换的代码:
dict_fields = df_1.to_dict(orient='list') print(dict_fields)
按列转换的代码截图:
按列转换的结果:





























